信頼境界線(Trust Boundary)と境界防御はITセキュリティに限らず、セキュリティ対策の基礎中の基礎です。基礎中の基礎かつ最も重要な概念ですが習わないことが多いです。これが原因で「正しいセキュリティ対策」(≒効率的なセキュリティ対策)ができていないケースが多数あります。残念ながら”セキュリティに詳しい”とされている人でも全く理解していないケースが散見されます。
このエントリでは主に、ソフトウェアセキュリティに於ける信頼境界線の概念と引き方(≒セキュリティ構造/設計)、ついて紹介します。かなり長いエントリになりましたがお付き合いください。
セキュアコーディングの概念は解説していません。このエントリはセキュアコーディングの概念を理解してから読まないと理解が困難かも知れません。CERTのトップ10セキュアコーディング習慣を先に読んでおくと解りやすいと思います。
さて、
- 信頼境界線とは境界防御を行う境界です
セキュリティ対策において境界防御は最も重要な対策の1つです。様々なセキュリティ対策がありますが、まず境界防御を行わないと始まりません。
境界防御は重要な概念ですが、当たり前過ぎるためか、明確な定義はネットを検索しても出てきません。検索すると「境界防御」はネットワークセキュリティではよく利用される用語であることが解ります。”境界”防御、というくらいなので、”境界”がない/定義されていないと防御できません。
今のところ「境界防御」とは
- 信頼できるモノと信頼できないモノの境界(信頼境界線)で行う防御策
と理解してください。
なぜ信頼境界線は重要なのか?
信頼境界線の概念を理解していないと、セキュリティ対策の基礎中の基礎である”リスク分析/評価”もできなくなります。”リスク分析/評価”は大別して2箇所で行います。
- 信頼境界線を行き来する情報(ソフトウェアでは”入力”と”出力”)
- 境界線内のモノ(ソフトウェアでは”ライブラリ”や”フレームワーク”)
9割以上のソフトウェアセキュリティ問題は1.で発生1しています。「信頼境界線上」で防御を行う「境界防御」の概念はとても重要です。しかし、セキュリティ専門家2の間では当たり前の概念過ぎてほとんど解説されてきませんでした。
信頼境界線を定義し、それを防御する境界防御、は「セキュリティの構造化」です。
詳しくは「論理的背景とは」セクションを参照してください。
信頼境界線とは?
ITシステムセキュリティに於ける信頼境界線とは
- 開発者/管理者がシステム/ネットワーク/ソフトウェア/データを、”特定のコンテクスト”に於て、完全に制御でき、完全または部分的に信頼できる境界
になります3。ユーザー(人)も重要ですが、ここでは省略します。4
この定義は英語版Wikipediaの定義
any distinct boundary within which a system trusts all sub-systems (including data)
(あるシステムが他の全てのサブシステム(データを含む)を信頼する、あらゆる区別可能な境界)
とは多少異なりますが、本質的には同じ定義です。
Wikipediaの定義では「データを含めた全ての信頼可能なシステム」5としています。
しかし、これは理想的(仮想的)な状況に於てのみ適用可能な条件です。実際にはデータを含めたシステム/ネットワーク/ソフトウェア全体を完全に信頼できることは稀です。これはネットワークの信頼境界線を見れば明らかです。6
ネットワークシステムの場合、外部と内部のネットワークの境界が信頼境界線になります。この境界をネットワークファイアーウォールを使って分離します。完全に分離7していれば、内部ネットワークは信頼できるモノにできます。
実際にはユーザーはメールを受送信し、Webサイトを参照します。これだけで分離できていないことが明らかです。完全に分離、という前提条件は多くの場合で成り立ちません。これが、境界防御が曖昧になってきている/限界にきている、と言われる所以です。
しかし、これは本当でしょうか?外部からのデータ(メールやWebトラフィック)を分離して扱えば、信頼境界線を引き、境界防御が可能です。8 同じことがソフトウェアの信頼境界線でも言えます。
ITシステムの信頼境界線の種類
信頼境界線と言っても種類があります。どの種類の信頼境界線なのか?理解した上で利用しないとトラブルの元です。
https://blog.ohgaki.net/security-anti-practice-designless-software-security
ITシステムの信頼境界は4種類あります。
- 物理(物と人)
- ネットワーク
- ソフトウェア
- システム(上記の3つをまとめた物)
の4種類があります。これらを多層防御、つまり物理/ネットワーク/ソフトウェア/システムの最外周だけでなく中にも防御線(=信頼境界線)を設定し多重化した形で設計します。
例えば、オフィスの物理的セキュリティ対策なら、一番外側の入館箇所、その中のオフィススペース、その中のキャビネット、机、金庫と、多重化してセキュリティを維持します。ネットワーク/ソフトウェアの中も同じように信頼境界を設定して防御します。
