セキュリティの原理、原則、ベストプラクティスに自分でコメントを追加しました。以前、論理的にセキュリティ対策を検証する方法や論理的なセキュリティ対策の評価方法は書いたのですが、論理的にセキュリティを構築する方法は書いていないことを思い出しました。追加したコメントと欠陥だらけのソフトウェアセキュリティ構造を紹介したブログをベースにセキュリティを論理的に構築する方法を紹介します。
このエントリの解説はCERT、つまり米カーネギーメロン大学、の資料をベースにしています。
原理、原則、ベストプラクティスの作り方
「原理、原則、ベストプラクティスの作り方」は、どの分野でも共通することです。
ベストプラクティスとは、ある結果を得るのに最も効率のよい技法、手法、プロセス、活動など、をガイドライン/ルール化したモノです。
何事でも論理的に何かのガイドライン/ルールを作る場合、まず変えることのできない
- 原理 – 事物・事象が依拠する根本法則
を見つけ、その原理から導き出される、比較的抽象的な
- 原則 – 多くの場合に共通に適用される基本的なきまり・法則
を作ります。変える事が難しい原理と原理から導き出した抽象的な原則を実装する具体的な事例として
- ベストプラクティス – 最良の実践法。最善の方法。
を作ります。原理、原則、ベストプラクティスを理解していないと様々な問題がおきます。これらの基本的関係は
原理 > 原則 > ベストプラクティス
です。何か矛盾が発生する場合、より上位の原理/原則に照らし合わせて論理的矛盾を解消します。
原理が間違っていると論理的に正しい原則/ベストプラクティスは導き出せない
当たり前の話ではないか!と感じるでしょう。しかし、「原理が間違っていると論理的に正しい原則/ベストプラクティスは導き出せない」を意識しないと、根本的な誤りをします。
よくある間違いには
- 原則と原理の取り違え(原理/仕組みから導く原則は、原理にならない。もし仕組みであるなら、それは原則ではなく原理となる)
- 原理その物の取り違え(原理とする物が間違っている)
があります。具体例を紹介します。以前にブラックリスト方式とホワイトリスト方式のセキュリティ対策について、次のような議論/考え方を耳にしました。
A氏の主張: 脆弱性を一つ一つ潰していくブラックリスト方式でも、全ての脆弱性を潰せば原理的に全ての脆弱性がなくなりセキュアになる。
セキュリティ対策は問題となるモノを直接防止/廃除する対策が根本的な対策であり、根本的対策の積み重ね、一つ一つの脆弱性防止/廃除こそがセキュリティ対策の本質である。ブラックリスト方式は直接脆弱性を防止/廃除でき、本質的な対策と言える。
ホワイトリスト方式の場合、セキュリティ問題となる原因を直接修正せず、場合によってはセキュリティ問題を隠蔽してしまう。原理的にホワイトリスト対策は脆弱性を直接防止/廃除できない点が優れた方式とは言えず、ホワイトリスト方式で隠蔽された脆弱性がいつ攻撃されるか分らない。
よってホワイトリスト方式のセキュリティ対策はブラックリスト方式より有効な方法ではなく、ホワイトリスト方式とブラックリスト方式のセキュリティ対策に優劣をつけるモノではない。
原理的に全ての脆弱性がなくならない限りセキュアな状態にはならず、ダメなモノを一つ一つ防止/廃除する方式のセキュリティ対策は優れたセキュリティ対策であると言える。
「なるほど!確かにその通り!」と思えるかも知れません。しかし、この考え方には重大な問題があります。
- 原理)全ての脆弱性がなくなるとセキュアな状態になる。言い換えると、全ての脆弱性がなくならない限りセキュアな状態にならない
確かに、一見するとこの原理として正しいように見えます。
コンピューターサイエンティストが考える原理的にセキュアな状態とは?
