ソフトウェアを開発している時に困るのは、ソフトウェアが正しく動作しないケース、に対応する事です。
実用的なソフトウェア作るよりもプロトタイプを作る方が簡単であるのは、ソフトウェアが正しく動作しないケース、に対応する必要がないことが大きな理由です。ソフトウェアが正しく動作しないケースに対応するには、様々な例外的な状態(入力データとソフトウェアの内部状態)全てに対応する必要があります。
例外的な状態を定義するには”ダメな状態”を定義する必要があります。”ダメな状態”を漏れ無く定義するのは結構大変です。ソフトウェアバグの多くは”ダメな状態”を漏れ無く定義することに失敗した為に生まれています。
参考:データセキュリティの概念がないと「正しく動作するプログラム」は作れない。
https://blog.ohgaki.net/learning-security-from-rdbms-data-security
https://blog.ohgaki.net/crude-software-security
”ダメな状態”を定義 = ブラックリスト型の定義
”ダメなモノ”を定義するのはブラックリスト型の禁止事項を定義することを意味します。ブラックリスト型の定義はその仕組み上、漏れ無く定義することが困難です。漏れ無く定義する事が不可能である場合も少なくありません。
Railsセキュリティガイドではホワイトリスト型とブラックリスト型のセキュリティ対策について以下のように記載しています。
サニタイズ、保護、検証では、通常ホワイトリストの方がブラックリストよりも使用されます。
特定の項目だけを許可するホワイトリストアプローチは、特定の項目だけを禁止するブラックリストアプローチに比べて、ブラックリストへの禁止項目の追加忘れが原理的に発生しないので、望ましい方法であると言えます。
ブラックリストではなくホワイトリストに基づいた入力フィルタを実施することが絶対重要です。ホワイトリストフィルタでは特定の値のみが許可され、それ以外の値はすべて拒否されます。ブラックリストを元にしている限り、必ず将来漏れが生じます。
”ダメな状態”を定義するブラックリスト型の例外処理も漏れが発生しやすいです。できる限り避けなければなりません。
”例外”を使うと例外対応漏れをかなり防げる
よくエラーを使うより”例外”を使いなさい、と言われます。これはエラーステータスなどを使うと問題が発生した場合にエラーステータスを無視してしまう、といったミスが起こり易いことも理由の1つです。1
”ダメな状態”になってしまった場合に”例外”を投げ、それをキャッチする方法で例外状態(=ダメな状態)の対応漏れをかなり防ぎやすくなります。防ぎやすくなる、とは言っても”例外”を投げるのは呼び出された関数/メソッドの役割で、”ダメな状態”になってしまい適切に”例外”を投げるのは呼び出された関数/メソッド次第、です。
運を天に任せる、ではありませんが”例外”に頼るでは、呼び出された関数/メソッドが確実に適切な例外を発生させることに任せる、になってしまいます。
確実に正しく動作するソフトウェアを作るには少し心許無いです。
”例外”を使っても困った問題が発生する
”例外”と名前が付いている通り、”例外”が発生する状態は普通の状態ではありません。
そして、コードは基本的には”正常”に動作する場合を想定して記述されています。
正常に動作することを期待してコードを実行しているのに、途中で問題が発生しそのエラー処理をするとなると色々困ります。
- 処理を中止するとして、既に開いた状態のリソースをどうするのか?
- ”例外”が発生するまでに処理してしまったモノをどうするのか?
これらに適切な対応を行うことは結構手間です。既に処理してしまったモノ、例えば送ってしまったメールなど、は通常は取り返しができません。
”ダメな状態”になった時にはなった時、”例外”任せにして困った状態になってもできる限りの所までよしとする、では「正しく動作するソフトウェアの作り方」としてはNGです。
できる限り”例外”が発生しないような作り方をしないと「正しく動作するソフトウェアの作り方」にはなりません。
”例外”やエラーをどうやって発生させないようにするか?
