セキュアコーディングの第1原則は「入力をバリデーションする」です。セキュアコーディングの第1原則はソフトウェアセキュリティの一丁目一番地と言えるセキュリティ対策です。
入力バリデーションを第一のセキュリティ対策としているガイドライン:
- CERT Top 10 Secure Coding Practices
- OWASP Secure Coding ‐ Quick Reference Guide
- CWE/SANS Top 25 Monster Mitigations
- IPA セキュアプログラミング講座(NEW 2017年~)
セキュアプログラミング/セキュアコーディングを要求するセキュリティ認証:
90年代初めからコンピューターサイエンティストのセキュリティ専門家は「入力バリデーション」が重要であるとしてきました。「入力バリデーション」は論理的にセキュアな構造のソフトウェアを作る為に欠かせない必須の要素だからです。防御的プログラミングから数えると四半世紀を越える月日が経っています。
しかし、残念ながらセキュアコーディングの第1原則の「入力バリデーション」は普及しているとは全く言えません。この状況には理由があります。
この状況に責任があるIPAは、IPAのセキュアプログラミング講座 1に基礎的な誤りがあったことを明示し、開発者に与えた誤解が正されるよう、最大限の努力をすべきでしょう。
IPAのあり得ないような基礎的誤りがどのような物だったか、ご覧ください。
追記: IPAは問題のページを更新/削除したようです。
入力バリデーションと国際情報セキュリティ標準/ガイドライン
まず簡単にセキュアコーディング/セキュアプログラミングの原則を何時から誰が推奨していたのか紹介します。
国際情報セキュリティ標準(ISO 27000/17799)は2000年からセキュアコーディングの第1原則(入力バリデーション)の実装方法を具体的に記述&要求していました。2013年の改定でセキュアプログラミング技術が体系化され普及したとし、セキュアプログラミング技術を採用する、とした簡潔な記述になりました。
OWASPをはじめセキュリティガイドラインを公開している複数のセキュリティ機関がセキュアコーディング第1原則の入力バリデーションを第一のセキュリティ対策、最も重要なセキュリティ対策として紹介しています。
にも関わらず、「まともな入力バリデーションを持ったアプリケーション」は日本のみでなく世界的に普及していません。海外の状況は詳しく分かりませんが、恐らく日本と似たような状況だったのでしょう。
ソフトウェアセキュリティの一丁目一番地、と言えるセキュリティ対策がほとんどアプリケーションで実施されていない、その最大の理由はズバリ・・・
セキュアコーディングが流行らない最大の原因は”セキュリティ専門家”の誤解にある
先に誤解しないように書いておきます。本物のソフトウェアセキュリティ専門家はそもそも誤解などしていません。ソフトウェアセキュリティが必要になったモリスワーム事件以降、90年代初めから論理的に妥当なセキュアコーディング(当時は防御的プログラミングと呼ばれる)を一貫して提唱しています。
国際情報セキュリティ標準(ISO 27000)やCERT、OWASP、SANS、MITREなどが公開している資料では、セキュアコーディングで最も重要なセキュリティ対策は「入力のバリデーション」と一貫しています。この事から本物のセキュリティ専門家が誤解していないことが明らかです。※ 例外はIPA
コンピュータプログラムは妥当な入力データでしか正しく処理できません。
コンピュータサイエンティストのセキュリティ専門家なら、プログラム実行の正しさの証明問題、を知っており証明する際には入力データが妥当であることが前提条件であることをよく知っています。コンピューターサイエンスとして半世紀も前から研究されているので知らないはずがありません。アラン・チューリングから数えると半世紀よりずっと前です。
問題の原因は”コンピューターの動作原理/ソフトウェアセキュリティの基礎知識がない”にも関わらず影響力が強い「セキュリティ専門家」と言われる人達の行動と勘違いです。
- セキュアコーディングを知らない、知るつもりがない
- ”セキュアコーディングではない設計”を”セキュアコーディング”だと勘違いしている