信頼境界線なしの防御
「信頼境界線なしの防御」はセキュリティ設計なしに、モグラ叩き的に見つかったセキュリティ問題を一つ一つ潰していく方法、つまり構造がないセキュリティ対策、です。論理的には「信頼境界線なしの防御」でも「信頼境界線ありの防御」と同じレベルの安全性を確保できます。問題を一つ一つ解決していけば、最終的には全ての問題が解決します。
しかし、現実的には「信頼境界線なしの防御」(セキュリティ設計なしの防御)が「信頼境界線ありの防御」(セキュリティ設計ありの防御)と同じレベルの安全性を達成することは不可能です。論理的には「ブラックリスト方式」で対策を突き詰めると「ホワイトリスト方式」と同じレベルの安全性になるが、現実的にはブラックリスト方式が非常に脆弱であることと同じです。
PCや携帯をファイアーウォール無しでインターネットに接続して、安全に利用できる日はいつ来るでしょうか?新しいソフトウェア/コードを一切作らず/使わず、バグ修正のみを行っていれば、いつかは安全に利用できる日が来るかも知れません。しかし、「新しいソフトウェア/コードを一切作らず/使わず」という前提は不可能です。ソフトウェアは日々新しく造られ、改良されています。
従って「信頼境界線なしの防御」(ブラックリスト方式)が「信頼境界線ありの防御」(ホワイトリスト方式)と同じレベルの安全性になる、は現実にはあり得ないと考えるべきです。
注:できるだけ細かく信頼境界を分けて、全てを完璧/理想に近い形で防御すべき、という話ではありません。それでは限り無いリソースが必要になります。ITセキュリティ対策の”目的”は「許容可能なリスクの範囲内でITシステムを利用可能にする」ことにあります。信頼境界線を作って対策する、は”手段”であり、”目的”ではありません。
信頼境界線の引き方
信頼境界線の概念は簡単ですが、コンテクストや粒度が説明されることは少なかったと思います。このため、誤解や混乱をしているケースが少なからずあります。この辺りの説明は後に記載しています。
信頼境界線の引き方(=セキュリティ構造の作り方/セキュリティ設計の方法)
- 信頼境界線は信頼できるモノと信頼できないモノの間に引く
- 信頼境界線はコンテクスト別に引く
- 信頼境界線は粒度別に引く
信頼境界線の概念は簡単です。しかし、コンテクスト、粒度が相互に関連するので複雑化したシステムを整理整頓して適切/最適なセキュリティ設計を行うには、ネットワーク/ハードウェア/ソフトウェア/データに関する知識が必要です。
簡易な建物の設計図は一枚の紙で済むかも知れません。しかし、ある程度複雑な建物の設計図は一枚で済みません。電気の配線、水道/排水の配管、といったコンテクスト別の設計図が必要になります。施工に必要な施工図も必要です。1つにまとめると何が何だか判らない設計図になります。セキュリティ設計も同じです。コンテクスト/粒度別に設計する必要があります。
信頼境界線を引く際のルール
- 信頼境界線内に出入り及び境界内で利用する全てのリソース(物/プログラム/データ/人)が信頼できることを完全に保証(リスク廃除)する
- リソース(物/プログラム/データ/人)が信頼できることを完全に保証せずに出入り又は利用する(リスク受容)場合、そのリスクの管理[^risk-mgmt]をする。
リスク管理の方法や体制はISO 13335やISO 27000を参考にすると良いです。
最も重要なデータの入出力に着目したソフトウェアの信頼境界線(セキュアプログラミングに於けるセキュアなソフトウェアのアーキテクチャー)は以下のようになります。
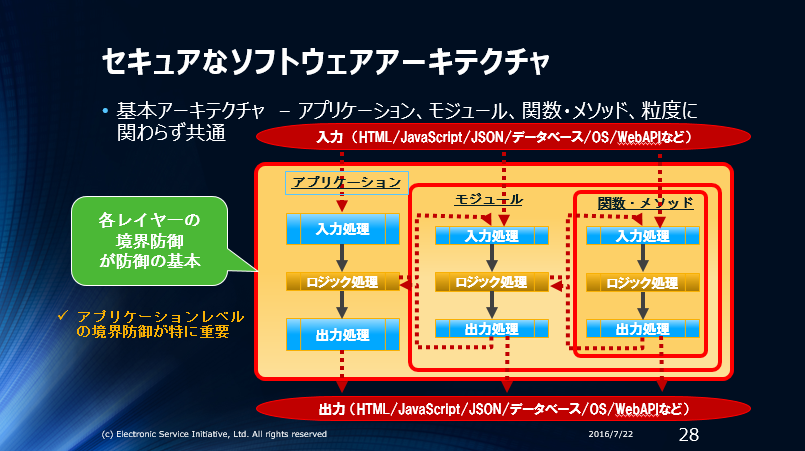
セキュリティ脆弱性ができる理由
ここまでを理解すると、セキュリティ脆弱性ができてしまう理由は簡単に解ります。
- 信頼境界線内に出入り及び境界内で利用する全てのリソース(物/プログラム/データ/人)が信頼できることを完全に保証(リスク廃除)する
- リソース(モノ/プログラム/データ/人)が信頼できることを完全に保証せずに出入り又は利用する(リスク受容)場合、そのリスクの管理[^risk-mgmt]をする。
これらに問題があるので、セキュリティ問題が生まれます。
例えば、ファイアーウォールを使っていても、攻撃用ファイルを添付したメールでの攻撃が可能になるのは、「メールに添付されたプログラム/データが信頼できるモノ」であることを「完全に保証」していない、にも関わらず「リスク管理をせず」に利用することにより問題が生まれます。
プログラムのセキュリティ問題となるモノの多くがインジェクション問題です。SQL/JavaScriptインジェクション問題が発生する原因は、信頼境界線を越えて「データが信頼できることを完全に保証せずに出入りさせる」ことにあります。
インジェクション型のセキュリティ問題を防ぐには、信頼境界線上の入口と出口でデータが信頼できることを完全に保証します。CWE/SANS Top 25の怪物的なセキュリティ対策、CERTのセキュアコーディング習慣、OWASPのセキュアコーディングプラクティス、などでは