コンピューターサイエンティストは全て脆弱性を簡単に廃除できるとは考えていません。代わりにプログラムの構造に着目し、可能な限り「正しく動作する」プログラムを論理的/体系的に作ることを目標としています。
構造)粒度1に関わらず、プログラムは基本的に「入力」⇒「処理」⇒「出力」の構造を持っている。
コンピューターサイエンティストはある程度の規模を超えるプログラムになると、プログラムが完全にバグフリーであることを保証することが非常に困難である事実を認識しています。
事実)プログラムが正しく実行されることを論理的に証明することは困難
実際、21世紀になった今でも、プログラムが正しく実行されることを証明(数学的に正しく実行されることを証明)する研究に終わりは見えていません。
「関数型プログラミング言語はバグが少ない(バグフリーではない)プログラムを作れる」と言われます。これはプログラムの構造として、機能を数学的な関数として実装できることに由来しています。数学的な関数として実装された機能は数学的な手法を用いて、その機能が正しく実行されることを保証/証明できます。関数型プログラミング言語を使っても、数学的に実行の正しさを証明できるようにプログラムしなければ、手続き型のプログラミング言語と変わりがなくなります。
要するに普通のプログラムは正しく実行されることを数学的に証明することは、少なくとも現時点では、不可能であるという事実があります。
正しく実行できることは証明できない = 脆弱性のないプログラムであることも証明できない
どんなプログラムにも基本的に「入力」⇒「処理」⇒「出力」の構造がある事に着目し、入力/処理/出力に分けて”出来るだけ”セキュアな状態を作れるようにします。
”出来るだけ”である理由は、先ほどの紹介した通り”プログラムが正しく実行されることの証明は事実上不可能である”という現実からの制限です。
正しく実行できることは証明できない = 脆弱性のないプログラムであることも証明できない
だとすると「正しく実行させる努力」と「脆弱性を全て無くす努力」に変りがないのでは?と思うかも知れません。
- 「正しく実行させる努力」 – ホワイトリスト型のセキュリティ対策
- 「脆弱性を全て無くす努力」- ブラックリスト型のセキュリティ対策
ブラックリスト型のセキュリティ対策は構造的に漏れやミスを生みやすい欠陥があります。ダメなモノを全て羅列するより、コンピューターシステムにとって妥当であるモノを定義する方が遥かに容易です。
コンピューターシステムにとって妥当であるモノは仕様として決まっているからです。
入力処理
開発者が注意しなければならない入力処理は、開発者が何を開発しているのか?で変わります。アプリケーションプログラマならアプリケーションの入力、ライブラリのプログラマならライブラリの入力、に注意しなければなりません。
アプリケーションの場合、セキュアな入力処理は通常必須です。アプリケーションは独立したソフトウェアだからです。
ライブラリは独立したアプリケーションとは異り、アプリケーションの一部として動作します。ライブラリの場合はセキュアな入力処理を省略し、ライブラリを呼び出す側の責任にしても構いません。呼び出す側の責任にする場合、どのような入力値を渡さなければならないのか、明確に定義して徹底してもらう必要があります。
アプリケーションの場合にセキュアな入力処理が必須であるのは”ユーザー(攻撃者)に妥当な入力データを送信させること”を強制できないからです。
コンピューターサイエンティストが考えるセキュアな入力処理の”原理”
少なくともカーネギーメロン大学のコンピューターサイエンティストは「入力をバリデーションする」がソフトウェアセキュリティで最も重要な対策だと考えています。他のコンピューターサイエンティストにも異論はないはずです。もし異なる意見をお持ちのコンピューターサイエンティストが居る場合、教えていただけると助かります。
「入力をバリデーションする」が重要とする理由は以下の原理に基づきます。
原理
- コンピューターは妥当な入力データでしか正しく動作できない
- 攻撃者は不正な入力データ(妥当でない入力データ)でコンピューターを誤作動させようとする
- 入力データには3種類しかない。妥当なデータは、”正しいデータ”と”入力ミスのデータ”のみで、それ以外は”不正なデータ”
- ”正しいデータ”と”入力ミスのデータ”は”プログラム間でやり取りされるデータ仕様”によって明確に定義できる
ポイントは、データ仕様によってコンピュータープログラムが正しく動作するデータは明確かつ容易に定義できる、ことです。
過去に実際にあった議論に
- ブラウザから送信されるデータサイズは指定できないのだからサイズのバリデーションできない!
