正しく動作するプログラムには
- 正しい/妥当なデータ
- 正しいコード
の両方が必要です。
仕様から間違っている場合を除けば、セキュリティ問題はプログラムの誤作動によって起こります。データかコード、どちらかの問題によって発生します。
当たり前の常識ですが、これを無視したセキュリティ対策がまかり通っている、それが現在の状況です。何故こうなってしまったのでしょう?
参考: プログラム動作の構造、原理と原則
https://blog.ohgaki.net/secure-coding-structure-principle
”全ての入力データのバリデーション”は当たり前の常識!?
まず前提として先に書いた通り、コンピュータプログラムは
- 正しい/妥当なデータ
- 正しいコード
の両方が揃っていないと、原理的に正しく動作しません。
※ 原理は原則/ベストプラクティスとは異り、ルールが変わらない限り変更できません。例)ニュートン力学は相対性理論や量子力学が適用される状況(=ルール)にならない限り変わらず適用される。
データには3つの種類があります。正しい/妥当なデータは水色の部分、それ以外の不正なデータが赤い部分です。
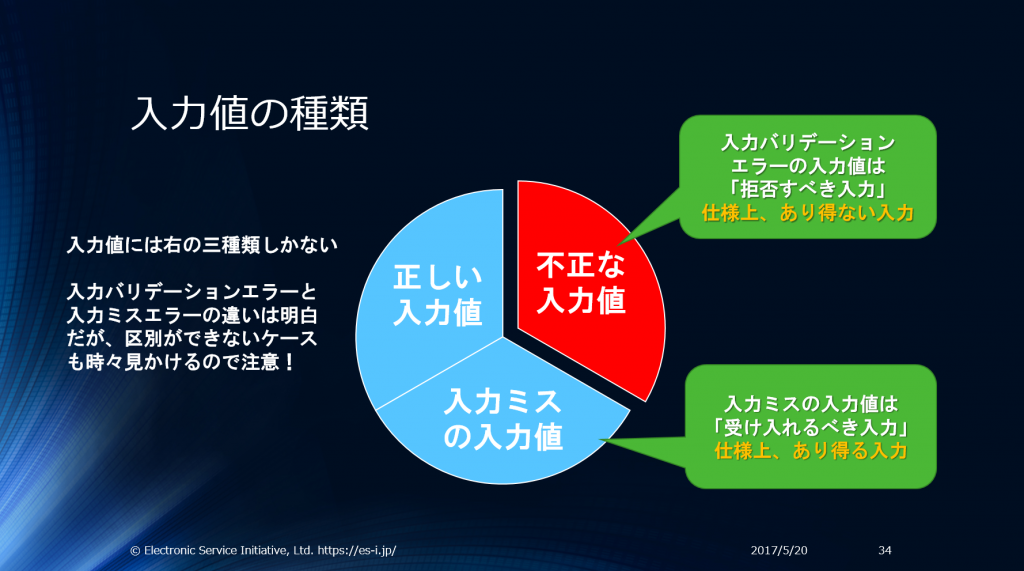
コードの正しさ以前に、正しい/妥当がデータでないとコードは絶対に正しく動作しません。致命的なセキュリティ問題となる攻撃のほとんどが
正しく動作しないデータ (≒ 不正な入力値 、妥当でない入力データ)
を利用して行われます。
強いデータ型を持つプログラミング言語で、コードが期待していないデータ型のデータを渡しても、絶対に正しく動作しません。
弱いデータ型を持つプログラミング言語でも、互換性があるデータ型とデータでないと正しく動作できません。
文字列型のデータに出鱈目なデータが入っていて、そのデータが保存できても、正しく動作している、とは言えません。
出鱈目なデータが入っている場合、どこかで誤作動するか、どこかで通常は発生しないエラーになります。直接/間接のインジェクション攻撃が可能になったり、データエラーが原因でDoS状態になったりします。
出鱈目な入力データの保存/出力時などにエラーが起きて保存できなくても、出鱈目なデータによって”遅すぎる時点”でエラーになっても、正しく動作している、とは言えません。
例えば、壊れた文字エンコーディングデータをブラウザに送信すると「真っ白(DoS状態)になる」場合があります。DoS状態になる出鱈目なHTMLデータを送って、正しく動作している、とは言えません。
ISO 27000のセキュリティ定義では、機密性/完全性/可用性/信頼性/真正性/責任追跡性がITセキュリティの要素です。出鱈目なデータではプログラムでは正しく動作せず、そのほとんどが”セキュリティ問題”としてカテゴライズされます。セキュリティ対策として、正しく動作しないデータはFail Fast原則 1 とホワイトリストで廃除します。2 3
入力データの妥当性検証はセキュアなアプリケーション開発に絶対に必要なセキュリティ要素であると言えます。本来ならFail Fast原則に基き一番にすべきセキュリティ対策です。
https://blog.ohgaki.net/there-are-3-types-of-validations
しかし、残念ながらWebアプリの入力データバリデーションは”かなりいい加減”です。
何が入っているのか分らないデータは”使う前”に必ず妥当性を検証する必要がある。
これが出来ていません。検証なし/不十分なデータ検証だとコードは正しく動作できません。”入力データを使う前”に検証しなかったり、検証していても不十分/不適切だと”いい加減”です。
何故、Webアプリの入力データバリデーションは”かなりいい加減”なのか?には幾つかの理由があるように見えます。
今と昔のネットワークプログラミングの違い
昔のネットワークアプリケーションのプログラミングは”専用”のプロトコルを使った開発でした。プロトコルには形式が決まっているバイナリ型プロトコルが使われていることが多く、テキスト型プロトコルの場合でも、データ型や構造型データも決まっていました。