- 先ず第一に入力データが入力として正しい/妥当なモノかバリデーションする
- データを出力する場合に完全に安全性を保証する
といった対策を実施すべきとしています。
一昔前には、プリペアードクエリ/プレイスホルダだけでは不十分であることが明確であるにも関わらず、「SQLインジェクション対策にはプリペアードクエリ/プレイスホルダさえ使っていれば良い(なのでエスケープは要らない)」といった間違った主張が普通に行われていました。セキュリティ設計の基本、インジェクション対策の必要十分条件を理解していれば、完全なSQLインジェクションとはどんなモノか?は議論を待たずに結論できたと思います。
全てのセキュリティ脆弱性は廃除すべきか?
YesとNoです。これは難しい問題です。これも「コンテクスト」と「状態」によります。
例えば、「インターネットに直接接続しているシステム」(コンテクスト)の場合、はYesです。WebサーバーやWebアプリケーションフレームワーク、Webアプリケーションに「容易に攻撃可能な脆弱性」(状態)がある場合、全ての脆弱性は廃除されなければなりません。
「インターネットから分離されているシステム」(コンテクスト)で、「安全性が保証されているか、リスクを受容可能なリスクとして受容している場合」(状態)、その脆弱性は必ずしも廃除されなくても構いません。問題は「受容可能なリスク」と考えているリスクが、「本当は受容可能ではないリスク」を発生させているケースが少なからずあることです。この点には十分な注意が必要です。
長くなるので詳細は省略しますが、例えば、開発環境では「リスク/脆弱性ゼロ」を目指すのは大きな無駄でしかない、と考えています。
特に現在の開発環境では、インターネットに公開されている大量のコードを利用し開発するスタイルが当たり前になっています。中には悪意のある開発者も居るかも知れません。開発者に悪意が無くても、開発者のアカウントを乗っ取り悪意のあるコードを混入させる攻撃もあり得ます。開発環境でリスクゼロ/脆弱性ゼロを目指すには、大きな無理があります。
「開発環境ではリスク/脆弱性ゼロ」を目指すのではなく、「攻撃をできない」様にした上で「攻撃を検知する」対策を導入した方が遥かに効果的な防御策になります。
何も対策を書かないのも問題なので簡単に書きます。ネットワークのシステム構成的に上記のような対策を導入していない場合、少なくともFirefox(業務用、開発用、インターネットサービス(gmailなど)用に別プロファイルを使うように!その他のインターネット閲覧には別のシステムとネットワークを使わないと効果が非常に少くなります。)とNoScript(ABEは無効にしないように!最小限のサイトのみJavaScriptを許可するように!)を利用することを強くオススメします。
あまりオススメしませんが、何も考えずにはFirefox+NoScriptを使っていても、ABE設定がデフォルト9、最小限のサイトのみJavaScript有効化している状態であれば、内部にある開発用のシステムや脆弱なIoTデバイスやルーターなどを攻撃されることがなくなります。
まとめ
長いエントリになったので、一旦ここでまとめます。
「信頼境界線(セキュリティの設計図)などは無用」と言うのは建物を建てる際に、「建物の設計図など無用」と言うことと同じです。個人で作る小屋程度なら別として、建築の専門家に「建物の設計図など要らない」と言う人は皆無でしょう。設計図は無用などと言う建築士は建築のプロとして認められません。
ITシステムの場合、明確なシステム/セキュリティ設計がなくても、ある程度適当な部品を、ある程度適当に組み合わせれば、概ね動くモノが作れてしまいます。結構大きなモノでもシステム/セキュリティ設計なしで作れてしまいます。ソフトウェアの場合も同じです。
幸か不幸か、ITシステムはセキュリティ設計が無くても、動くものは概ね出来てしまいます。「設計図など無用」でも通用してしまいます。実際、図面にした設計図がなくてもコーディングしながら設計も行い、プログラムを完成させられる開発者も少なからず居ます。これは一概に悪いことではありません。
成果物が効率的(コスト/仕様的)に作れるのであれば、図面にした設計図が無くても構わない、とも言えます。しかし、表示可能な設計図がない場合でも、少なくとも開発者の頭の中には「プログラムの構造」を図式化した「図面」があるハズです。これが無いようであれば、そのプログラムはとんでもないスパゲティプログラムでしょう。
システム設計図が無くても、良いプログラム構造のコードを書ける開発者はかなり居ると思います。しかし、システム設計図なしで良いプログラム構造のコードを書ける開発者であっても、良いセキュリティ構造のコードを書ける開発者少ないように感じます。
しかし、良いプログラム構造のコードを書ける開発者であれば、良いセキュリティ構造のコードを書くことは難しくないはずです!
基本を知っているだけで、自然と良いセキュリティ構造(=良いセキュリティ設計)のコードが書けるようになると思います!
まとめの後になりますが、信頼境界線の論理的背景、歴史的背景 – なぜ「構造化したセキュリティ」が普及しなかったのか?を記載しています。よろしければどうぞ!
論理的背景など
信頼境界線には誤解が多いようなので、もう少し詳しく論理的な背景などを説明します。
信頼境界線と”コンテクスト”
出力のセキュリティ対策にコンテクストが重要であることと同じで、信頼境界線に於てもコンテクストが重要です。
基本的な信頼境界の例
- インターネットとイントラネット
- 他人のコードと自分のコード
- は”ネットワークコンテクスト”、2.は”ソフトウェアコンテクスト”に於ける信頼境界です。
”自分のコードも信頼できない”という問題もありますが、”どこの誰がどう作っている”のか分らない、”他人のコード”を無条件に信頼できないことは明らかです。
信頼境界線を考える場合、以下のようなコンテクストで別々にセキュリティ設計を行います。
- システム全体
- ネットワーク
- 全社
- 部署
- 役割(サーバー専用/サービス別など)
- ハードウェア
- ファームウェア
- ユーザーデバイス
- ネットワークコンポーネントデバイス
- ソフトウェア
- OS
- アプリケーション
- ツール
- データ
- ネットワーク
建物を建築する場合に、
- 全体像の概要を設計
- 個別のコンポーネントを設計
- 各コンポーネントの詳細設計
- 各詳細設計の施工設計
- 各コンポーネントの詳細設計
- 個別のコンポーネントを設計
といった感じで設計することと同じです。設計がない建物が脆弱であるように、設計がないITシステムも様々な意味で脆弱になります。
注意すべき点は、「コンテクストが異ると、信頼できる、とされているモノでも信頼できなくなる」ことです。これが原因で「信頼境界線は役に立たない」と誤解されるようです。
例えば、システムセキュリティのコンテクストでは「アプリケーションサーバー」と「データベースサーバー」は信頼境界線の中に入れられます。
しかし、ソフトウェアセキュリティのコンテクストでは、基本的に「データベース」などの「外部システム」(ソフトウェアから見ると、他のプロセス、メモリやファイルシステムさえ外部システムです)は全て信頼境界線の外になります。信頼境界線の中に入れるには、信頼できることを保証してから入れなければなりません。
これはデータベースに保存されるデータには、普通はプログラムが生成したデータ以外のデータ、外部から入力されたデータが含まれているからです。プログラムから見るとデータベースのデータは信頼できません。
システム構成レベルのセキュリティ設計では「データベースサーバー」の中に信頼できないデータが含まれていても、普通は「データベースサーバー」を信頼できるモノとします。システム構成を考える場合、データが信頼できるかどうか?はあまり重要ではないので省略します。しかし、そこには(書かれていなくても)大きな但し書き「ただし、データベース内のデータは除く」10があります。
セキュリティ設計に慣れている方だと「この図はシステム構成コンテストでの信頼境界線だな」「この図はソフトウェア構成コンテクストでの信頼境界線だな」と解ります。見慣れていない場合、但し書きが無いと「なんだこの使えない図は?」になってしまいます。
信頼境界線と”データ”
信頼境界線内(ソフトウェア内)でのデータの取り扱いは厄介です。
信頼境界線内にデータを入れる場合、データが安全であることを保証しなければなりません。ソフトウェアは仕様に基き、データが安全な文字/形式/長さで構成されていることは”入力バリデーション”で保証できます。入力バリデーションでほぼ全てのリスクを回避することも可能ですが、常にそうとは限りません。
入力処理時の入力バリデーションでは出力時の安全性を完全に保証できません。しかし、これは入力バリデーションの欠点ではなく、役割が違う為に発生する問題です。入力処理時の入力バリデーションはソフトウェアにとって受け入れ可能な安全なデータであることを保証するのが役割です。
信頼境界線では入力と出力の安全性を完全に保証するようにします。出力処理時の出力安全性を保証するのは出力処理コードにあります。
データには「出力時の安全対策が必須のモノ」が含まれている事に注意が必要です。出力データの安全性保証の責任は出力コードにあります。入力と出力の安全性対策は”独立”した対策であり、入力は安全性の必要条件、出力は十分条件です。
信頼境界線と”粒度”
ソフトウェアの信頼境界線と境界防御には”粒度”がある、と考えると解りやすいです。プログラマであれば、システム/プログラム構造を考える場合、
- システムレベルでの構造(大きな粒度)
- アプリケーションレベルでの構造(中位の粒度)
- モジュール/ライブラリレベルの構造(小さな粒度)
- 関数/メソッドレベルの構造(より小さな粒度)
- モジュール/ライブラリレベルの構造(小さな粒度)
- アプリケーションレベルでの構造(中位の粒度)
といった異る粒度で構造を考えると思います。
より大きな粒度の場合、細かい粒度で考えるべき事は省略して(しかし、忘れずに)設計するでしょう。より細かい粒度では、大きな粒度で省略した事を明確にしながら設計するでしょう。
信頼境界線の引き方(セキュリティ設計)も同じです。
開発時にソフトウェア内の全ての粒度で信頼境界を作り、保証する仕組みが契約プログラミングです。開発者であれば契約プログラミングの概念と利点は正確に理解しておきたいです。
信頼境界線と”ゼロトラスト”
境界線を引いただけでは何も守れません。境界を防る必要があります。境界を防る上で必要な考え方は
- ゼロトラスト – 何も信頼しない
です。
境界防御ではまず「ゼロトラスト」から始めます。信頼境界内の物が信頼できないようでは、境界防御もままなりません。そこで
- 境界内にあるモノ/ソフトウェア/データはすべて信頼しない
状態から始めます。
モノとはサーバーやPC、ネットワークなどです。詳しい説明は省略しますが、これらのモノが信頼できない状態であるなら、防御のしようがありません。TPMがどのような仕組みで調べると参考になります。TPMは、信頼できるTPMチップから始めて、ボトムアップ方式で信頼できるハードウェアであることを確認できるようになっています。ソフトウェアも同じような形で信頼可能であることを確認できます。
ソフトウェアはOS、アプリケーション、フレームワーク、ライブラリなどです。
ソフトウェア開発の場合、は先ず自分のコードを信頼できるコードである状態にします。コード検査などで信頼できることを検証します。
他人が作ったソフトウェアが多いでしょう。OSやフレームワーク、ライブラリを信頼しない、とはどういうこと?と思うかも知れません。OSの中身を確認するなど不可能だ、フレームワーク、ライブラリの中身を全て確認もできない、と思うでしょう。
全て設計/実装レベルで信頼できることを確認すると理想的です。しかし、現実的には不可能です。信頼境界内にあるモノ/ソフトウェア/データは「少なくとも信頼しえる」と「ある程度保証できる」できればOKです。
「ある程度保証できる」とは「リスクを適切に評価した上で、リスクを許容し受け入れる」ということです。セキュリティに”絶対”はないです。許容可能なリスクは受け入れざるを得ません。
他のソフトウェアが誤作動したり、悪意のある動作をするかも知れないリスクを受け入れたとしても、”そのソフトウェアが何も考えなくても安全に動作するようにはなりません”。リスク受容で重要な点は
- OSやフレームワーク、ライブラリのセキュリティリスクを受容したから、といって”何も考えずに使っても安全”とは仮定しない
です。OSやフレームワーク、ライブラリに”バグ”があるリスクを受け入れても、リスクがある機能を使った場合の安全性は保証できません。
OSやフレームワーク、ライブラリを安全に使うには、安全な使い方があります。責任は明確です。
- 信頼済みの物でも、安全に使う責任は、利用者/開発者にある
信頼するとした物でも、適切に使わなければセキュリティ問題になります。具体的には以下のような作業を行います。
- 受容したリスクと受容していないリスクを明確に区別する
- 常にリスクを識別/評価して、受容可能なリスクレベルを維持する
これを行うには、適切な”コンテクスト”と適切な”粒度”での信頼境界線の識別/設定、が必要になります。
ソフトウェアの場合、自分が書いたコードのみが信頼できる物、として始めて利用するフレームワーク/ライブラリ/外部システム(サーバーやクライアント)がどのようなコンテクストと粒度で信頼できるのか、確認します。
ここで間違えてならないのは以下です。
- 自分が完全に制御する検証済みコード以外(データ含む)は全て信頼できない
当然ですが、コピー&ペーストしただけのコードは自分が書いた信頼できる検証済みのコード、ではありません。「自分が完全に制御する検証済みのコード」にするは「自分(または同僚、コード検査サービスなど)で検証する」しかありません。
信頼境界線と”境界防御”
”ゼロトラスト”でシステムの安全性を担保したソフトウェアなら「データ」が主な境界防御の対象です。データの境界防御にも”ゼロトラスト”を利用します。CERTのトップ10セキュアコーディング習慣、CWE/SANS Top 25の怪物的セキュリティ対策、に記載されている事を採用すれば良いです。具体的には、
- 入力のバリデーション – 信頼境界を越える全てのデータが入力として信頼できる入力(妥当な入力)か検証する
- 出力の完全な無害化 – 信頼境界を越える全ての出力データを無害化する
を行います。要するに信頼境界を越える全てのデータの安全性は入力と出力時に保証します。
基本的に入出力先はコードで静的に初期化しているデータ以外、全てです。ライブラリ関数やメモリ内容も信頼境界線を越える入出力先になる場合があります。
信頼できるとしてソフトウェアに組み込んだライブラリの関数などであっても「セキュリティ処理は内部で適当に行っている」と検証せずに信頼してはなりません。正規表現関数が良い例です。何も考えずに使うとReDoSに脆弱になります。利用頻度が少ないLDAPやXPath APIの利用例には危険な物が多数あります。
自分で静的に初期化したメモリは信頼しても構わないです。しかし、メモリ内にあるデータでも信頼できないことは多いです。例:共有メモリ、システムが自動初期化したメモリ、PHPなら$_SERVER、$_ENV、$_GET、$_POST、$_COOKIEなど、APIで取得したHTTPヘッダーなど。
一々ライブラリ関数の仕様やシステムや他のプロセスが初期化したメモリが信頼できるか検証できない、という場合は「入力データを自分でバリデーションしてから使用」すれば良いです。多くの入力データは限定的にバリデーションすれば、インジェクション攻撃ができないデータになることが少なくないです。残存リスクには十分に注意してください。
出力の無害化は比較的容易です。出力セキュリティ対策の三原則を利用すれば大丈夫です。
- エスケープする(確実/適切なエスケープ方式であることを保証)
- エスケープが必要ないAPIを使う(APIの制限に注意。例:プリペアード文は識別子などを分離しない。APIを安全に利用するためにはエスケープ方式を知っている必要がある場合が多い)
- 上記2つが行えない場合、バリデーションを行う(出力先が誤作動し得ない限定的バリデーションを行う。これには適切なエスケープ方式を知る必要がある)
出力対策で忘れてはならない点は「セキュアコーディングでは、出力対策は”独立”した対策」であることです。たとえ入力データ処理のバリデーションで、データの安全性が保証されていたとしても、出力対策では”独立”したセキュリティ対策として「完全な無害化」を行います。
信頼境界線と”多層防御”
入力対策で安全性を確保しているのに、出力対策で更に無害化を行うのは無駄ではないか?と思うかも知れません。セキュリティ対策は基本的に”無駄”なこと(多層防御)を行う物だと思い出してください。例えば、Webアプリケーションファイアーウォール(WAF)によるインジェクション対策のほとんどはアプリケーションで行うべき対策で”無駄”です。WAFのインジェクション対策は無駄でしょうか?無駄とは言えないと考えられます。
有効な多層防御を省略するより、他の部分を高速化した方が良いです。
例えば、PCRE(Perl互換ライブラリ)がマルチバイト文字マッチを行う場合に無駄なUTF-8エンコーディングのバリデーションを行うことにより、何十倍も何百倍も遅くなる無駄を気にした方が良いです。PCREはUTF-8バリデーションを省略すると高速に動作11します。この為には、入力データの文字エンコーディングが予めバリデーションされていることが必要です。
信頼境界線と”リスク分析/評価”
セキュリティ問題の多くは信頼境界線を越える入力と出力で発生します。致命的なセキュリティ問題の多くは信頼境界線の引き方/管理を間違えた事によって発生しています。
リスク分析/評価は適切なセキュリティ対策を行う上で欠かせないですが、忘れられがちです。リスク分析/評価の漏れを少くする最善の方法は”ゼロトラスト”です。盲目的に信頼しないことから始めると、隠れていたリスクも見えてくるようになります。
信頼境界線は自分が完全に制御可能な範囲で自由に引けます。自由に引けますが、思い通りに引いて安全になるものではありません。
- その境界で本当にリスクが許容可能な範囲に収まるか?(漏れ、不適切なリスク許容はないか?)
- 境界防御に失敗した場合のリスク対策ができているか?(セキュリティに完全はない)
ソフトウェアの場合、基本的には
- 単一コンピューター上の単一プロセス/スレッド上で動作している自分のコード
だけが信頼できます。この他全ては信頼できません。他のモノを信頼するには、信頼可能であることを検証/保証する必要があります。
適切にリスク分析/評価を行った後はリスク管理です。リスクを評価しても、管理していなければ意味がありません。ISO 27000等を参考にすると良いです。
歴史的背景 – なぜ「構造化したセキュリティ」が普及しなかったのか?
なぜ「構造化したセキュリティ」が普及しなかったのか?これは「構造化プログラミング」の定着前後を見れば解ります。
論理的に当たり前でも直ぐに定着しなかった「構造化プログラミング」
一度定着してしまえば議論の余地がない当たり前の事であっても、定着するまでは当たり前ではなく、議論の対象になることは割とあります。一番解りやすい例は「構造化プログラミング」でしょう。
最近の開発者は「構造化プログラミング」という言葉さえ聞いた事がないかも知れません。それもそのはず、構造化プログラミングは1960年代後半から提唱されたプログラミング手法12です。
- 構造化プログラミングとは、goto文のような処理へのジャンプを使わず、制御文(if文、while文など)/ブルーチン(関数・メソッド)/ブロック(Cなどなら{})などを使いプログラムを構造化するプログラミング手法
構造化プログラミングと聞いて何のことかピンと来なかった方も「これをやらないのは馬鹿げている、あり得ない」「これは当たり前過ぎる」と考えると思います。しかし、ダイクストラ氏が”goto文は有害”とする構造化プログラミングの論文を書いた際には「構造化プログラミングは要らない、無駄だ!」と本気で主張する著名な開発者も多数いたそうです。
私がプログラミングを始めたのは小学生の頃、80年代初めからです。その頃でも「構造化プログラミングとしましょう」と雑誌に記載されていたことを覚えています。
なぜ「構造化プログラミング」のように当たり前が”当たり前”に受け入れられるまで長い時間が必要だったのか?それは”それ以前の当たり前”が”非構造化プログラミング”だったからです。今、当たり前であることは、例えそれが非効率でも非論理的でも、簡単には変わりません。13
重要な信頼境界線と境界防御がなぜ解説されていないのか?
最初の国際ITセキュリティ標準 ISO 13335(1995年策定)ではリスク評価/管理を実施する方法/体制について詳しく解説しています。しかし、残念ながら信頼境界線/境界防御とリスク評価/管理の関係についてはほとんど解説されていません。
時間の問題で普及すると思われていた?
信頼境界線/境界防御が詳しく解説されていない理由の1つは、”コンピューターサイエンスに於けるセキュリティ対策として既に確立している(そして一般にも時間と共に普及する)”と考えられたいた、からだと思われます。”防御的プログラミング”はISO 13335が1995年に策定される前、90年代初め頃にはソフトウェアセキュリティ基本対策として提唱14されていました。セキュリティ標準規格を策定していた方々は、信頼境界線/境界防御などの基本概念は理解されている(または理解される)、という前提で規格策定を行ったのだと思われます。
私自身も信頼可能な範囲の必要十分条件を解っていれば、誰でも正しい信頼境界線を引けて、正しい境界防御を行えるようになる、と思っていました。
実際、ネットワークシステムのセキュリティ対策として、インターネットとイントラネットを信頼境界線とする境界防御(ファイアーウォール)、は広く受け入れられました。一般家庭のデバイスでさえ、ファイアーウォール無しでインターネットに接続することはまずありません。
予想外の出来事?
しかし、ソフトウェアになると話が全く変わります。当たり前の「構造化プログラミング」を否定する開発者が居たのと同じように、「信頼境界線」「境界防御」を否定する開発者やセキュリティ専門家とされる人達までいます。
「境界防御に於ける入力対策がセキュリティ対策ではない」15や「入力対策は一定のセキュリティ対策効果はあるが、効果的なセキュリティ対策ではない」など、情報セキュリティ対策を論理的に組み立てている人からすると”あり得ないような議論”は今でも見られます。
90年代半ばに国際ITセキュリティ標準を策定した中心的な方々は、恐らく「”構造化プログラミング”という簡単な概念でさえ、一般開発者へ普及するまでに時間がかかったことを”リアルタイム”で見てきた」方々だと思います。「信頼境界線」と「境界防御」による「構造化されたセキュリティ」もある程度時間がかかるが、簡単な概念なので時間と共に普及するだろう、と考えていたと思われます。16
以上です。長いブログでしたが、最後まで読んでいただきありがとうございます。お疲れ様でした!