があります。
ほとんどの方は馬鹿げた議論だと感じるでしょう。Webアプリは1GBや2BGの”コメント”を受け付けて”正しく処理”する必要があるでしょうか?無制限にデータを送信できるからといってアプリケーション仕様として無制限に受け付けなければならない!そんなアプリ設計者の製品はマトモな動作はできないでしょう。2 ”正しいデータ”、”入力ミスのデータ”が定義もできないようではアプリ設計者とは言えません。
バリデーションの補足:
バリデーションは大別して3箇所で行います。つまりバリデーションには3種類あります。”入力バリデーション”は入力処理で行い、”ビジネスロジックバリデーション”はロジック、MVCならモデル、で行います。
”入力バリデーション”ではアプリが受け入れ可能(妥当)なデータのみを受け付けるようにします。これにはユーザーとのやり取りは必要ありません。”ビジネスロジックバリデーション”は受け入れたデータに論理的な間違い、入力ミスなどがないか確認します。
コメントなら入力バリデーションは「100KB以下、改行以外の制御文字を含まず、正しい文字エンコーディングのデータは許可」、ビジネスロジックバリデーションは「10KB以下ならOK、10KBを超えると入力ミス」などとバリデーションします。”入力バリデーション”と”ビジネスロジックバリデーション”は別のバリデーションです。
ただし、クライアントで10KB以下とチェックしているなら、入力バリデーションでも10KB以下のデータだけ、ユーザーとのやり取りなしでバリデーションし、ビジネスロジックでは入力データをそのままデータを使っても構いません。
勿論、10KB以下であることをチェックし、エラーメッセージを表示しても構いません。むしろ、多層防御&JavaScriptが無効であるケースなどを想定し、このように実装する方がお勧めです。
コンピューターサイエンティストが考えるセキュアな入力処理の”原則”
原理から導き出せる原則は以下になります。
原則
- コンピューターに処理させるデータは妥当なデータ(”正しいデータ”と”入力ミスのデータ”)であることを保障する
CERTのセキュアコーディング第一番目の原則「入力をバリデーションする」と同じです。
全ての信頼できないデータソースからの入力をバリデーションする。適切な入力バリデーションは非常に多くのソフトウェア脆弱性を排除できる。ほぼ全ての外部データソースに用心が必要である。これらにはコマンドライン引数、ネットワークインターフェース、環境変数やユーザーが制御可能なファイルなどが含まれる。
入力バリデーションの方法、管理方法は国際情報セキュリティ標準に2000年から記載されています。
コンピューターサイエンティストが考えるセキュアな入力処理の”ベストプラクティス”
原理と原則から導き出せるベストプラクティスは次のようになります。
ベストプラクティス
- ソフトウェアで処理される全ての入力データが妥当なデータ(”正しいデータ”と”入力ミスのデータ”)であることを保障し、”不正なデータ”は処理させない(処理を中止する)
- 妥当なデータであることはデータ仕様で決定できるので、データ仕様に合っているか検証することにより保障する(ホワイトリストで検証)
- ”ソフトウェアで処理される全ての入力データが妥当なデータ”であることを保障する為には、プログラム処理を行う前に妥当なデータであることを保障する(アプリケーションならアプリケーションが入力データを受け付ける部分で妥当性検証を行う=アプリケーション境界で境界防御を行う)
セキュアな入力処理の”原則”の補足:
”形式的検証”をご存知の方は”状態爆発”(組み合わせ爆発)を理解されていると思います。このような検証はコンピュータ時代より昔の1930年代くらいから科学者が研究しています。入力検証がない場合、”異常な状態”の数は爆発的に増え、制御(検証)不能なシステムになります。科学者にとって、”正しく動作するシステム”を作るためには”入力をバリデーションする”、は20世紀前半からの”常識”です。
入力処理のバッドプラクティス
原理、原則、ベストプラクティスから導き出せるバッドプラクティスは以下のようになります。
バッドプラクティス
- ソフトウェアで処理される全ての入力データの妥当性検証をせず、未検証のデータを処理させる
- 不正なデータを定義しようとするブラックリストを作成して対策する
- 全ての入力データの妥当性を保障できないビジネスロジック部分で妥当性検証を行う
(例:ActiveRecordパターンの場合、DBに保存するデータの妥当性検証の責任は持つが、それ以外のHTTPヘッダーや他の処理フラグなど、DBに保存しないデータの妥当性検証の責任は持たない。更に一般にActiveRecordパターンのモデルのデータ検証はDBにデータを保存する直前に行れる。この仕様では”ソフトウェアで処理される全ての入力データが妥当なデータ”であることを保障する”処理として不十分である)
残念ながらバッドプラクティスが広く実践されているのが、現在のWebアプリです。このような状況はセキュリティ専門家の責任、CTO/CSOなどマネジメントの責任が大きいと言わざるを得ないでしょう。
※ CTOの場合、セキュリティ問題が発生するとバッドプラクティスを放置していた責任を取らざるを得ないかも知れません。ISO 27000/ISMSだけ見ても2000年から18年間、具体的かつ実践的なセキュアな入力処理の記載し啓蒙してきました。
コンピューターサイエンティストが考えるセキュアなロジック処理
プログラムロジックはプログラムの本体であり、ロジックが正しく実行できることはセキュアなプログラム処理に欠かせません。
残念ながら、一般的にロジックの正しさを証明する方法がないので、理解り易く単純な原理や原則はありません。しかし、少しでもセキュアな状態に近づける為のガイドラインは作ることができます。
まず、”セキュアなロジック処理”の代表例を見てみましょう。
ロジックで起きる問題の例
- レースコンディション
- 認証/認可
- 不適切なメモリ管理
- 不適切な機能の利用
上記のような問題がロジック処理における問題の代表例です。
ロジックで発生する誤りは大別して2種類に分けられます。
- ロジックその物の誤り(アルゴリズムの誤り)
- ロジック実装の誤り(アルゴリズム実装の誤り)
プログラムが正しく実行できることの証明が誤りがない事の証明になりますが、この2つ両方ともに誤りが無い、ことを証明することは非常に困難です。もし、これらの誤りが容易に証明できるならバグフリーのプログラムを容易に作成できます。
セキュアコーディング標準
セキュアコーディング標準は少しでもセキュアな状態に近づける為のガイドラインです。CERTはセキュアコーディングの10番目の原則に「セキュアコーディング標準を採用する」があります。
利用する開発言語とプラットフォーム用のセキュアコーディング標準を開発/適用する。
稀にセキュアコーディング標準はコンピュータプログラムをセキュアにする為に役立たない、役立っていない、とする意見を見ます。しかし、これは大きな誤解です。
”セキュアコーディングを採用する”
は”CERTが開発したC/C++/Java言語用のセキュアコーディング標準を採用する”のではありません。
”自分の利用する言語/環境に合わせたセキュアコーディング標準をセキュアコーディングの原則に従って開発採用する”