これらの事例を紹介する前に、本物のソフトウェアセキュリティ専門家であるコンピューターサイエンティストがなぜ「入力バリデーションを第一のセキュリティ対策としているのか」を簡単に解説します。
原理:正しくプログラムを実行するには、コードが正しく処理できるデータが必須である
セキュアコーディングは「コードが確実に正しく動作するように書く」を実現することを目的にしています。”モグラ叩き的”に「脆弱性を作らないように書く」はセキュアコーディングではありません。
「脆弱性を作らないように書く」は悪いモノを定義し禁止するブラックリスト型の対策で仕組み的に脆弱です。
「コードが確実に正しく動作するように書く」は良いモノを定義し許可するホワイトリスト型の対策です。「脆弱性を作らないように書く」ブラックリスト型対策とは比較にならないほど堅牢です。
脆弱性を利用した攻撃はプログラムが意図しないデータ(≒不正な入力)を与えて誤作動させることで行われます。そもそもプログラムが意図しない不正なデータを受け入れなければ(ホワイトリスト型のセキュリティであれば)攻撃そのものが不可能となるケースが多数あります。
「正しく動作するソフトウェア」⇒「脆弱性がないソフトウェア」(p ⇒ q)
これの必須必要条件が「妥当な入力(正しい入力+入力ミス)であることを保証する入力バリデーション」です。原理的に「数値+”他の何か”では加算は無理」なのです。
コンピュータの動作原理:妥当なデータでしか「正しく動作するソフトウェア」を作れない、は変えることが不可能な動作原理です。
コンピューターは妥当なデータでないと整数でさえ正しく取り扱えません。これを知らないとロケットでさえ爆発します。より複雑な文字列の場合、未検証のデータは「ちょっとしたミス」でありとあらゆる問題の原因になります。2
単純な形式のデータであれば、厳格なバリデーションを行うと、ほぼ全てのインジェクション攻撃を無効化/防止することも可能です。
参考:”形式的検証”と”組み合わせ爆発”から学ぶ入力バリデーション (組み合わせ爆発を知っていれば、入力バリデーションなしのソフトウェアセキュリティは”科学的”にあり得ない、と理解ります)
誤り:セキュアコーディングの知らない、知るつもりがない
この問題はかなり根が深いと思われます。一つ事例を紹介します。
2年ほど前に「IPAのセキュアプログラミング講座は、ISO 27000やCERTがいうセキュアプログラミング/セキュアコーディングではない。セキュアコーディング最大のセキュリティ対策である入力バリデーションがないセキュアコーディングはあり得ない」とする指摘するメールをIPAに送りました。
椅子から転げ落ちそうになる基本的な間違いだけ紹介します。
(IPAは”旧版を改訂しない”としていたのですが、改訂したようです。これで入力バリデーションはセキュリティ対策ではない、とかアプリ仕様だ、といったおかしな意見が無くなると良いですね)
第6章 入力対策
コマンド注入攻撃対策
(中略)コマンド注入攻撃のメカニズム
コマンド注入攻撃は、外部から取り込んだデータをコマンド文字列の一部に組み入れて、それをシェルに実行させる場面が狙われる。コマンド注入攻撃のメカニズム
図6-1: コマンド注入攻撃のメカニズム
例えば、次はsendmailコマンドを利用してメールを発信する例である。
例(Perlスクリプト)
$to_address = cgi->param{‘to_address’};
$message_file = “/app/data/0012.txt”;
system(“sendmail $to_address <$message_file”);(出所:旧 IPAセキュアプログラミング講座)

「入力対策」と題した章なのに、コマンドインジェクションの例としてsystem()が利用されています。system()のパラメーター処理はOSコマンド用の「出力対策」であり、「入力対策」ではありません。図を見ればWebアプリからの出力であることが明らかです。
※ 入力、出力は”主体”となる物、つまり自分が作っているソフトウェア、を基準にして決まります。この場合、Webアプリが主体です。入力、出力が入れ替わるようではマトモな仕様書は書けません。基本中の基本ですね。
「入力対策」と「出力対策」が入れ替わっている、基礎的な間違いがあります。このような基礎的誤りがあるガイドで「入力対策が第1原則」とする本来のセキュアプログラミングを学ぶのは困難でしょう。
基礎的な間違いはこれだけではありません。旧版IPAセキュアプログラミング講座では「入力バリデーション」を正しく解説していません。最初に入力対策として出力対策が記載されています。(入力対策として入出力を取り違えた解説が数ページ続き、入力対策の最後に割とまともな入力対策の解説があります)これでは「入力対策が第1原則」とする本来のセキュアプログラミングを学べるはずがありません。
参考:”形式的検証”と”組み合わせ爆発”から学ぶ入力バリデーション (科学的なセキュリティ対策は”正しさの検証”がベースになっています)
このようなガイドではISO 27000が要求する「セキュアプログラミング」とするのは、お粗末すぎる内容、と評価するのが妥当でしょう。
しばらくして、「確かにその通りなので現在のセキュアプログラミング講座は更新する」との旨の返信を頂きました。2016年になって誤りがあった旧セキュアプログラミング講座は更新され、現在はCERT Top 10 Secure Coding Practicesをベースにしたセキュアプログラミング講座に一新されています。3 旧版の削除は行われていません。
IT技術者であればよくご存じの通り、IPAは情報セキュリティ対策を啓蒙する日本政府の外郭団体にあたる独立行政法人です。国際情報セキュリティ標準であるISO 27000の策定にも関わっている権威あるIPAでさえ、2017年になるまでセキュアコーディングの第1原則の入力バリデーションをセキュリティ対策として広めていませんでした。
これは”セキュリティ専門家”が「セキュアコーディングを知らない、知るつもりがない」の典型的な例と言えるでしょう。
「セキュアコーディングを知らない、知るつもりがない」”セキュリティ専門家”が根本的に間違ったセキュアプログラミングを啓蒙していた状況は笑えない状況である、とすることには騙されてしまった多くの開発者に同意頂けると思います。開発者の方々においては単なる同意ではなく、怒りを持たれたとしても仕方ないでしょう。開発を依頼するユーザーやエンドユーザーも同じでしょう。
※ IPAの標準規格を策定する部署と国内向けに情報セキュリティ対策啓蒙する部署は異なると聞いています。標準規格を策定しているセキュリティ専門家まで知らなかった、知るつもりがなかった、はさすがに無いはずです。ISO 27000には入力バリデーションの実装方法が詳しく記載されていましたし、2013年改訂版では「セキュアプログラミング技術の体系化が進み広く普及した」として実装方法が省略され「セキュアプログラミング技術を採用する」と簡略したのですから。であるからこそ、明らかに間違ったセキュアプログラミング、を啓蒙していたIPAの関連部署およびその関係者の責任はより大きいと言わざるを得ないです。
誤り:”セキュアコーディングではない設計”を”セキュアコーディング”だと勘違いしている
備考: ブログを書いている時にPHPカンファレンス2017のスライドと別スライドを見間違えていました。両方のスライドを使うように修正しました。
次のスライドはタイトル通り、セキュアコーディングの解説です。ただし、”独自解釈のセキュアコーディング”で、ISO27000やPCI CSSが要求するCERTのセキュアコーディングとは別物です。
既に記載の通り、セキュアコーディングの第一の原則は、信頼境界で入力をバリデーションする、です。第七の原則(IPA版は第二の原則)は、出力を無害化する、です。ISO 27000(ISO 17799)は2000年から10年以上に渡ってセキュアコーディングの第1原則の実装と管理方法を具体的に記載してきました。これを前提に次の講演資料をご覧ください。
http://www.slideshare.net/ockeghem/reconstruction-of-secure-coding-methodologies
専門家でも「セキュアコーディングの知らない、知るつもりがない」が分かる良い事例です。そもそもセキュアコーディング(セキュアプログラミング)ではないので、多くは解説しません。