プロトコルでのデータバリデーション、アプリケーションでのデータバリデーションで、ほぼ完全なデータバリデーションが行われていました。サーバー側(ホスト側)でバリデーションしていない場合でも、システムとしてデータバリデーションが完全に行われるように設計されていました。4
今はWebアプリケーションの時代になり”汎用”プロトコルであるHTTPプロトコルを使ってプログラミングします。HTTPは”汎用”のテキストベースプロトコルなので、全てのデータは”テキスト”で、パラメーターの種類/数/大きさ/含まれているデータのデータ型やデータ構造など、”汎用”で基本的に”無制限”です。5
しかもインターネットは閉じたネットワークではありません。汎用プロトコルであるHTTPを使って”攻撃者”が何を送ってくるのか、何を攻撃目標に攻撃してくるのか、誰にも予想できません。
”攻撃者”が何を送ってくるのか、何を攻撃目標に攻撃してくるのか、誰にも予想できない
これが次の誤解を生んだように思われます。
汎用プロトコルだからデータを制限できない、という誤解
HTTPが”汎用”プロトコルであっても、アプリケーションには”仕様”あります。ブラウザにも”仕様”があります。
HTTPが”汎用”で”無制限”であっても、”仕様”によってデータは制限されています。
これを無視した
汎用プロトコルだからデータを制限できない
とする誤解は何度も見かけました。
プログラムが正しく動作するには、”正しい(妥当な)データ”が必須条件であり”仕様”によって決まっているデータであることを検証しなければなりません。そして、汎用プロトコルだから制限/検証できない、とする考え方は大間違いです。
汎用プロトコルであっても、
- パラメーターの数が多過ぎない/少な過ぎない(多過ぎ/少なすぎ、は不正なデータ)
- パラメーターの大きさが大き過ぎない/小さ過ぎない(HTTPではパラメーターは文字列なので必ず長さがある)
- あるべきパラメーターがある/在ってはならないパラメーターがない
- データの形式が妥当
- パラメーター名の形式が妥当
こういったバリデーションができます。アプリケーションにもブラウザにも”仕様”があるので当然バリデーションできます。
汎用プロトコルだからデータを制限できない、という誤解が原理的に必須のデータ検証を行わなくなった原因の1つであることは間違いないでしょう。実際、ほとんど全てのWebアプリが、入力値全てをバリデーションしていません。
しかし、
汎用プロトコルだからデータを制限できない
は誤解であり、全てのデータには何らかのバリデーションが可能です。何故ならソフトウェアには仕様があり、ハードウェアのリソースは限られているからです。無制限、はあり得ません。
使っている物だけ検証すれば良い、とする誤解
「バリデーションできない」と勘違いしていなくても、
汎用プロトコルは何でも送れるので、使うパラメーター/データだけ検証しさえすれば良い
と誤解してしまったケースも少くないと思われます。
実際に使っているデータだけでも全てバリデーションしていればまだ良いのですが、HTTPヘッダーやクエリパラメーターは未検証のまま利用されている(=プログラムの内部に未検証のまま入ってしまう)ケースが多数あります。
最近の致命的セキュリティ問題となった物には以下のような事例があります。
「使っているデータだけ検証すればよい」はWebプログラミングでデータ検証が甘過ぎたり、データ検証がなかったりする原因になったと考えられます。そして上記のように実際に致命的なセキュリティ問題となってしまった事例は数えきれません。
きっちり作られたセキュリティガイドラインでは、パラメーターの過不足もチェックするように、と書かれています。多すぎるパラメーターを許すと攻撃を容易にし、問題の元となるからです。
例えば、企業内ネットワークでXXE(XML文書のExternal Entityを使った攻撃)などによるSSRF(サーバー・サイト・リクエスト・フォージェリ攻撃)が猛威をふるっています。しかし、余計なパラメーターをバリデーションしていれば結構効果がある緩和策になります。これをやっていないのでSSRF攻撃がかなり有効な攻撃手法になっています。