これがセキュアコーディング標準を採用する、になります。現存するほとんどWebアプリはセキュアコーディング第一原則の「入力をバリデーションする」さえ行っていません。CERTのC/C++/Java言語セキュアコーディング標準に従っていたとしても、それではセキュアコーディングを採用こと、にはなりません。役立つ/役立たない、と議論する以前の問題です。
ロジックで正しく処理可能となる前提条件
ここで忘れてはならないのは、
ロジック処理が正しく動作する為の前提条件は
- 入力が妥当であること
です。
セキュアコーディング第一原則の「入力をバリデーションする」を行っていないコードは、基本中の基本、が抜けているコードになります。
コンピューターサイエンティストが考えるセキュアな出力処理
CERTのセキュアコーディングの7番目の原則は「出力を無害化する」です。
第7位 他のシステムに送信するデータを無害化する
コマンドシェル、リレーショナルデータベースや商用製品コンポーネントなどの複雑なシステムへの渡すデータは全て無害化する。攻撃者はこれらのコンポーネントに対してSQL、コマンドやその他のインジェクション攻撃を用い、本来利用してない機能を実行できることがある。これらは入力バリデーションの問題であるとは限らない。これは複雑なシステム機能の呼び出しがどのコンテクストで呼び出されたか入力バリデーションでは判別できないからである。これらの複雑なシステムを呼び出す側は出力コンテクストを判別できるので、データの無害化はサブシステムを呼び出す前の処理が責任を持つ。
細かい解説は省略します。太字の部分を一言で書くと「出力処理と入力処理は独立した処理で、出力時の安全性保証は出力処理の責任」です。
原理は入力処理の原理とほぼ同じです。原則は”攻撃者が送信してきた攻撃用データにより出力先で誤作動しないこと”=”全ての出力データを無害化する”です。ベストプラクティスも”全ての出力データを無害化する”です。
出力の無害化は出力対策の三原則(エスケープ/API/バリデーション)で無害化できます。
まとめ
まとめるとセキュアなアーキテクチャーは以下のようになります。
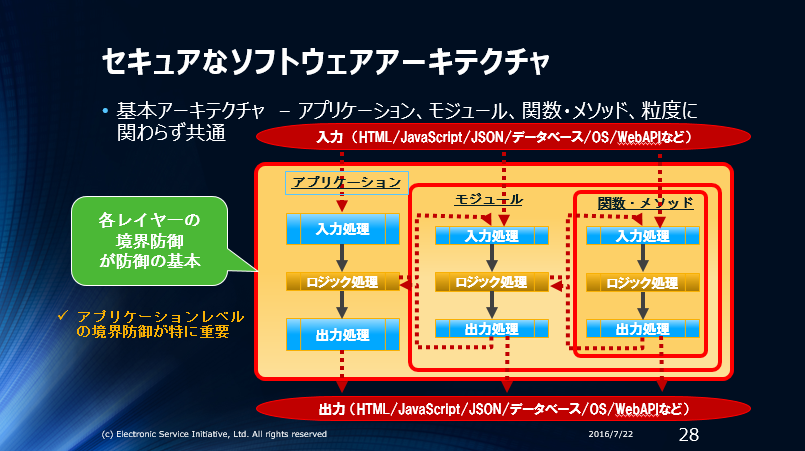
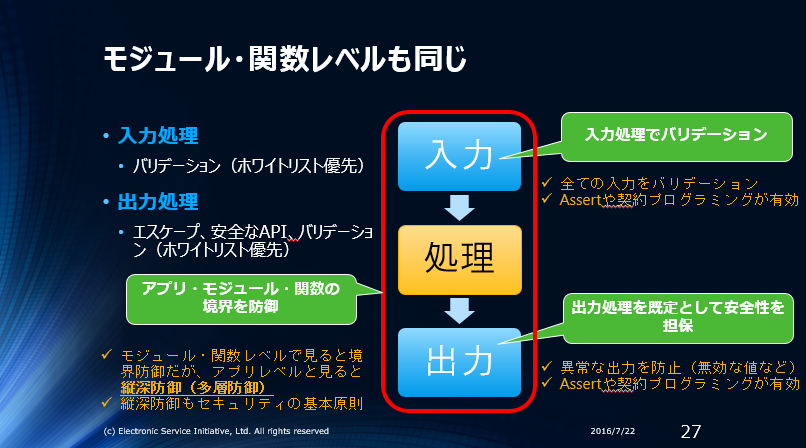
コンピューターサイエンティストが、原理から一般的な原則を導き出し、そこからベストプラクティスを導き出す論理的なセキュリティ構築の手順を紹介しました。同じように考えると、論理的に正しいセキュリティを構築できます。
”原理が間違っていると論理的に正しい原則/ベストプラクティスは導き出せない”で紹介した
- 原理)全ての脆弱性がなくなるとセキュアな状態になる。言い換えると、全ての脆弱性がなくならない限りセキュアな状態にならない
は原理として妥当ではありません。”全ての脆弱性がなくなると”(無くすことが出来る)は、コンピューターサイエンティストも国際セキュリティ標準を作っている人達も妥当だと考えていません。
ソフトウェアなどから”全ての脆弱性がなくす”は論理的には可能でも、現実的には不可能だからです。現実性のない前提条件を持つ原則に妥当性はありません。
実際、見つかった脆弱性を一つ一つ潰していく、といったアプローチでは許容可能にレベルにリスクを管理できません。ここで紹介したコンピューターサイエンスに基づくセキュリティ対策なら問題とならなかった事例は少くありません。最近の事例では、東京都の納税サイトから数十万件のクレジットカード情報が漏洩した事件が良い例です。
セキュリティの基本は「ゼロトラスト」です。何も信用してはならないです。自分自身もセキュリティ専門家もこのブログにも、どこに勘違いがあり間違っているか分かりません!自分で考えてみる、はとても大切です。
参考: