追記:解りづらい、とご指摘があったので「セキュアコーディング方法論再構築の試み」を再構築してみるとして書き直してみました。このエントリの方が詳しいですが、よろしければこちらもどうぞ。
セキュリティの専門家と呼ばれる人であってもセキュアコーディング/セキュアプログラミングを正しく理解していない例は散見されます。今回はそのケースを紹介します。
参考1:セキュアコーディングについて詳しくない場合、このブログを読む前にセキュアコーディング/セキュアプログラミングの歴史は理解しておた方が良いかも知れません。
参考2:そもそも、原理的/論理的に入力対策を無視/軽視したセキュリティ対策は誤りです。
参考3:前提知識として入力データには三種類しかなく、不正なデータはソフトウェアにとって百害あって一利無しのデータであることを知っている必要があります。

最近目に留まったセキュアコーディングを理解できていないケースはこれです。※以下、「スライド」と呼びます
http://www.slideshare.net/ockeghem/reconstruction-of-secure-coding-methodologies
セキュリティ専門家の仕事はソフトウェア開発者が間違えやすいケースを挙げて、間違えないようにするのも仕事の1つです。このスライドの内容を文字通りに理解すると、正反対になるように読めます。セキュアコーディング/セキュアプログラミングの基本概念/原則を曲解して解説しています。
このスライドの意図はコンピューターサイエンティストかつソフトウェアセキュリティ専門家1が考えているセキュアコーディング、特に入力バリデーションと信頼境界線の考え方が間違っている、あるいは効果的ではない、と理解させることだと思われます。
主な問題点
- 信頼境界線の考え方が間違っている
- 信頼境界線の引き方が理解されていない
- 信頼境界線に入力と出力があることが理解されていない
- 入力と出力のセキュリティ対策が独立であることが理解されていない
- CERTの資料を引用しているのに重要な事項が抜けている(出力対策は独立)
- OWASPのセキュアコーディングの資料として引用する資料が不適切
まず代表的なセキュアコーディングの解説としてCERT Top10 Secure Coding Practicesが紹介されています。このトップ10のセキュアコーディング/セキュアプログラミング原則は、その優先順位を含め、注意深く考えられた良い指針になっています。これを紹介するのは良いのですが、理解が全く間違っていたり、重要な部分を解説していません。
CERT Top 10 Secure Coding Practicesでは第1のセキュリティ原則として「入力をバリデーションする」を挙げています。第7のセキュリティ原則として「他のシステムに送信するデータを無害化する」を挙げています。
スライドでは項目名しか記載されていませんが、その内容は以下の通りです。
1. 入力をバリデーションする
全ての信頼できないデータソースからの入力をバリデーションする。適切な入力バリデーションは非常に多くのソフトウェア脆弱性を排除できる。ほぼ全ての外部データソースに用心が必要である。これらにはコマンドライン引数、ネットワークインターフェース、環境変数やユーザーが制御可能なファイルなどが含まれる。
7. 他のシステムに送信するデータを無害化する
コマンドシェル、リレーショナルデータベースや商用製品コンポーネントなどの複雑なシステムへの渡すデータは全て無害化する。攻撃者はこれらのコンポーネントに対してSQL、コマンドやその他のインジェクション攻撃を用い、本来利用してない機能を実行できることがある。これらは入力バリデーションの問題であるとは限らない。これは複雑なシステム機能の呼び出しがどのコンテクストで呼び出されたか入力バリデーションでは判別できないからである。これらの複雑なシステムを呼び出す側は出力コンテクストを判別できるので、データの無害化はサブシステムを呼び出す前の処理が責任を持つ。