使わない余計なパラメーターでも、プロトコル仕様やアプリケーション仕様によってバリデーションすることが可能です。プロトコル仕様やアプリケーション仕様に合わないデータがあるとすれば、それは無効なデータであり受け入れるべきではありません。
プログラムは妥当なデータしか正しく動作しません。正しく動作しない余計なデータを許可する意味はないどころか、有害で攻撃可能な脆弱性を生む原因になっています。
XXEとSSRFといってもあまり身近に感じられないかも知れません。
使っているデータだけ検証すればよい
この誤解の身近な例はRailsのマスアサイメント脆弱性でしょう。GitHubのアカウントが不正利用仕放題になった、あの脆弱性です。
このマスアサイメント攻撃は、GitHub開発者が使っているデータだけ検証すれば安全!と誤解していた為、不正に管理者権限を取得できてしまう問題を生んでしまいました。悪しき先例として「PHPのグローバル変数改ざん攻撃」があったにも関わらずにです。
Railsのマスアサイメント脆弱性により「使っているデータだけ検証すればよい」とする考え方が脆弱である、と開発者の認識が軌道修正できれば良かったのですが未だにこの誤解が十分に解けていないように感じます。
防御的プログラミングの「フェイルセーフ」が第一のセキュリティ対策だ、とする誤解
ソフトウェアセキュリティの必要性が広く認識された90年代初めから防御的プログラミングが提唱されました。
昔のプログラムは色んな意味で脆弱でしたが少なくとも、
全ての入力データは検証するモノである
もしくは
データ送信する側が検証済みの妥当なデータを送ってくるモノである
という認識は開発者の共通認識だったと思います。
入力データが出鱈目だと、プログラムが原理的に正しく動作しないので当然の認識だと言えます。データの妥当性を自分のコードで保証はしていなくても、データの妥当性は重要である、と少なくともほとんどの開発者が理解していたと思います。
ソフトウェアに対する攻撃は多岐に渡りますが、90年代はCプログラムのメモリ管理問題に対する攻撃が主たる攻撃でした。バリデーション済みのデータであっても、完全にメモリ管理問題を解決するのは非常に困難です。場合によってはメモリ割当時にしか対策できない事もあります。
入力データ検証は防御的プログラミングでも第一にすべきセキュリティ対策です。しかし、同時にメモリ管理問題による攻撃を緩和する為に
「”防御的”にフェイルセーフ対策となるメモリ割当時のデータ検証」を導入することが当たり前
になりました。そして、この対策は「フェイルセーフ対策」failsafeである、という事実がいつの間にか忘れられます。
「結局、脆弱性は問題が発生する箇所で対策するしか防御できない」
このような議論を耳にしたことがある開発者が多いと思います。これはメモリ管理問題への攻撃を完全に対策するには、結局メモリを管理しているその場所(コード)でも「フェイルセーフ対策」をしないと問題全ては解決することはできない、とする議論(のはず)でした。
入力データ検証は要らない、とかセキュリティ対策ではない、とする議論ではなかった(はず)ですが、いつの間にか独り歩きしていったように思います。
フェイルセーフ対策こそが真のセキュリティ対策
とする誤解はとても多いです。セキュリティは多層防御で守る物なので、フェイルセーフ対策も必要かつ重要な対策です。しかし、
フェイルセーフ対策だけではマトモなセキュリティ対策にならない
という事実が正しく理解されず、
フェイルセーフ対策こそが真のセキュリティ対策
とする誤解は世界中に広がっています。フェイルセーフ対策だけでは不十分なセキュリティ対策である、と容易に論理的な説明が可能ですが、なかなか理解が進んでいないのが現状です。
フェイルセーフ対策こそが真のセキュリティ対策
としていた脆弱性研究家が少なくないように思います。
この考え方は非常に危険です。
例えば、SQL出力時のSQLインジェクション対策は出力処理として、必須の対策が半分、フェイルセーフ対策が半分です。自由に設定可能な入力データの場合は必須の対策です。数値や英数字のみが仕様のデータの場合はフェイルセーフ対策です。
出鱈目なデータも出力してしまう仕様(=フェイルセーフ対策に頼る仕様)はセキュリティ問題を複雑にするだけで、本当の解決策ではありません。
例えば、文字エンコーディングのセキュリティ対策で「フェイルセーフ対策に頼る」考え方を適用すると簡単に破綻します。iPhoneが頻繁に特定文字でクラッシュしたりフリーズしたりする問題が繰り返されるのは、文字エンコーディングの取り扱いに根本的な問題があるからだと思われます。
データをサニタイズ(ダメな形式から扱える形式に変換)すれば良い、とする誤解
プログラムの内部に入ってしまったダメなデータ(無効なデータ)をそのまま使おうとすると、何をやっても正しく動作しません。エラーにしてもダメです。
であれば、ということでサニタイズ(ダメな形式から扱える形式に変換)に頼るフレームワークやアプリケーションが少くありません。
- 無効な数値データが送られてきたらデフォルト値に変換する
- 文字列に無効な文字が含まれていたら、削除したり別の文字に変換する
こういったサニタイズ処理に頼り、不正なデータを無視する仕様のソフトウェアが少なくありません。入力データ検証なしでプログラムの中に入ってしまったデータをエラーにしてしまうと問題となってしまうので、こういった仕様にしてしまっているのだと思われます。
個人的にも「攻撃を無視して動作する」仕様は「仕様として問題がある」と感じていました。こういった「サニタイズに頼るセキュリティ仕様」はOWASPによって「脆弱なアプリケーション仕様である」とされてしまいました。
https://blog.ohgaki.net/2017-owasp-top-10-changes-web-security-rule
現在のOWASP TOP 10のA10では「攻撃者(脆弱性検査業者含む)が送信してくるような無効なリクエストに対し、検出&防止&対応できないアプリケーションは脆弱であるとしています。サニタイズでは脆弱なアプリになります。
これからは
「サニタイズに頼るセキュリティ」はセキュリティではない、誤解だった
とするしかありません。少なくとも、要求仕様としてOWASPのセキュリティガイドライン遵守がある場合は
「サニタイズに頼るセキュリティ」はセキュリティではない
として対処しないと脆弱なアプリになってしまいます。PCIDSSはOWASPのセキュリティガイドラインを遵守するように要求しています。CPIDSS準拠が求められるアプリケーションなら、誰がどう見てもサニタイズに頼るアプリケーションは脆弱です。
※ ISO 27000 (ISO 17799)は2000年から少なくとも入力バリデーションだけはキッチリ実施するように要求しています。ISO的には2000年から脆弱なアプリケーションである、となります。
出来の悪いセキュリティガイドライン、による誤解
セキュリティ専門家が作ったセキュリティガイドラインからして訳の解らないアドバイスをしているケースがあります。これについては以下のブログで詳しく書いています。
https://blog.ohgaki.net/ipa-must-admit-wrong-secure-programming-guide
読むと、これは酷い、と思うはずです。長くなるのでここでは詳しく紹介しません。「入力データ処理」なのに「出力データ処理」の話が書いてあります。一言で言うと”基礎の基礎から出鱈目”です。
このような内容のガイドライン/アドバイスでは、開発者が正しく入力データバリデーションとは何なのか?何処で何をすれば良いのか?勘違いしても仕方ありません。
まとめ
コンピュータープログラムが正しく動作する為の必須要件である「正しい(妥当な)データであることの検証」が無視されている、と言っても構わないような状態になっています。特に21世紀に入ってから状況がどんどん悪化していったように感じます。
入力データ検証はセキュリティ対策ではない、重要ではない
とするとんでもない誤解が解消するだけでもソフトウェア、特にアプリケーション、のセキュリティ状態は著しく改善します。