-
- 一方、悪意のある情報漏洩の7割程度が”内部実行犯”の犯行とする統計もあります。情報漏洩セキュリティ対策の効率の観点からいうと、”内部実行犯を作らない”対策の方が効果が高いとも言えます。 ↩
-
- 少なくとも、国際ITセキュリティ標準やセキュアコーディング標準などを構築/実践しているセキュリティ専門家にとって「信頼境界線」と「境界防御」は当たり前の概念でした。「信頼境界線」なしで「境界防御」は不可能です。定義もされてない境界を防御することはあり得ないです。境界が定義されていないセキュリティ対策は場当たり対策となり、効果的でなくなります。 ↩
-
- コンテクストとはシステム、ネットワーク、ソフトウェア、データなどです。それぞれ、全社/事業所/部署、アプリケーション/フレームワーク/ライブラリなどの更に細かいコンテクストに分けることができます。 ↩
-
- ユーザー(人)はITシステムセキュリティに於て非常に重要な要素です。ユーザーコンテクストの違いが重要(利用者の特徴 – 社内ユーザー/社外ユーザー、ユーザーIDの取り扱い、プログラム内でのユーザーの分離など)であること理解していない方は居ないと思います。簡略化の為にここでは無視します。 ↩
-
- Wikipediaの信頼境界線の定義が間違っているか?というとそうでもありません。「データを含めた完全に信頼可能な境界」が信頼境界線とする定義は、信頼できないデータを分離さえすれば信頼できるモノになる、と言えます。この考え方でも安全なセキュリティ構造を作れます。 ↩
-
- 厳密にいうと「信頼できるデータとできないデータ」を区別して、「信頼境界内のデータを全て信頼できるデータ」にすることは可能です。 ↩
-
- ネットワークを分離するだけでは不十分で、内部のネットワーク/デバイス/ソフトウェア/データ/ユーザーが全て信頼できるものでなければなりません。 ↩
-
- 信頼できないモノはサンドボックス環境で分離し、検証後に信頼境界線の中に入れればリスクを軽減できます。例えば、インターネットサイト/外部メールへのアクセスは独立したVLANに接続した仮想マシンで行い、ファイルなどは検証(ウイルスチェックなど)した後、信頼境界内のサーバーに保管/利用します。検証後に「信頼できるデータ」としたデータでも、他の本当に信頼できるデータ、とは別の場所(別の信頼境界)に保存するとより安全です。 ↩
-
- ABEがデフォルト設定の場合、外部サイトから内部IPアドレスに対するCSRF攻撃が出来なくなります。これでクロスサイトプリンティングやルーターの乗っ取りができなくなります。 ↩
-
- データベース内に信頼できない外部データがある場合。信頼できる計測機器からの数値計測データなどの場合、データも信頼できます。 ↩
-
- PHPのPCRE用にUTF-8バリデーションを省略するパッチもありました。しかし、ユーザーがバリデーションしていないとクラッシュする場合があるのでマージされませんでした。バリデーションが当たり前になるのは重要です。因みにHaskellのPCREにはUTF-8バリデーションを省略するオプションがあります。 ↩
-
- 構造化プログラミングは1960年代後半から提唱されましたが、プログラム自体の構造化はそれよりずっと前からコンピューターサイエンティストによって考案されていました。 ↩
-
- 不必要にgoto文を使うのは有害です。しかし、goto文全てが有害か?というとそうではありません。言語の制約なども関係しますが、コードのロジックがgoto文を使った方がシンプルで解りやすい場合などに、私も時々goto文を使います。 ↩
-
- プログラム(コード)が正しく実行されるコードであることを証明する研究は、コンピューターサイエンスの黎明期(少なくとも60年代初め頃。LISPは1958年から在る)から行われています。コードが正しく実行されるには、コードに入力されるデータが”コードにとって正しい入力データ”であることが必要条件である、と判っていました。1988年にモリスワーム事件が起きた直後からコンピューターサイエンティストは”コードが意図通り(つまり正しく)実行されるには、意図通りの入力データが必要条件である”、つまりコードの境界での入力バリデーションが必要である、と解っていたはずです。半世紀、四半世紀も前から判っていたことを解っていなかったらコンピューターサイエンティストとして失格ですから。アランチューリング氏の研究も含めたら半世紀よりもっと前になります。 ↩
-
- 酷いモノになると「アプリケーションの入力対策(バリデーション)は不可能」とする意見までありました。今時はこんなことを言っている人は流石に居ないとは思います。しかし、昔は大真面目に主張する方達が居ました。 ↩
- 私も「信頼境界線」と「境界防御」によるソフトウェアセキュリティの維持は、時間が経てば普及するだろう、と思っていました。ソフトウェアのセキュリティ対策はネットワークに比べ、20年近く遅れています。この大きな原因の1つは一部のセキュリティ専門家とされる人達にもあるでしょう。 ↩