重要な部分は太字にしました。入力対策と出力対策は独立した対策で、出力のセキュリティ処理の責任は出力を行うコードにある、ということです。SQLならSQLクエリを送信するコード、HTMLならHTMLを出力するコードが出力のセキュリティ対策を行う必要があります。
スライドの12ページ目ではこのように解説されています。
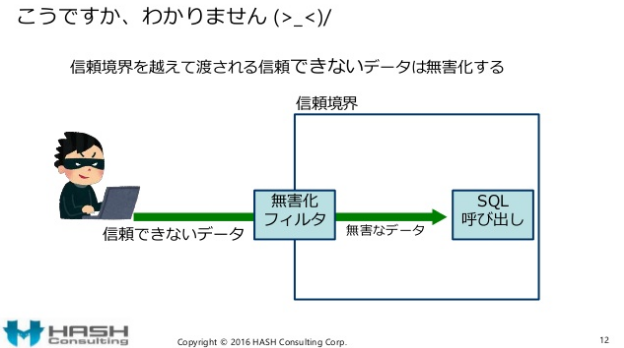
まず、入力はバリデーション(妥当性検証)するものです。入力は無害化するものではありません。(誰も入力を無害化すべし、とは言っていません。妥当性検証の後で結果的に無害になる物が多いですが、無害化は目的ではありません)
前述の通り、入力処理のセキュリティ処理と出力処理のセキュリティ処理は”独立”した対策であり、CERT Top 10 Secure Coding Practicesの出力処理のセキュリティ対策でも
- リレーショナルデータベースや商用製品コンポーネントなどの複雑なシステムへの渡すデータは全て無害化する
- データの無害化はサブシステムを呼び出す前の処理が責任を持つ
と明記されています。
次のページ(13ページ)では「こうですか、わかりません」と記載され×が付けれられています。入力のセキュリティ対策をすることだけがセキュアコーディングではありません。入力対策だけで、安全になるハズがありません。
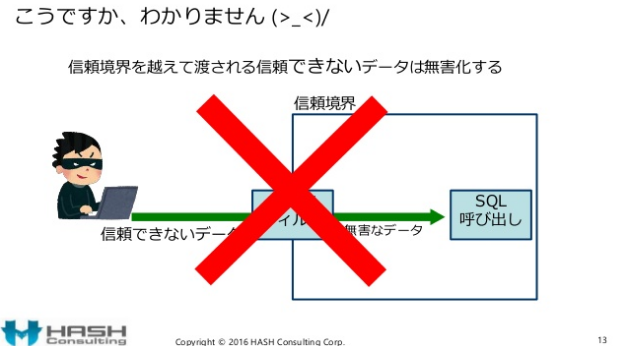
CERT Top 10 Secure Coding Practicesを紹介しているにも関わらず、
- リレーショナルデータベースや商用製品コンポーネントなどの複雑なシステムへの渡すデータは全て無害化する
- データの無害化はサブシステムを呼び出す前の処理が責任を持つ
(再掲)
を無視しています。
セキュアコーディング原則7に記載されているように、データの無害化はサブシステムを呼び出す前の処理が責任を持つので、入力処理はSQLコンテクスト(や他の出力コンテクスト)に出力する際の安全性に責任を持ちません。
入力処理は入力データの形式が内部のコードで処理可能であることを保障する処理です。出力の安全性とは関係がありません。
CERTが推奨するセキュアコーディングを行う場合、”入力処理”でデータ形式のバリデーションを行い、”出力処理”でSQLを出力先のコンテクストに合ったエスケープ/安全なAPI/バリデーションのどれか行います。両方実施しないとセキュアコーディングになりません。
スライド10ページではCERT Secure Coding StandardのJava版のIDS00-Jの解説を例に挙げて「こうですか、わかりません」という論理展開になっています。

IDS00-Jは前半部分で「信頼境界線を越える入力のセキュリティ対策(バリデーション)」を解説しています。
多くのプログラムは(中略)信頼境界(trust boundary)を越えて、信頼される側に渡す。(中略)不正な形式の入力データには対応できないかもしれない。インジェクション攻撃が含まれているかもしれないため、そのような入力は無害化(sanitize)しなくてはならない。
となっています。この説明にはCERT自身がセキュアコーディングの原則とした文書と競合する問題(”入力は無害化”と記載の部分)がありますが、入力バリデーションの事を解説していると考えられます。
”不正な形式の入力データには対応できないかもしれない”と書かれている事から入力処理の解説であることが分かります。無害化(sanitize)すべし、となっている”入力”にはCERT TOP 10 Secure Coding Practices(CERTセキュアコーディング原則)、本来なら第1原則の「入力のバリデーション」をすべきです。
”入力を無害化”は”入力を検証”あるいは”出力を無害化”とする所を書き間違えた可能性があります。CERT TOP 10 Secure Coding Practices(CERTセキュアコーディング原則)の第7番目は「出力の無害化」です。