外部システムの状態、ソフトウェア内部の状態、副作用があるモノなどを使っていて発生してしまう例外にできることはあまりありません。例外処理を出来るだけ正しく行えるようにするしかありません。
これら以外の例外を出来るだけ発生させない効果的な方法があります。例外が発生する大きな原因に”おかしな入力値”があります。
”例外”を発生させる最大の原因はデータ
”おかしなデータ”が例外を発生させる最大の原因で多くの”おかしなデータ”の発生元は”入力データ”です。つまり”入力データ”から”おかしなデータ”を排除すればかなり多くの例外処理をなくせます。
”おかしな入力データ”にはFail Fast原則を適用して対応します。
Fail Fast原則 – 失敗するモノはできる限り早く失敗させる原則
多くの開発者がFail Fast原則を意識して”例外”/エラー処理をしていると思います。しかし、Fail Fast原則を適用しているのはプログラムロジックの中だけ、という開発者が多いと思います。
もっと良い方法があります。”おかしな入力値”のチェックを”アプリケーションレベルの入力処理”(アプリケーションが最初に入力データを受け取る部分、MVCならC)で行なえば話が簡単です。
アプリケーションが正しく動作するはずがない”おかしな入力値”は、アプリケーションで処理する必要は一切ありません。正しいデータ/妥当なデータ(妥当なデータには入力ミスなどアプリケーションが受け入れるべきデータを含む)だけを受け入れ、後は「出鱈目でおかしなデータが送られたので処理しません」と返すだけでOKです。
受け入れるべき入力データとは以下の図の水色の部分です。
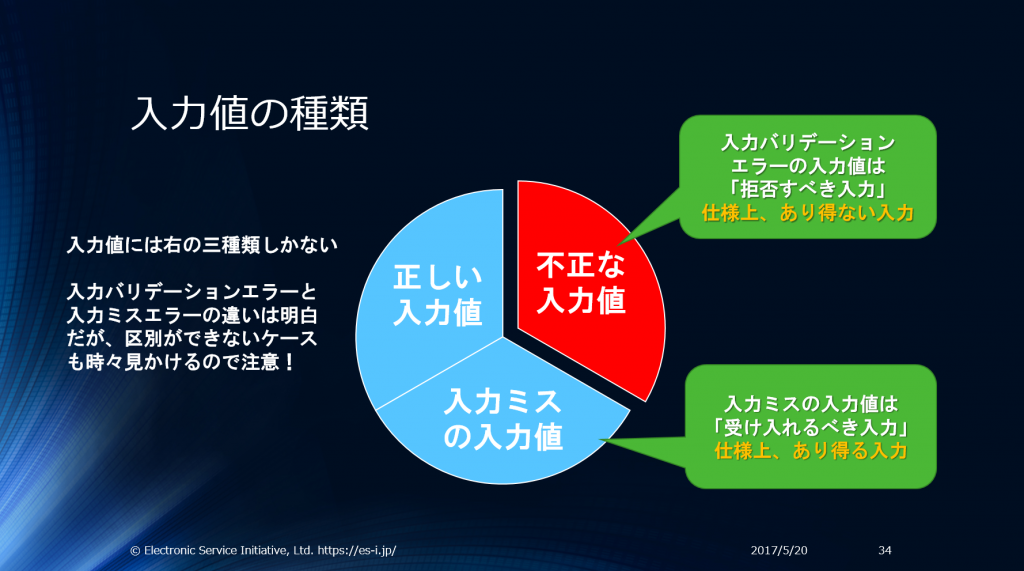
Fail Fast原則を使うと多くの例外処理を省略可能
関数/メソッドが”おかしな入力値”は送られてくることがない、正しいデータだけが送られてくる、を前提条件にできる場合は多くの例外処理が省略できます。
この例外/エラー処理を省略しても安全にプログラムが実行できるようにコーディング/設計する方法があります。これは”契約プログラミング”/”契約による設計”と呼ばれ既に多くの言語で、”契約プログラミング”/”契約による設計”(以下DbC)を利用可能な機能が提供されています。
図:DbCの構造
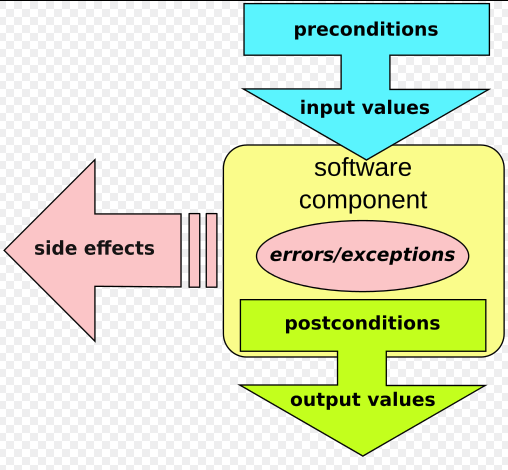
DbCは”おかしな入力値”だけを対象に利用する物ではありませんが、ここでは”おかしな入力値”だけを考えます。
DbCでは関数/メソッドを呼び出す場合、”おかしな値”を渡さない責任が”呼び出し側”にあります。
開発中は呼び出だす側が、”おかしな値”を渡さない責任、を果たしているか”呼び出された側”がチェックします。
PHPでDbCを取り入れたコード例
<?php
// 符号あり16bit整数の整数型だけ足し算をして返す関数
function add_short_int($a , $b) {
assert(is_int($a) && $a > -(2**15) && $a < (2**15)-1);
assert(is_int($b) && $b > -(2**15) && $b < (2**15)-1);
$sum = $a + $b;
assert(is_int($sum) && $sum > -(2**15) && $sum < (2**15)-1);
return $sum;
}
※ assert()は通常は開発時の場合のみ実行され、運用時には実行されません。
全ての関数/メソッドを上記の例のようなコードで、呼び出し側に正しい値を渡す責任を持たせるように書くと最終的に「呼び出し側に正しい値を渡す責任を持たせることができない限界」に達します。