※ ライブラリレベルのソフトウェアの場合、厳格な入力データ検証は必須ではありません。ライブラリレベルでは、そもそも正しい/妥当なデータであることを”呼び出す側”が保証すべきだからです。
多層防御の最初の防御、アプリケーションレベルの入力データ検証、が不十分だったり、無かったりするのでアプリケーションに攻撃可能な脆弱性が次々に見つかる、という状況です。(どうして次々に脆弱性が見つかってしまうのか?は形式的検証を知ると分かります)
不正なSQLを実行するタイプのSQLインジェクション対策は簡単かつ完全に対策できます、プリペアードクエリだけ使っていればOK!と勘違いしていなければ。
今でもSQLインジェクション脆弱性によるデータ漏洩が無くならない原因は以下の2つです。
- 入力データ検証はセキュリティ対策ではないとし、検証をしていない/十分にしていない
- その上で、プリペアードクエリだけ使っていればOKと勘違いしている
このような
不完全な状態でも大丈夫だ!
と力説するセキュリティ専門家も存在し、それを信じて誤解した開発者が簡単に防止できるはずのSQLインジェクション脆弱性を作り、その対策(?)として同じ専門家が仕組的に非効率なWAFを売り、脆弱性検査サービスも提供している、といった笑えないおかしな状態が続いています。6
少しでもこのおかしな状況を良くする為に、SQLインジェクション対策保証付きのソースコード検査サービスを提供する準備中です。SQLインジェクション対策はコードレベルで対策/検査すれば完全に対策可能です。
最後に、誤解がないように明確にしておきます。
フェイルセーフ対策も必要です。
ただし、コンピュータの動作原理、正しいデータとコードの両方が必要、を無視するアドバイスは言語道断です。原理から間違っている、つまり根本的に間違っています。基本は何事でも大切です。基本を無視したアドバイスは無視すべきです。
https://blog.ohgaki.net/code-and-data
https://blog.ohgaki.net/vulnerabilities-is-callers-responsibility
誤解を解く為にはどうすれば良いのか?
問題が大きすぎるので問題点の指摘ばかりになってしまいました。
それで結局どうすれば良いのか?
と疑問を持つと思います。原理から導き出された科学的な原則を”正しく”理解すれば、自分自身で問題も誤解も解けます。CERT Top 10 Secure Coding Practicesは信頼できるコンピューターサイエンティスト(米カーネギーメロン大学)が作った、正しく動作するプログラムを書くため原則です。
https://blog.ohgaki.net/cert-top-10-secure-coding-standard
誤った解釈をしているケースも少なからず見られます。CERTのセキュアコーディング原則をよく読み、誤解しないよう注意してください。ゼロトラスト、大切です。
-
- 失敗するモノはできる限り早く失敗させる原則。セキュリティ対策/品質管理対策の基本。 ↩
-
- ブラックリスト方式は脆弱な方式です。基本、使いません。「正しく動作しないデータはFail Fast原則で廃除」といっても、正しい/妥当なデータのみを受け入れること(ホワイトリスト方式)により、正しく動作しない不正なデータを廃除します。 ↩
-
- 閉じたネットワークだったので、クライアント(端末)側のバリデーションでも十分でした。昔のキャッシュカードはATMで暗証番号を確認していたりしていました。 ↩
-
- HTTPプロトコルにも形式(=仕様)があり、実際にはHTTPプロトコルの仕様だけでもセキュリティ対策として有用なバリデーションが可能です。 ↩
- ソースコードを検査するのはホワイトボックス型の検査、外部から無効なデータを送って検査をするのがブラックボックス型の検査です。どちらかが必要、という物ではなく得意不得意があり、できれば両方した方が良い検査です。どっちが先か?というと開発中でも利用できるソースコード検査/レビューが先でしょう。 ↩