p.13のスライドでは入力バリデーションが「わかりません」としています。旧 IPAセキュアプログラミング講座には適切な解説がないので仕方ないかも知れませんが、セキュリティ専門家ならCERT Secure Coding Practices (セキュアプログラミング/セキュアコーディング原則)くらいは知っていて当然です。
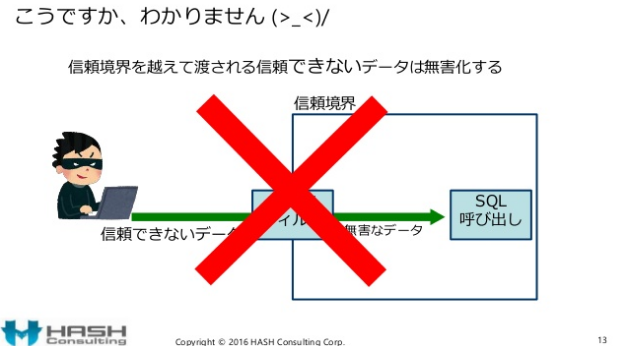
解らなくて当たり前です。セキュアコーディングの原則では、信頼境界を越えてくるデータ(入力)は「無害化」するのではなく「検証(バリデーション)」します。「無害化」するのは出力です。(※ 同じ間違いがIPAセキュアプログラミング改訂後にもある)
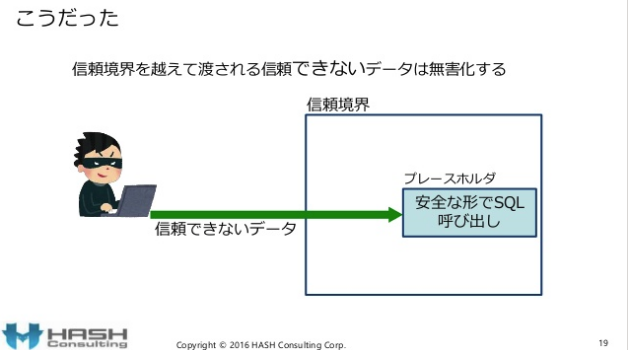
間違いが多過ぎて一つ一つ解説するとキリがありません。セキュアコーディング原則1の入力バリデーションがありません。出力の無害化”だけ”ではセキュアコーディングではありません。
CERTセキュアコーディングは
- 入力バリデーション(原則1)
- ”セキュアコーディング標準”による安全なロジック処理(+具体的な入力/出力処理)※ 原則10 「セキュアコーディング標準を採用する」=自ら作るモノ
- 出力の無害化(原則7)※ IPA版は原則2
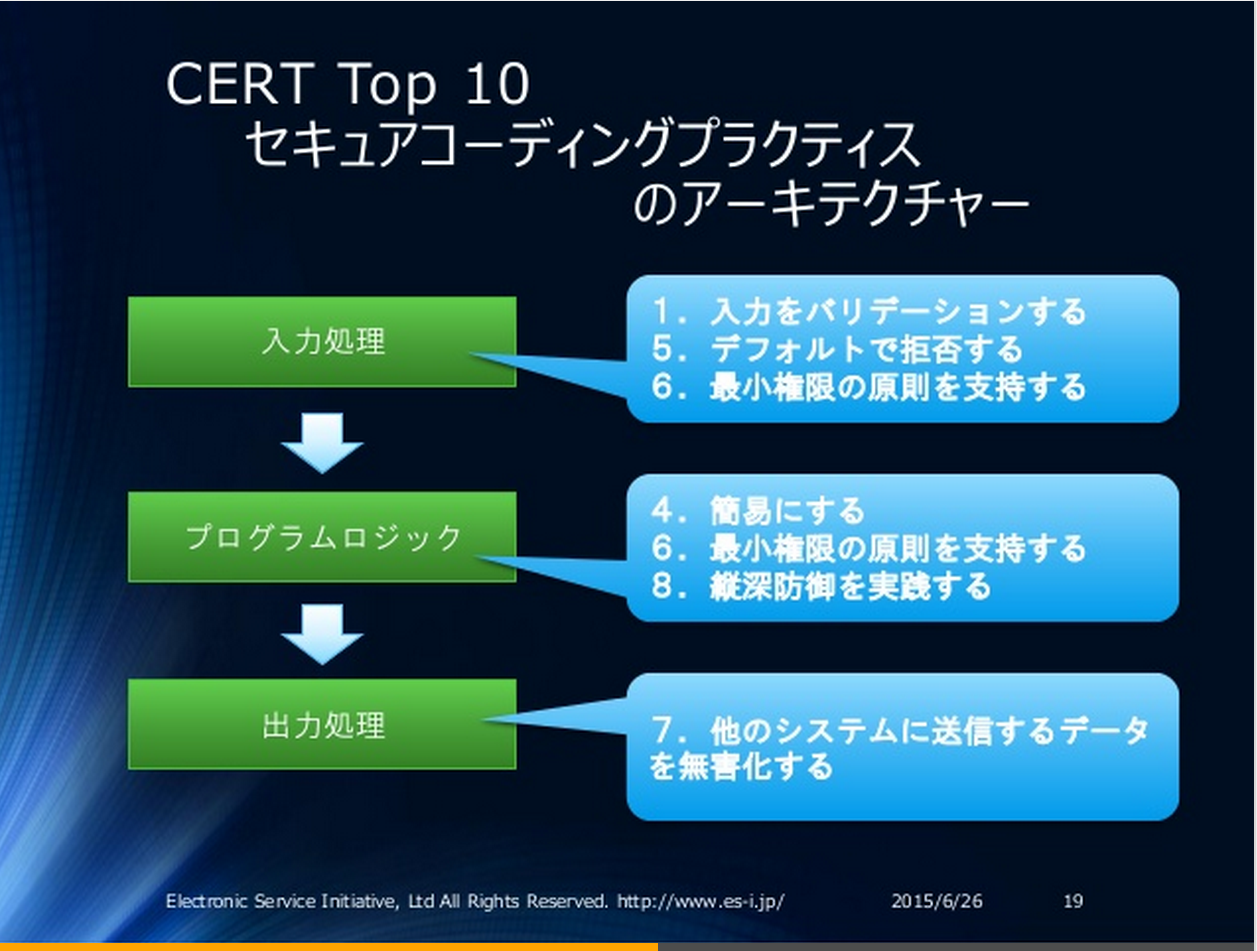
入力処理、ロジック処理、出力処理の3つが1つのセットとして成り立ちます。これ以外はセキュアコーディングではありません。
セキュアコーディング原則の第一原則を無視する、というよりはむしろ有害であるとしています。セキュアコーディングに準拠したコーディング/設計/構造とは全く言えません。
「セキュアコーディングの知らない、知るつもりがない」は、IPAが「根本的に間違ったセキュアセキュアプログラミング講座」を改訂した後も続いています。
PHPカンファレンス2017の講演資料ですが、セキュアコーディングの第一の原則は重要でない、とする内容になっています。これ以前のPHPカンファレンスでも同様の講演があったと承知していますが、これは「根本的に間違ったIPAセキュアセキュアプログラミング講座」が改訂された後の講演となります。
https://www.slideshare.net/ockeghem/php-conference-2017
一言でいうとこのスライドの内容はセキュアコーディングとしてお話しにならない。
「著名PHPアプリにOSSアプリに学ぶセキュアコーディング原則」と題しているにも関わらず、本家本元の「セキュアコーディング原則」の第1原則が出てきません。最後にやっと「バリデーションはしましょうね」だけです。
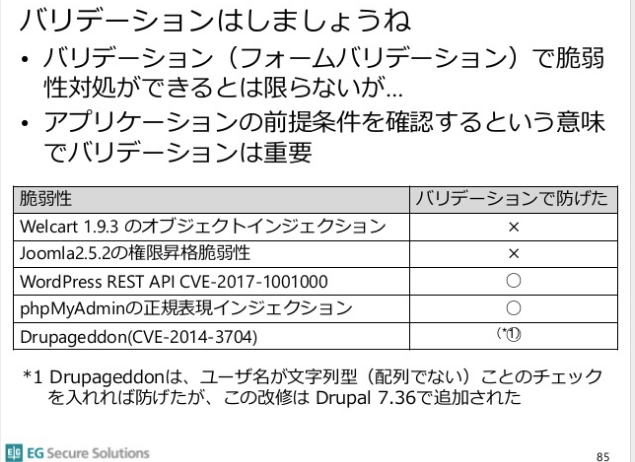
「入力バリデーションはしましょうね」ではなく、一番目にしなければならないセキュリティ対策です。入力と出力対策は独立した対策です。ロジックもロジックで別の役割を持っています。
スライド最後のこの表の意図は「入力バリデーションは結局役立たないことがあるので必要性は低い」でしょう。(重要と書いていても、入力バリデーションとは書いていない)入力バリデーションは入力データ形式の責任しか持ちません。それ以外は他の責任です。
p.85のスライドは入力対策は重要だが役立たない、と印象付ける物になっています。これは、出力対策だけでは”出鱈目なデータ出力可能”、だから出力対策は頼りにならない、と説明することと同じで不要な説明です。
セキュアコーディングはコンピュータープログラムが「原理的に正しく動作する」為には、まず「原理的に妥当なデータが必要である」ことに基づいています。入力バリデーションはロジック/出力ですべき対策まで責任を持ちません。
百歩譲って、ほぼ全てのWebアプリが十分な入力バリデーションをしているのであれば、これでも構わないと言えます。現実は正反対で、セキュアコーディング第1原則の「入力をバリデーションする」をまともに実装していません。
残念ながら、このスライドで紹介しているように著名OSSアプリ含め、現存するほぼ全てWebアプリケーションはセキュアコーディングの第1原則を実装せず、セキュアコーディングではありません。セキュアコーディングではない物から、セキュアコーディングを学ぶことはできません。赤信号をみんなで渡っているから大丈夫である、といった論理は通用しません。
セキュアコーディングではない物、が蔓延している状況はIPAを含め、”セキュリティ専門家”とされる人達が、コンピューターの動作原理を無視し、”誤ったメッセージを送り続けていること”が原因だと言えるでしょう。(海外では流石にセキュリティ専門家でなく著名開発者がおかしな設計を推進している)分かりやすいマッチポンプの構造
- セキュアコーディングでないモノを啓蒙 → セキュアコーディングでない実装が多数となる → セキュアコーディングでないモノがセキュアコーディングだとする
である、と見られても仕方ないです。
コンピュータの原理(妥当なデータでしか正しく動作しない)に基づかない、セキュアでないソフトウェアが増えて喜ぶのはサイバー犯罪者とセキュリティ業者だけです。被害者は開発者とユーザーです。
基礎を”間違えていました”と明示せず、新しい資料を公開するだけでよいのか?
セキュアコーディングが要求する基本的なソフトウェアセキュリティ設計、 信頼境界での入力バリデーション、がWebアプリで全くと言ってよいほど普及していない原因は、IPAや著名な”セキュリティ専門家”が公開している資料から明らです。
- ”セキュアコーディングではない設計”を”セキュアコーディング”だと勘違いしている
- +”本当のセキュアコーディングでないモノ”を”セキュアコーディング”だと啓蒙している
IPAは重大な誤りの訂正告知もなく、何も無かったようにCERT TOP 10 Secure Coding Praceticesを現在のセキュアプログラミング講座に載せています。
基礎中の基礎を間違えていたことは恥ずかしいことです。それは解りますが、その間違いを明示せず、単に新しく訂正したPDF資料を公開するだけ、でよいのでしょうか?しかも、新しい資料は検索されづらいPDF資料だけです。
お粗末もしくは入力検証の欠落で甚大な被害を発生させたWebアプリがどれだけあるでしょうか?例えば、東京都の納税サイトは「普通に入力検証」していれば数十万件もクレジットカード情報を盗まれませんでした。被害はこれだけではありません。細かい物を入れると数えきれないでしょう。
重大なセキュリティ問題の原因を作った間違いに知らんふりで構わないのでしょうか?
ソフトウェアセキュリティで最も重要かつ基礎的な対策を啓蒙しないどころか、間違った対策を啓蒙し、このために日本中で高リスクのWebアプリケーションが作られる原因を作ってしまった、とホームページで明確に記載すべきではないでしょうか?
出鱈目な旧版セキュアプログラミング講座は今もGoogle検索で上位に表示されます。「この旧版セキュアプログラミング講座は”セキュアプログラミングではありません。基礎的な間違いがあるためセキュアプログラミングになりまん。”」と全ての旧版ページに解りやすい注意書きを入れるべきではないでしょうか?
これらは公的機関の責務ではないでしょうか?明らかな大規模事例を含め、甚大な被害が出ている現実を見つめて欲しいです。
セキュアコーディングの話をすると、出鱈目な旧版セキュアプログラミング講座を引き合いに出して「本家CERTのセキュアコーディング概念で説明する大垣の話の方が間違っている」と反論されたものです。IPAが長らく公開していた出鱈目なセキュアプログラミング講座が原因で、今でも出鱈目なセキュアプログラミングを正しい、と信じている開発者は数えきれません。
「本来のセキュアコーディング」を理解すると、IPAや”セキュリティ専門家”が「信じられないような基礎的誤解」に基き、危険なソフトウェア設計/構造を安全であるように誤解させ、危険な設計/構造を推奨していたことが解ります。
少なくない”セキュリティ専門家”も同じように「国際標準やセキュリティガイドラインに準拠しない危険なコーディングをセキュアコーディングとしていた」ことをIT業界、特にWeb関連業界に身を置く方なら体感していると思います。とは言っても、この方々も”日本のITセキュリティの元締め”と言えるIPAが出鱈目なセキュアプログラミング講座を公開していた為に、誤解してしまった被害者の側面もあるでしょう。
国の組織の一部であるIPAには、組織として、この間違いを全力で正す責任があるのではないでしょうか?
この基礎的誤りを正さずに、IoTセキュリティ!東京オリンピックに向けてサイバーセキュリティ対策強化!などと言っている場合ではないでしょう。誤解させられた開発者によって脆弱なソフトウェアが今も作られています。
日本のITセキュリティの歴史に残る間違いが、今もあるべき形で訂正されていない、と言っても構わないのではないでしょうか?「重大な間違いがありました。古い物は無効/有害です。お手数ですが、正しいモノに差し替えてください」とすべきではないでしょうか。ソフトウェアのリリースノートにはこのように書くのが常識です。
まとめ
”セキュリティ専門家”から「セキュアコーディングとはこうだ」と説明されると、たとえそれが誤りであっても、普通は「そうなのだろう」と信じてしまいます。多くの一般開発者が「本当のセキュアコーディング」を知らず、ほぼすべてのアプリケーションがセキュアコーディングになっていないのも当然の結果です。
「入力バリデーション」が重要ではない、要らない、セキュリティ対策ではない、などと主張する人はコンピューターサイエンティスト/セキュリティ専門家として、どこからどう見ても、失格です。(失格の理由)
セキュアコーディングの基本概念さえ出鱈目、一体セキュリティの何を学んできたのか理解りません。この間違いは「ちょっと設計/実装を間違えた」といった間違いではなく、コンピューターの動作原理から間違い、基礎の基礎の間違いです。
セキュアコーディングの概念と論理は何十年も前から結論が判っていた事です。セキュアコーディングの概念通り作ると自然とセキュアなアーキテクチャーになります。アーキテクチャー(構造)がない出鱈目なセキュリティ対策の啓蒙でどれだけ多くの脆弱性/セキュリティ問題を開発者に造くらせてきたのか?を考えると、適切な責任の取り方を見せるべきである、と問われるのは当然でしょう。4
参考:セキュアなソフトウェアアーキテクチャーのイメージ図
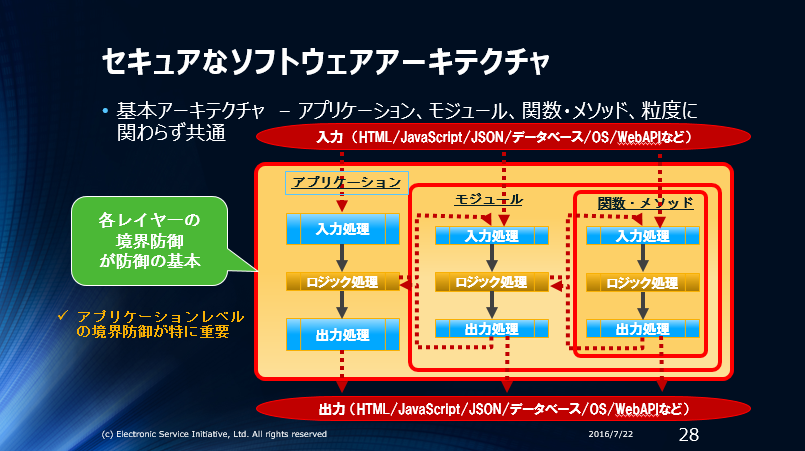
こんなブログを書くとまた”基礎”/”基本”を勘違いしている敵を増やすかも知れませんが、間違っている物は間違っています。曲がっていることが放置できない性分なので仕方ありません。間違っていると直接/間接に指摘している方々へは、正しくセキュリティの基礎概念をご理解頂き正しいセキュリティの基礎概念を啓蒙頂きたい、ということ以外に他意はありません。5
苦言ばかりでしたが、新IPAセキュアプログラミング講座の資料で、セキュアコーディング”習慣”をセキュアコーディング”原則”とした点は高く評価しています。
関係者の皆様におかれましては、過去の重大かつ基礎的な誤りを訂正し、セキュリティ専門家として失格とならぬよう、正しいセキュアコーディングの概念を強力に啓蒙いただけることを期待しています。
間違ったSQLインジェクション対策教育による初歩的なSQLインジェクション脆弱性が目につきます。SQLインジェクション対策にエスケープが要らないとする出鱈目な対策も合わせて修正されるように努力いただけると、多数のWebサイト開発者/利用者の幸せにつながると存じます。
最後に誤ったセキュアプログラミング概念の被害者といえる開発者の皆様は、IPAの過ちが原因で脆弱なシステムを作ってきた、と思います。旧セキュアプログラミング講座は2007年から10年以上「セキュアプログラミング」の資料として参照されてきました。開発者が誤解しても仕方ないでしょう。
良い機会なので(というより今しか機会がないので)「IPAの間違いのためにシステムの改修が必要になった」としてお客様に改修の提案をされることをお薦めします。提案だけでもしておくと、セキュアコーディング第1原則を実装していないことに対する訴訟リスクを回避/軽減できます。
追加の説明
長くなり過ぎたので省略しました。折角書いたので追加の説明として掲載しておきます。(全体で約1万5千文字、10倍にすれば一冊の本になります)
危険な環境の守り方
ソフトウェアの開発環境は、誰が書いたのか判らないコード、安全性が検証されていないコード、そもそも危険だと判っているコード、作りかけのコード、が実行される高リスクの環境です。
こういった環境の場合、ネットワーク的に外部からの攻撃がほぼ不可能であるように構成し、攻撃を検出して守る以外に良い方法はありません。こういった環境で利用されるプログラムでは些細なセキュリティ問題があるプログラムも、一般に公開するプログラムと異り、問題になりません。
開発環境と同様に、全てのソフトウェアにセキュアコーディングが必要だとも言えません。ライブラリでは「正しいデータが送られてくる」を前提として検証しない方が良いものさえあります。一般に公開するアプリケーションでは検証は省略できませんが、ソフトウェア開発環境のように管理された特別な環境では検証を省略したアプリケーションがあっても構いません。ソフトウェア開発環境に脆弱なアプリケーションがあっては困る、という場合は環境自体のセキュリティに改善の余地があります。
原則もあれば例外もある、TPOに合わせる、という単純な話です。
データ検証は必須
C言語などでは整数型(8、16、32、64ビット整数など)の入力でさえデータバリデーションをしないと、オーバー/アンダーフローしないこと保証できません。整数オーバーフローは時として予想外の攻撃を可能にします。例えば、MySQLでは符号付きchar型、符号なしchar型の違いにより管理者権限でのログインができてしまう問題がありました。
任意精度整数をサポートするRuby/Python3を使っているから整数オーバーフローなど関係ない!?と考えるかも知れませんが、それは間違いです。Ruby/Python3が利用するライブラリの多くはCやC++で記述されています。一般にCやC++の関数は、任意精度整数は使いません。ライブラリ内では64/32/16/8ビット整数を使い、さらに符号の有り無しがあります。
単純な整数型でさえ、オーバーフローにより不正な動作を起すことが可能です。より複雑な文字列型データの場合、データバリデーションを行わないとありとあらゆる脆弱性のリスクが生まれます。ロケットも爆発します。
セキュリティ対策とはリスク管理です。できる限り効率的かつ効果的にリスクを排除・削減することを目標にします。入力バリデーションは”プログラムが意図通り動作するために必須”であると同時に、”プログラマが予想していない脆弱性さえ排除・削減”できます。つまり「正しく動作」するソフトウェアには入力データバリデーションは欠かせないです。
入力バリデーションですべきこと
セキュアコーディング原則1では、全ての入力をホワイトリスト型でバリデーションする、ことが求められています。
※ バリデーションは3種類あります。ここでは詳しく説明しません。
先日リリースされた2017年版OWASP TOP 10がを例に、入力バリデーションで何をしなければならないのか紹介します。
2017年版OWASP TOP 10 A10はセキュアコーディング原則1を実装し
Establish effective monitoring and alerting such that suspicious
activities are detected and responded to in a timely fashion.
(疑わしい活動がタイムリーな形で検出され対応できる効果的なモニタリングと警告を確立する)
これができないシステムは脆弱なシステムである、としています。
検出すべき疑わしい活動には以下が含まれます。
• Penetration testing and scans by DAST tools (such as OWASP
ZAP) do not trigger alerts.
(OWASP ZAPなど、DASTツールによる侵入テストとスキャンが警告を発生させない)
※ OWASP ZAPはWebアプリに攻撃用の不正な入力を効率的に送信できる攻撃用プロキシアプリです。DAST – Dynamic Application Security Testing、動的アプリケーションセキュリティテスト
攻撃用の不正な入力を検出できないと脆弱なシステムとなります。
• The application is unable to detect, escalate, or alert for active
attacks in real time or near real time
(アプリケーションが現在進行中の攻撃を即時または即時に近い時間で検出、エスカレートまたは警告できない)
ZAPで簡単に生成できる攻撃用の不正な入力は、HTMLフォームの入力に限りません。HTTPヘッダー、クッキー、URLパラメーター、HTMLフォームには含まれない余計なパラメーターや改ざんされたパラメーターなども含まれます。
これらをアプリケーションの”どこで”、”どのように”検出し対応すべきでしょうか?もちろん「入り口」で検出します。OWASPでは「今のWebアプリは入り口対策は全くと行ってよいほどない」と考えています。
どこでどのように検出すべきか?の前にまず、入力バリデーションとは何か?OWASP Code Review Guide V2.0の説明を紹介します。
7.6 Input Validation
Input validation is one of the most effective technical controls for application security. It can mitigate numerous vulnerabilities including cross-site scripting, various forms of injection, and some buffer overflows. Input validation is more than checking form field values.
(入力バリデーションは最も効果的なアプリケーションセキュリティの1つである。入力バリデーションな数えきれない脆弱性、クロスサイトスクリプティング、様々な形式のインジェクション、そしてバッファーオーバーフロー攻撃を緩和できます。入力バリデーションとは単なるフィールド値のチェックではないです。)All data from users needs to be considered entrusted. Remember one of the top rules of secure coding is “Don’t trust user input”. Always validate user data with the full knowledge of what your application is trying to accomplish.
(全てのユーザーからのデータは信頼可能でなければならない。セキュアコーディングの最大のルールの1つ「ユーザー入力を信頼するな」を思い出してください。貴方のアプリケーションがユーザーデータで何をしようといているか、全ての知識を使い、常にユーザーデータをバリデーションしなければならない。)Regular expressions can be used to validate user input, but the more complicated the regular express are the more chance it is not full proof and has errors for corner cases. Regular expressions are also very hard from QA to test. Regular expressions may also make it hard for the code reviewer to do a good review of the regular expressions.
(正規表現はユーザー入力をバリデーションする為に利用できる。しかし、より複雑な正規表現はより多くの検証不足(訳注:バグ)とエッジケースの問題を持つ可能性が高くなる。正規表現はQAからテストすることが非常に困難でもある。正規表現はコードレビューワーが質の高い正規表現のレビューを困難にする。)訳注:要するに正規表現はリスク、多用するな、です。Data Validation
All external input to the system (and between systems/applications) should undergo input validation. The validation rules are defined by the business requirements for the application. If possible, an exact match validator should be implemented. Exact match only permits data that conforms to an expected value. A “Known good” approach (white-list), which is a little weaker, but more flexible, is common. Known good only permits characters/ASCII ranges defined within a white-list.
(システムに対する全ての外部からの入力(加えて、システム/アプリケーション間の入出力)は入力バリデーションしなければならない。バリデーションルールはアプリケーションのビジネス要求で定義される。可能であるなら厳格に一致するバリデーターを実装しなければならない。厳格な一致は期待している値のデータだけを許可することを保証できる。”良いモノ”を許可するアプローチ(ホワイトリスト)は少し弱いがより柔軟で一般的である。”良いモノ”を許可するアプローチはホワイトリストで定義された文字/ASCIIの範囲のみを許可する。)Such a range is defined by the business requirements of the input field. The other approaches to data validation are “known bad,” which is a black list of “bad characters”. This approach is not future proof and would need maintenance. “Encode bad” would be very weak, as it would simply encode characters considered “bad” to a format, which should not affect the functionality of the application.
(この範囲は入力フィールドのビジネス要求によって定義される。別のアプローチに”悪いモノ”、つまり”ダメな文字”をブラックリスト化しバリデーションする方法がある。このブラックリストアプローチは将来に於て有効ではなく、メンテナンスを必要とする。”悪いモノをエンコードする”は非常に弱い、何故ならこれは単に”悪い”と考えられる文字を、アプリケーションの機能に影響しないよう、別の文字に変換するだけだからである。)訳注:要するにブラックリストはダメ、サニタイズはもっとダメ。Business Validation
Business validation is concerned with business logic. An understanding of the business logic is required prior to reviewing the code, which performs such logic. Business validation could be used to limit the value range or a transaction inputted by a user or reject input, which does not make too much business sense. Reviewing code for business validation can also include rounding errors or floating point issues which may give rise to issues such as integer overflows, which can dramatically damage the bottom line.
(ビジネスバリデーションはビジネスロジックに関係している。ビジネスロジックバリデーションに関わる全てのビジネスロジックをコードのレビュー前に理解する必要がある。ビジネスバリデーションは値の範囲を制限したり、ユーザーによるトランザクションであったり、論理的に意味をなさない入力の拒否である。ビジネスバリデーションのコードレビューには丸め誤差や前提を劇的に破壊する整数オーバーフローなどを起こす浮動小数点問題が含まれる。)
入力バリデーションにはData Validation(データバリデーション)とBusiness Validation(ビジネスロジックのバリデーション)があります。この区別をしっかり理解している必要があります。
Data Validationは入力値のデータ形式をISO 27000が要求する方式でバリデーションします。データの論理的な正しさを検証する必要はありません。6形式だけで十分です。アプリケーションのData Validationはアプリケーションの信頼境界で行います。適切な場所はMVCモデルなら”コントローラー”です。
Business Validationはビジネスロジックとして、送信された日付が存在する日付か?ビジネスロジックとして正しい日付か?(例えば予約で過去の日付はあり得ない)などデータの論理的な妥当性をバリデーションします。適切な場所はMVCモデルなら”モデル”です。
-
- 2版の公開は2007年、v1にも同じ誤りが在ったと記憶しています。2016年秋の改訂まで、少なくとも10年間も基礎的誤りがあったセキュアプログラミングを啓蒙していたことになります。 ↩
-
- 2016年10月の改定ではCERT Top 10 Secure Coding Practicesは紹介されておらず、2017年6月の改定で追加されたように思います。前の版は参照できないようなので前の版(2016年10月版)のURLをご存じの方、教えてください。 ↩
-
- 私も人間なので勘違いや間違いもすれば、バグも作るし、脆弱性も作ります。間違えたと気付いた時には然るべき対応もしています。間違えない方が良いに決まっていますが、人は間違えるモノです。IPAも”自身の間違いに対して”、然るべき対応を期待します。 ↩
-
- 私は10年以上も孤軍奮闘(?)と言える状況で、もうこの話題にはほとほと疲れています。「数値+”他の何か”でも加算ができる!」は原理的にダメ/成り立たない、をどう説明しても理解できないのですから。セキュリティ業界の闇と言える事象にたまたま関わってしまった不運を呪いたい (笑) ↩
- クライアントが送ってくることが可能なデータであることをバリデーションします。Data Validationでの論理的バリデーションは必要ありません。クライアントが存在する日付だけ送ってる、クライアントは過去の日付を送ってこない、といった条件があり簡単に検証できるのであれば「存在する日付」「未来の日付」である論理的バリデーションを行っても問題ありません。というより、可能であるならこういったバリデーションをコントローラーで行った方が良い場合も少なくないです。 ↩