「呼び出し側に正しい値を渡す責任を持たせることができない限界」がソフトウェアの信頼境界線になります。ソフトウェアはネットワーク通信、OSのファイル、OSのIPCを信頼することは出来ません。2
ソフトウェアの信頼境界線を越えてくるデータにはassert()を利用できないです。運用時にもバリデーションするようコードを書きます。(assert()を使わずにバリデーションする)
上のadd_short_int()の場合なら以下のように書きます。
<?php
// 符号あり16bit整数の整数型だけ足し算をして返す関数
function add_short_int($a , $b) {
assert(is_int($a) && $a >= -(2**15) && $a =< (2**15)-1);
assert(is_int($b) && $b >= -(2**15) && $b =< (2**15)-1);
$sum = $a + $b;
// 次のassert()には問題がある
assert(is_int($sum) && $sum >= -(2**15) && $sum =< (2**15)-1);
return $sum;
}
// Main プログラムコード
$a = $argv[1];
$b = $argv[2];
// サンプルコードを単純化するためにチェックが甘い。実際には整数であることの保証が必要
if (!isset($a) || !is_numeric($a) || $a < -(2**15) || $a > (2**15)-1) {
die('Invalid');
}
if (!isset($b)|| !is_numeric($b) || $b < -(2**15) || $b > (2**15)-1) {
die('Invalid');
}
echo add_short_int($a, $b);
// まだこの段階では正しく実行できることは保証できていません。
とは言っても例外処理を省略してしまうと、実際に問題が起きた時に困ってしまうから省略できないでしょう、と思うかも知れません。その通りで、DbCを使っても「関数/メソッドが”おかしな入力値”は送られてくることがない」を前提条件にしている場合でも必要最小限の例外処理は省略せずに残すべきです。
<?php
// 符号あり16bit整数の整数型だけ足し算をして返す関数
function add_short_int($a , $b) {
assert(is_int($a) && $a > -(2**15) && $a < (2**15)-1);
assert(is_int($b) && $b > -(2**15) && $b < (2**15)-1);
$sum = $a + $b;
//足し算の結果は範囲外になる可能性がある
//assert(is_int($sum) && $sum > -(2**15) && $sum < (2**15)-1);
if (!is_int($sum) && $sum < -(2**15) && $sum > (2**15)-1) {
throw new Exception('Addition result overflowed');
}
return $sum;
}
サンプルコードを短くする為に簡略化して書いていますが、どのように書く必要があるのか、は理解できると思います。
実行時に問題が発生することが予測されるバリデーション処理はassert()を使わず、運用時のプログラム中のどこかに残す必要があります。運用時のアプリケーションで残すバリデーションは次の図の赤い線の部分になります。アプリケーションレベルの赤い線(アプリケーションの信頼境界)を超える入力値は全て確実にバリデーションします。
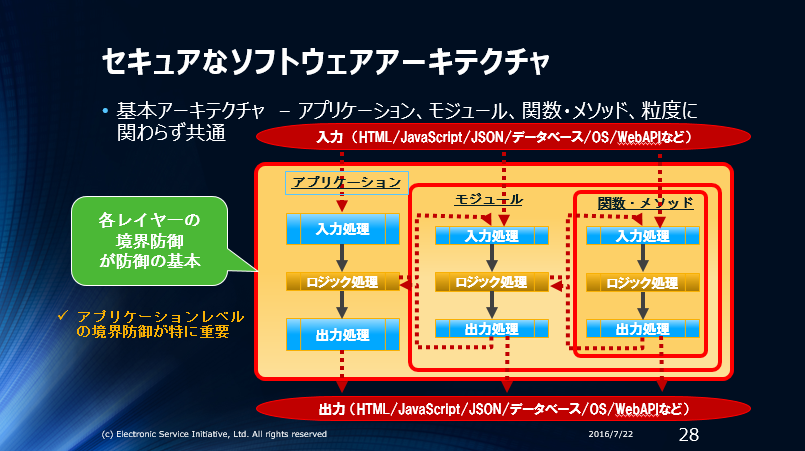
https://blog.ohgaki.net/design-by-contract-and-trust-boundary