※ この解説はあまり良い解説ではありません。相変わらず解りづらい記述ですが、現在のIDS00-Jはこのような解説ではありません。本来、セキュリティ専門家はこのような原則に反するようにも読める解りづらい解説を理解り易く、正しく解説するのが役割だと思います。原則1が「入力処理で入力バリデーション」、原則7が「出力処理で出力無害化」です。
中盤部分で「信頼境界線を越える出力のセキュリティ対策(エスケープ、安全なAPI利用、バリデーション)」が必要としています。
特にコマンドインタプリタやパーサに渡される文字列データはすべて、解析される文脈※で無害な状態(innocuous)にしなければならない。
※文脈とはコンテクストの事です。
”コマンドインタプリタやサーバに渡される文字列データはすべて”、にと”渡される”と記載されてることから、出力対策であることが分かります。
スライド19ページ目に「こうだった」と記載されていますが、
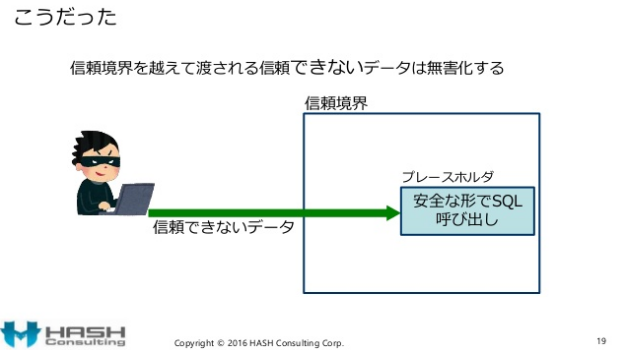
セキュアコーディング原則であるCERT TOP 10 Secure Coding Practicesでは、具体例として、そもそも独立した対策としてリレーショナルデータベースなの複雑なシステムへの出力は無害化する、と記載されています。
IDS00-Jの中盤部分でも「信頼境界線を越える出力の無害化、つまりセキュリティ対策(エスケープ、安全なAPI利用、バリデーション)」を行いなさい、と解説しています。
「こうだった」ではなく、そもそもCERTのセキュアコーディング/セキュアプログラミングの考え方では入力と出力のセキュリティ処理は独立した対策2であり、上の図の信頼境界線は”出力”の境界の対策になります。CERTの資料でも「出力時に無害な出力(安全なSQL呼び出し)」をしなさい、と書かれています。
しかし、CERT Top 10 Secure Coding Practices(セキュアコーディング10原則)には、決して出力対策だけでセキュリティ対策が完結するとも、出力対策が最も重要な唯一の原則であるとも、書かれていません。どちらか、ではなく独立した対策として両方必要だと書かれています。
「入力時と出力時のセキュリティ対策を同時に書くから解りづらくなっている」と思うかも知れませんが、IDS00-Jの記載は”信頼境界線”での”入力”と”出力”の対応方法が解説されていると考えて良いでしょう。こういう解りづらく、誤記があると思われる文章の場合、上位の原則やガイドラインからルールを導き出すべきです。
スライドでは出力対策の事だけが書かれていますが、信頼境界線には入力と出力があり、セキュアコーディングでは両方必要であることは明らかです。
根本的な部分にセキュアコーディングではないモノが多くて問題を指摘しきれないですが、幾つか簡単に誤りを紹介します。

CERT Top 10 Secure Coding Praticesの原則7「出力の無害化」でも同じことを書いています。
複雑なシステム機能の呼び出しがどのコンテクストで呼び出されたか入力バリデーションでは判別できないからである。これらの複雑なシステムを呼び出す側は出力コンテクストを判別できるので、データの無害化はサブシステムを呼び出す前の処理が責任を持つ。
ですが、CERT Top 10 Secure Coding Praticesの原則1では「入力をバリデーションする」としています。入力と出力の対策に限らず、セキュリティ対策は総合対策であり、どれかをすればどれかをしなくて良い、というモノではありません。
参考:”形式的検証”と”組み合わせ爆発”から学ぶ入力バリデーション (科学的なセキュリティ対策アプローチの話です)
セキュアコーディングの分類も出鱈目と言える分類になっています。

CERT Top 10 Secure Coding Praticesの原則1では「入力をバリデーションする」はコンピューターの動作原理から導き出された原則です。コンピューターは数値演算を得意としますが、コンピューターは数値演算さえ正しく行なえません。
ましてや、壊れたデータや大きすぎる/小さすぎる不正なデータは、そもそも正しく処理されることを期待するモノではありません。
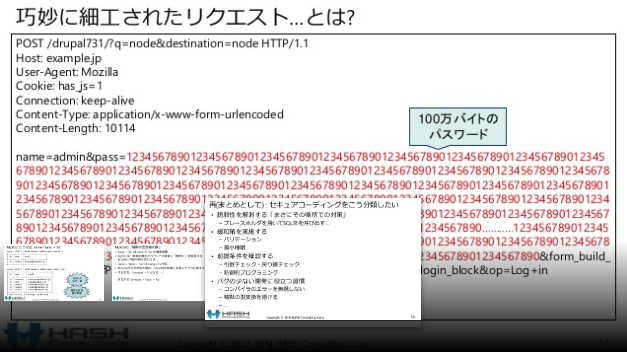
「100万バイトのパスワード」が正しい入力になるアプリケーションもあるかも知れませんが、普通のアプリケーションならパスワードには1000バイトも有れば十分です。
ある程度複雑なシステムで「100万バイトのパスワード」がシステム内でのどこで問題になるか正確に予想できる人は誰も居ないでしょう。ログシステムに不具合を起こすかも知れません。メッセージングシステムで不具合が発生するかも知れません。
明らかに異常で不正な「100万バイトのパスワード」を受け入れる事がそもそも間違いです。コンピューターは正しく処理できるデータでしか、正しく動作しないのですから。
スライドでは、入力処理で不正な値を受け入れてから、アプリ内部のライブラリ関数で不正な値を廃除するのがベストプラクティスであるように書かれています。
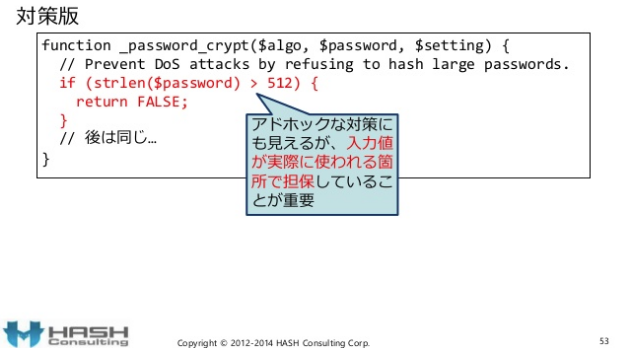
しかし、このようにライブラリの中”だけ”でバリデーションを行うのはベストプラクティスではありません。
バリデーションは、アプリケーションレベルだけで行うモノではありません。バリデーションは少なくとも3種類に分類され、”多層防御”で守るのがベストプラクティスです。
参考:バリデーションには3種類のバリデーションがある 〜 セキュアなアプリケーションの構造 〜
OWASP Top 10 Proactive Controls 2016を例に、対策の優先順位として入力バリデーションは優先度が低く、スライドの中では先の「100万バイトのパスワード」の例のように入力処理におけるバリデーションが不必要であるかのように書かれています。

OWASPの資料をセキュアコーディングにおいて入力バリデーションの優先順位とする根拠に使っていますが、OWASPのセキュアコーディングガイドでも入力バリデーションが第一番目の対策です。
入力バリデーションを第一位の対策としているのはCERT、OWASPだけではありません。NIST、CWE、CVEなどを運営している米のセキュリティ組織MITREやセキュリティ機関のSANSも第一位の怪物的セキュリティ対策としています。
他のスライドにも問題があります。
https://www.slideshare.net/ockeghem/php-conference-2017
詳しい解説は省略しますが、上記スライドの中ではデータベースが信頼境界の中に入った図で”間接SQLインジェクション”を使い、信頼境界線には意味がないかのような説明もなされています。
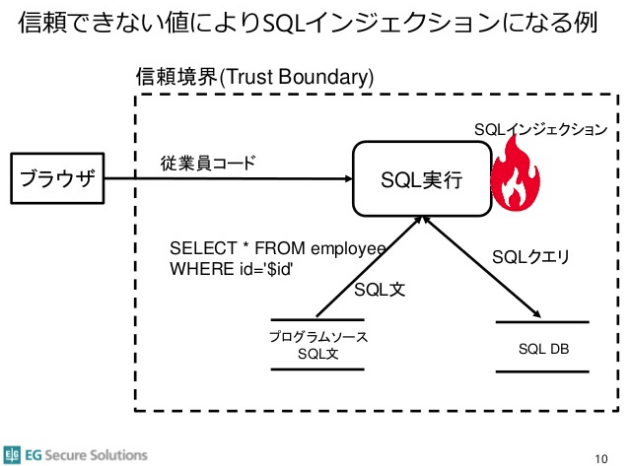
しかし、データベースも信頼境界線の外にある外部システムです。データベースを信頼境界線の中に入れてしまう間違いは、ソフトウェアセキュリティを理解していない場合に”よくある基礎的な間違い”の1つです。
ソフトウェアの信頼境界線とは「自分のコードの中と外」の境界が信頼境界線※になります。 ソフトウェア開発者にとって最も重要な信頼境界線は自分が作っているソフトウェアの入出力部分です。アプリケーションならアプリケーションへの入出力(ブラウザ、データベース、OSなど)、ライブラリならAPIの入出力が最も重要な信頼境界線になります。
※ 自分のコードで書いたモノ、コード中のリテラルなど、以外は全て信頼できないモノです。
セキュアコーディングの話でなぜ繰り返し「信頼境界」の話がでてくるのか?それは「信頼境界の引き方と守り方」は「セキュリティ設計」そのモノだからです。
以下はソースコード検査に耐えるコードとは?の25ページの画像です。赤い枠が正しい信頼境界線の引き方/考え方になります。(モジュール/関数レベルでの入出力の考え方は24ページ参照)
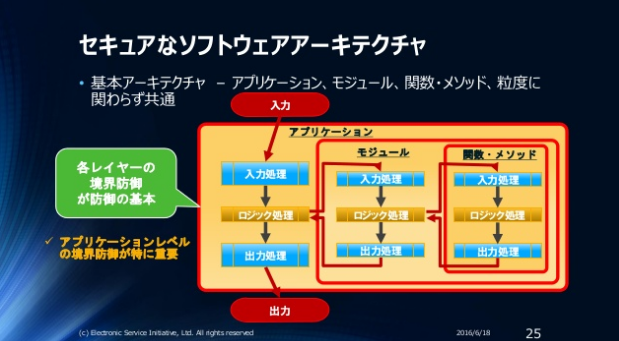
スライドの中では”セキュアプログラミング/セキュアコーディング”のガイドとしてOWASP Top 10 Proactive Controlsが紹介されていますが、OWASPのセキュアコーディング/セキュアプログラミングガイドと言えば、OWASP Secure Coding Practices – Quick Reference Guideです。
OWASP Top 10 Proactive Controlsは実際の開発を行う場合で実施すべき行動(制御 – Contorl)のガイドと捉えるべきでしょう。 現在のOWASP TOP 10は特定の脆弱性にフォーカスしたガイドになっています。例えば、最初のOWASP Top 10(Webアプリ脆弱性のTop10)は、入力バリデーションが第1の脆弱性としていましたが、脆弱性に焦点を当てるためにリストから削除しています。これは入力バリデーションが脆弱性を排除/緩和する範囲が大きすぎる3こと、このスライドで取り上げているような形で「入力バリデーションだけしていればOK」と誤解/曲解されるケースがあること、が理由だと思われます。
参考:OWASPに対して失礼な誤解 – 入力バリデーションは重要なセキュリティ対策
信頼境界線、入力と出力対策など、セキュアコーディングの考え方を正しく理解すれば、脆弱性に詳しくなくても、初心者でも、自動的により安全なコードが書けるようになります! 本物のセキュアコーディングを実践しましょう!
根本的におかしなセキュリティ対策になってしまった原因は「本当のリスク分析」をした事がない可能性が高いです。リスク分析はセキュリティ対策の基本です。恐らく「ブラックリスト型で判っている脆弱性リスクだけに対応するのがセキュリティ対策/リスク対策」と考えてしまったのだと思われます。
解りづらい場合、ネットワークのセキュリティ対策と比較してみる
ソフトウェアの最も外となる信頼境界線での入力対策を行わない「入り口ノーガード設計」を採用することは
- 入り口対策がないファイアーウォールで会社のネットワークを守る
ことと同じです。
入力対策がないファイアーウォールでネットワークの安全性を保つには、ネットワーク上のデバイス全ての既知/未知の脆弱性を修正しなければなりません。これにはトンデモないリソースが必要であるとともに、現実性もありません。
ソフトウェアも同じです。ソフトウェアの最も外の信頼境界線で入力対策を行わない場合、自分が作っているソフトウェアの脆弱性のみでなく、フレームワーク/ライブラリ/インフラまで含めた全ての既知/未知の脆弱性を修正しなければなりません。
ソフトウェアの最も外となる信頼境界線での入力対策を行わないで得をするのは、サーバー犯罪を行う犯罪者、アプリケーションファイアーウォールを売るセキュリティ業者、外部からセキュリティ検査をするセキュリティ業者だけです。ソフトウェア開発者もソフトウェアの利用者にも得になることはありません。強いて挙げるなら、セキュアな構造に必要な入力対策を省略して開発コストが少し低くなるように見えることくらいです。(しかし、適切な入力バリデーション無しで同じレベルの安全性を保障したい場合、コストは跳ね上がります。ネットワーク内のデバイスの安全性を完璧に保つことに膨大なコストが必要であること、と同じです)
セキュアコーディングが要求する厳格な入力バリデーション(入り口対策)にはコストが必要ですが、その他のコストやリスクを考えると安いモノです。
アプリには入力は数も多いし、変化するので入力バリデーションは現実的でない!と主張される方も居るかも知れませんが、オブジェクト指向言語にインターフェース機能があるようにインターフェースは比較的安定していて少数です。多数のデータの入り口があっても、データの種類は安定していて少数です。入力バリデーションはデータ型/オブジェクトのクラスを指定する事と同程度の作業量で定義できます。
ネットワークの入り口対策が内部ネットワーク内の未知の脆弱性に対応できる事と同様に、入力バリデーションは未知の脆弱性にも対応できます。ソフトウェアに潜む未知の脆弱性を全て洗い出すコストは膨大で、実施は不可能です。仮に実現したとしても、アプリが利用するフレームワーク/ライブラリ/インフラは常に変化し続けるので継続的に維持するコストは膨大です。一方、入力バリデーションは確実に実現でき、確実にリスクを削減します。
書きたい事はまだまだ沢山あるのですが、ここまでにします。
参考:
まとめ
入力バリデーション(CWE-20)の解説がない、軽視するセキュアコーディング、は噴飯物のあり得ない解説です。
入力バリデーション以前のセキュアなアプリケーション作りの基礎中の基礎と言える考え方、他の分野のセキュリティ対策でも基礎中の基礎と言える考え方が
- ゼロトラスト – 検証なしに信頼なし
- フェイルファースト – できる限り早く失敗させる(=早く検証する)
です。これらに全く適合しない方法と考え方がセキュアコーディングとしています。これでは現代の複雑なアプリケーションは何時まで経ってもセキュアになりません。
重要な部分だけおさらいします。
- 信頼境界線の防御には入力と出力の二種類がある。
- データの無害化はサブシステムを呼び出す前の処理が責任を持つ。つまり入力と出力のセキュリティ対策は独立した対策であり、入力バリデーションの有無に関わらず、出力のセキュリティ対策は行うモノです。
- 入力対策と出力対策は両方行うモノで、それがセキュアコーディングの原則です。
- OWASP Secure Coding Practices – Quick Reference Guide がOWASPのセキュアコーディングガイドです。
ここで紹介した考え方はISO 27000/ISMSで要求されているセキュアコーディングの考え方になります。多少間違った考え方でもISMS認証が取れないことはないですが、顧客にISMS対応を要求されたソフトウェアで間違えるとと問題になる可能性があります。
このブログで紹介したような誤解が生まれる一因は、IPAのセキュアプログラミング講座の資料かもしれません。IPAの資料では世界標準で言うセキュアコーディング/セキュアプログラミングと「入力」と「出力」のセキュリティ対策があべこべになっています。(入力対策と出力対策が入れ替わっている。これだと混乱して当然です。古いIDS-00Jも混乱しているように見えます。)
入力と出力が反対になっているのは公的機関の資料として出鱈目がひどすぎるのでIPAには報告し、該当の資料は削除予定である旨の連絡を頂いていますが、今のところ削除はされていないようです。
※ IPAはセキュアプログラミング講座を2016年と2017年に改訂を行い、現在ではCERT Top 10 Secure Coding Practicesをセキュアコーディング/セキュアプログラミングの”原則”として紹介しています。つまり原則1が「入力バリデーション」です。構造がセキュアでなければ何時まで経ってもセキュアになりません。
参考:
- 出鱈目なセキュアコーディングの解釈が行われる原因はセキュリティ対策を原理、原則から考えていない、誤った原理、原則から考えていることが原因
- IPAは基礎的誤りを明示し、正しい原則を開発者に啓蒙すべき
- 構造化設計とセキュアコーディング設計の世界観は二者択一なのか?
-
- CERT Top 10 Secure Coding Practicesはカーネギーメロン大学に設置されたUS CERTで作成されています。US CERTはコンピューターサイエンティストらからなるITセキュリティの専門組織です。 ↩
-
- CERT Top 10 Secure Coding Practices(セキュアコーディング10原則)の7番目の「出力の無害化」で入力対策と出力対策は独立した対策である、と明記している。 ↩
- SANS/CWE TOP 25でもMonster Mitigations(怪物的セキュリティ対策)の一番目として入力バリデーションを挙げています。 ↩