アプリケーション内部の赤い線の部分は、必要な物だけ運用時に残します。
このサンプルコードのadd_short_int()の仕様では例外が残ってしまうので、困った事になってしまいます。できれば入力値の範囲を狭めるか、結果に大きな値を許す仕様に変えてしまった方が簡単です。
DbCにも問題はある
DbCを使って例外/エラーを減らすことが可能です。しかし、重要な問題が残ります。
- assert()を間違って使った場合はかなり困る
先の例でも間違ってassert()を使ってしまうと、おかしな出力になり困った事態に成り得ると解ります。
コンピュータは正しいコードと正しい(妥当な)データの両方が揃って初めて正しく動作するので、どちらが欠けてもダメです。
最悪、おかしな状態になった場合に強制終了できるよう例外を残す、といった設計にするのも十分にあり得る設計です。無理矢理、理想的なDbCにする必要はありません。
DbC有り、DbC無しのプログラムのテスト
DbC無しの例外/エラー処理だけに頼った設計でも、おかしな入力データや結果で例外/エラーが発生するテストケースが必要です。例外/エラー処理だけに頼った設計でも、DbC設計でも、テストして例外/エラーが発生すること/しないこと又はDbCのassert()エラーが発生しないこと確かめておく必要があります。
つまり、DbC設計利用の有無に関わらず、エッジケースのテストは作っておく必要があります。結局、DbC、非DbCの違いに関わらず、正しく動作するソフトウェアを作ろうとすると同じテストケースが必要になります。どうせテストを作るなら効率が良い方を選んだ方が良いでしょう。
それでも不安だという場合、DbCの基本概念/設計は活かしたまま、従来通りの例外/エラー処理を記述したままにする、といった設計も可能です。この場合、DbC導入による間違ったassert()使用リスクは無いまま、DbC設計のメリット(確実で安全なデータの受け渡し)を享受できます。
例外を残すトレードオフはエラーチェックを行うコードのオーバーヘッドで発生する実行速度低下です。しかし、そもそも例外処理にデータの安全性保証を任せていた場合には既に発生していたオーバーヘッドなので、性能面では実質的に何も失うものはありません。
assert()を使いDbC的なコードにすると、ユニットテストでは見つけられなかったバグを見つける事も可能になります。他の開発者がうっかり関数/メソッドの仕様をよく知らずに使ってしまった時にも何がおかしいのか直ぐに分かります。DbC用のコードを記述するオーバーヘッドは、デバッグの効率化で十分以上に補えるでしょう。
まとめ
正しく動作するプログラムにするには、可能な限り例外が発生しないような構造・仕様のコードを書く方が良いです。
避けられない例外もありますが、入力データが原因で発生する例外の多くがFail Fast原則を適用したデータバリデーションで避けられます。
呼ばれた方の関数/メソッド/APIが「まあ、何とかしてくれるだろう」といった作り方では、避けることが可能な例外処理まで行わなければなりません。例外処理が遅くなればなるほど、中途半端に処理されてしまったデータ/壊れたデータがシステム上に残ってしまいます。
Fail Fast原則に従い可能な限り早く、可能な限り厳格なデータバリデーションを行う、が正しく動作するプログラムには必要です。
https://blog.ohgaki.net/there-are-3-types-of-validations
https://blog.ohgaki.net/input-validation-disables-most-injection-attacks
https://blog.ohgaki.net/design-by-contract-and-trust-boundary