情報セキュリティ対策 ≒ リスクの分析、対応と管理、としても構わないくらい情報セキュリティ対策にとってリスク分析は重要です。体系的にまとめられたセキュリティ対策ガイドラインなら、どれを見ても記載されています。
情報システムは「モノ」(物と人)、「ネットワーク」、「ソフトウェア」で出来ています。それぞれリスクを分析、対応、管理する必要があります。
当然、ソフトウェアのリスク分析も重要です。しかし、多くの場合は「脆弱性対策」という形でリスク分析をせずにいきなり対応する、といったショートカットが開発現場で日常的に行われています。目の前にある問題に直ぐ対応しなければならない!といった場合も多いので仕方ない側面もあります。
しかし、問題は開発工程の早い段階で対応すればするほど、少ないコストで対応できます。システム開発に関わる人なら誰でも認識している事です。できる限り早い段階で早く問題に対応する、は情報システム開発の要求仕様のみでなく、セキュリティ要求仕様にも当てはまります。
※ このブログの説明はWebシステムを前提にしています。STRIDE、DREAD、リスクマトリックスなどのリスク分析手法はISO 31000等を参照してください。このブログでは単純なアタックツリー形のリスク分析を紹介しています。
リスク分析とは
情報システム開発におけるリスク分析の目的は「情報システムが正しく動作する(利用される)ことを確実にすること」です。正しく動作することを確実にできるセキュリティ要求を作るにはリスク分析が欠かせません。
リスク分析は欠かせません。簡単な分析でも、在るのと無いのでは大きな違いがあります。
情報システムのエンジニアなら「リスク分析」のような概念は体系的にまとめられているISO/JISを参照すべきでしょう。
JIS Q 27000:2014 (ISO 27000:2014)ではリスク分析は以下のように定義されています。
2.70
リスク分析(risk analysis)
リスク(2.68)の特質を理解し、リスクレベル(2.44)を決定するプロセス。
(JIS Q 0073:2010 の 3.6.1 参照)
注記1 リスク分析は、リスク評価(2.74)及びリスク対応(2.79)に関する意思決定の基礎を提供する。
注記2 リスク分析は、リスクの算定を含む。
これだけでは何のことかよく分かりません。リスク(2.68)の定義を見てみましょう。
2.68
リスク(risk)
目的に対する不確かさの影響
(JIS Q 0073:2010 の 1.1参照)
注記1 影響とは、期待されていることから、好ましい方向又は好ましくない方向にかい(乖)離することをいう (※ 良い影響、悪い影響の両方がリスクです。よく勘違いされるので注意)
注記2 不確かさとは、事象(2.25)、その結果(2.14)又はその起こりやすさ(2.45)に関する、情報、理解又は知識が、たとえ部分的にも欠落している状態をいう。
注記3 リスクは、起こり得る事象(2.25)、結果(2.14)又はこれらの組み合わせについて述べることによって、その特徴を記述することが多い。
注記4 リスクは、ある事象(周辺状況の変化を含む。)の結果(2.14)その発生の起こりやすさ(2.45)との組み合わせとして表現されることが多い。
注記5 ISMSの文脈においては、情報セキュリティリスクは、情報セキュリティ目的に対する不確かさの影響として表現することがある。
注記6 情報セキュリティリスクは、脅威(2.83)が情報資産の脆弱性(2.89)又は情報資産府ループの脆弱性(2.89)に付け込み、この結果、組織に損害を与える可能性に伴って生じる。
一つ一つの注記が大切な考え方の指針ですが簡潔にまとめると、リスクは組み合わせと発生しやすさ及びその結果(プラスとマイナスの両方)で考えるものと言えます。
- リスクは不確実性が変化するモノすべて(リスク≒不確実性)
- リスクは排除、緩和、移転、許容するモノで全てが管理対象となる
- リスクはシステム全体として許容範囲内に収まるよう管理する
リスク分析
リスク分析は構造に従って分析します。大抵のモノにはあるべき基本構造が存在します。
例えば、地震に対する建物のリスクを分析する場合は先ず地面に接している基礎のリスク分析を行います。基礎の上に建てられた建物がどんなに堅牢であっても、基礎が脆弱だと簡単に倒れたり倒壊してしまうからです。基礎が十分堅牢であると保証できて初めて建物のリスクを正しく分析できます。
建物の場合、基礎+基礎の上の建造物、という基本構造があります。
ソフトウェアの場合、入力データ処理 → 情報処理ロジック → 出力データ処理、という基本構造があります。
ソフトウェアには大きく分けて単体で(またはシステムとして)利用できるアプリケーションと単体では利用できないライブラリに分類できます。アプリケーションとライブラリはその特徴からセキュリティ設計が異なります。ここでは詳しく説明しませんが重要です。詳しくは次のブログを参照してください。
アプリケーションの構造
どんな建物も基礎+基礎の上の建造物、の基本構造を持っています。建物の核心/本体部分は「基礎の上の建造物」ですが、これが安全である為には構造的に「基礎」が十分に堅牢である必要があります。

アプリケーションも共通した基本構造を思っています。プログラムの核心/本体部分はプログラムが目的とする「情報処理ロジック(アプリ本体)」です。建物と同じように「情報処理ロジック(アプリ本体)」が安全(=正しく)動作するには「基礎(入力/出力)」の部分堅牢でなければなりません。

アプリケーションソフトウェアの基礎となる部分は「入力」と「出力」の処理です。ソフトウェアが正しく動作するには妥当なデータであることが必須の条件だからです。「入力処理」で妥当なデータであることを確実しないと、アプリケーションの情報処理ロジックは正しく動作しません。「出力処理」で出力先にとって妥当なデータであることも確実にしないと、出力先のシステムが正しく動作することを保証できません。
基礎がしっかりしていないと上部の建造物が幾ら堅牢でも建物は不安定になります、ピサの斜塔のように。

ソフトウェアも同じです。アプリ本体が安定するには、基礎となる入力処理と出力処理が万全でないと不安定なシステムになります。

建物もプログラムも、本体部分は複雑です。基礎部分が脆弱で、それを本体で埋め合わせようとすると無用な複雑性を生みます。複雑性は不確実性=リスクを増やします。複雑性については後でもう少し詳しく説明します。
リスク分析の手順
まず核心/本体の部分である「基礎の上の建造物」や「情報処理ロジック(アプリ本体)」のリスク分析から、としたいところです。しかし、本体部分のリスク分析を先に行うのは無理かつ無駄です。
繰り返しますが、どんなに堅牢な建物を作っても、基礎がダメなら使い物にならないからです。
同様にどんなに堅牢(=正しい)なプログラムロジックを書いても、基礎がダメなら使い物になりません。コンピュータープログラムが期待していない出鱈目なデータを絶対に正しく処理できません。データの妥当性を確実にしないと、プログラムは正しく動作できません。本体部分のリスク分析を行う前に、基礎部分を確実にする必要があります。
建物もプログラムも、本体部分のリスク分析は複雑です。基礎部分のリスク分析は容易です。基礎部分でリスクを排除・緩和すると本体部分のリスク分析も容易になります。ここではリスク分析が容易な入力処理と出力処理に絞って解説します。
入力と出力のリスク分析
アプリケーションソフトウェアの構造に従ってリスクを分析します。先ずはアプリケーション全体のリスクをざっとリストアップしてみます。
アプリケーションソフトウェアのリスク
アプリケーションの基本構造は
- 入力処理 → 情報処理ロジック → 出力処理
です。
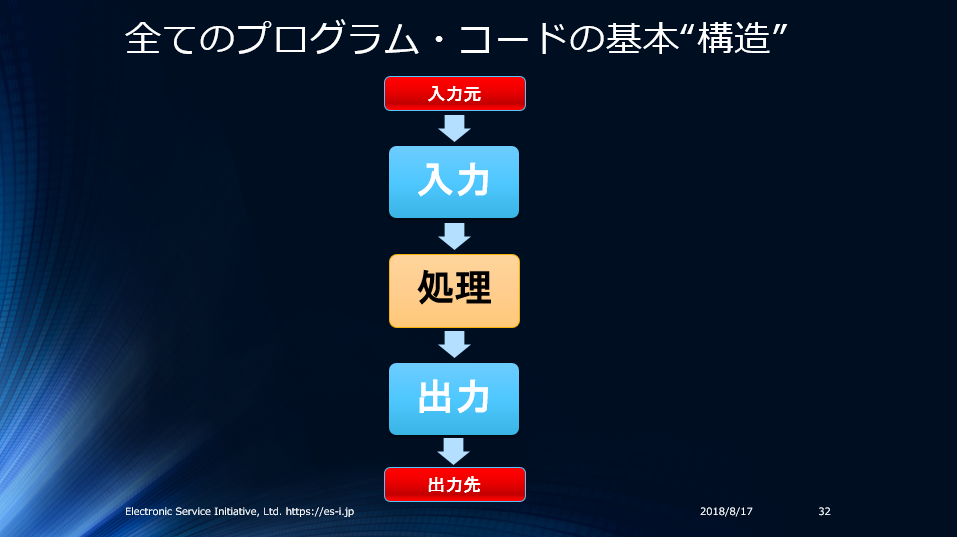
この構造に従って入力と出力データが持つリスクを識別してみます。リスクは不確実性、結果の起こりやすさ、であることを思い出してください。概ね発生頻度が高いと思われるモノを先に書きます。
アタックツリー型(大項目から詳細な項目に分類する方法)で漏れ無くリスクを識別するコツは
- できる限り抽象的なリスクから、具体的なリスクに細分化する
です。
リスク分析の目的は「情報システムが正しく動作する(利用できる)ことを確実にする」です。その目的を不確実にする不確実要素を全て取り上げる(識別)する必要があります。
まず「情報システムが正しく動作する(利用できる)ことを確実にする」ために必要な要素/条件/状態をできる限り抽象的なモノに分類し、それらが確実に全てのリスクを識別可能であること保証します。細分化されたリスクも全てのリスクを識別可能な分類になっていることを保証しながら、これ以上細分化できないレベルまで作業を繰り返します。
「確実に全てのリスクを識別可能であること」には簡単な論理検証手法が利用可能です。中学の数学で習った p ⇒ q、q ⇒ pが利用できます。
ここでは普通にリストアップするアタックツリー型にしますが、マインドマップを使うと便利です。リスクの定期レビューにもマインドマップの方が便利だと思います。
入力データのリスク
詳しく記述するとリストが大きくなりすぎて分かりづらくなるので、最初の方だけ詳しくリストアップします。
- 利用者が間違った入力を送信する
- 保存/処理できてしまう入力データ
- 機密性/完全性/可用性/信頼性/否認防止を失う
- 保存できる場合、間接攻撃状態に陥る
- 保存データを利用する際に攻撃と同じ状態に陥る
- インジェクション攻撃状態になる
- DoS状態になる
- システム内部情報の暴露が可能になる
- 不完全なデータが保存される
- 保存データが利用される場合にエラーとなる
- DoS状態になる
- システム内部情報の暴露が可能になる
- 不完全なデータが保存される
- 不完全なデータが保存される
- この項目の上位項目の「利用者が間違った入力を送信する」に戻る。
- 保存データを利用する際に攻撃と同じ状態に陥る
- 処理できてしまう場合、攻撃と同じ状態に陥る
- インジェクション攻撃状態となる
- 不完全なデータが保存される
- DoS状態となる
- システム内部情報の暴露が可能になる
- 処理のログが記録されない(インジェクション攻撃状態と同じ)
- 文字エンコーディングが壊れていて記録できない
(コピー&ペーストで発生する可能性がある) - 特殊文字が原因で記録できない
- 文字エンコーディングが壊れていて記録できない
- 不完全なデータが保存される
- 大きすぎるデータで攻撃された時と同じ状態になる
- DoS状態になる
- ログが記録できない
- 保存できる場合、間接攻撃状態に陥る
- 機密性/完全性/可用性/信頼性/否認防止を失う
- エラーとなる入力データ
- 機密性/完全性/可用性/信頼性/否認防止を失う
- 内部情報の暴露が可能となる
- 不完全なデータが保存される
(エラーで処理が停止する以前にデータが保存される) - DoS状態となる
- ログが記録されない
- 機密性/完全性/可用性/信頼性/否認防止を失う
- 保存/処理できてしまう入力データ
- 送信側システムの問題で不正/壊れたデータが送信される
- 保存/処理できてしまう入力データ
- エラーとなる入力データ
- 攻撃者が攻撃用の入力を送信する
- 攻撃者が直接攻撃用の入力を送信
- 攻撃者が利用者のデバイスを乗っ取る攻撃者が直接攻撃用の入力を送信
- (攻撃者が利用者の入力データを盗み見る)
- 攻撃者が利用者の入力データを改ざんする
- (攻撃者がデバイス上のデータを盗み見る)
- 攻撃者がデバイス上のデータを改ざんする
- 攻撃者が利用者のネットワーク経路の何処かを乗っ取る
- (攻撃者が利用者の入力データを盗み見る)
- 攻撃者が利用者に成り済まして入力データを送信
- 攻撃者が利用者の入力を中継、改ざんして入力データを送信
- 攻撃者が利用者を中継して入力データを送信
- 攻撃者が利用者の入力を記録、再生/改ざんして入力データを送信
- 攻撃者が利用者の接続を盗み取る
- 攻撃者が利用者のデバイスを乗っ取る攻撃者が直接攻撃用の入力を送信
- 攻撃者が間接的に攻撃用の入力を送信
- 利用者のシステムを経由して入力を送信(CSRFなど)
- システムに保存したデータを利用して入力を送信(間接攻撃)
- 攻撃者が直接攻撃用の入力を送信
- 送信側システムの問題で不正/壊れたデータが送られる
- ネットワークなどの問題で壊れたデータが送られる
攻撃する意図がない利用者からの入力データであっても、全ての可能性(不確実性)を検討すると様々なリスク(不確実性)があることが分かります。中には「こんなリスクは想定いなかった!」とリスクもあるかも知れません。
「でも、こんなリスト作ってられないよ!」と思ったかも知れません。大丈夫です。後でこんなに冗長なリストを作らずに済む方法も紹介します。
しかし、少なくとも一度は入力データのリスク対策が何もない想定で全てのリスクを網羅してリストアップするよう、開発者グループの勉強会などで挑戦することを強くオススメします。「こんな沢山のリスクを想定するのはゴメンだ! 不毛だ!」と思うハズですが、それを実体験することが重要です。
この入力データのアタックツリー型リスク分析はまだまだ不十分です。もうこれ以上分割可能なリスクは存在しない!となるまで分析するとが良いでしょう。
出力データのリスク
入力データのリスクをある程度細分化して記述したので、出力データのリスクは概要に留めます。入力データの「利用者が間違った入力を送信する」場合のリスク細分化の要領で細分化すればOKです。
- 出力先にシステム仕様に合わないデータを出力してしまう
- 保存/処理できるデータを出力
- エラーとなるデータを出力
- 出力先を誤作動させるデータを出力してしまう
- 不正操作を実行するデータを出力
- エラーとなるデータを出力
- 出力されたデータが保存できない
- 部分的に保存される
- 保存されていても表示できない
- システムの問題で不正/壊れたデータが出力される
- ネットワークなどの問題で壊れたデータが出力される
出力データのリスク分析は”出力先”に応じて行います。つまり出力先別にリスク分析します。SQLデータベースへの出力のリスク分析の場合、以下のブログが参考になります。
上記のSQLインジェクション対策は「完全」とタイトルを付けていますが、正確には「ほぼ完全」です。ブログの中でも書いていますが、リスクを省略している部分があります。何が足りていないのか、考慮すべき不確実性をリストアップするのも良い練習になります。(ヒント: 設定、出力先の不確実性など)
出力データのリスク分析も少なくとも一度は完全にリスクを細分化&網羅したリスク分析を行うことを強くオススメします。HTML出力のリスク分析は良い題材になると思います。
入力と出力データ以外のリスク
アプリケーションロジック処理のリスクは多くのリスクがあります。リストアップしだすとキリがありません。特にプログラムコードが正しく動作する為の必須条件である
- 入力データが妥当である
が保証できていない場合、無限にリスクがある、と言っても構わない状態になります。
入力データの妥当性を保証していない状態でのアプリケーションロジックのリスク分析は不毛で無謀です。
ここではリスク分析方法の説明が目的なのでアプリ本体(アプリケーションロジック)のリスク分析を詳しく説明しませんが、基本は同じです。
入力バリデーション無しで、アプリケーション全体の処理のリスク分析を網羅的に実施することは不可能です。しかし、部分的な処理のリスク分析なら可能です。比較的単純な処理をピックアップして、何の前提条件もない状態で完璧なリスク分析を一度は行うことを強くオススメします。
リスク分析を可能にするには?
自分で前提条件なしで「完璧なリスク分析」を実施しようとすると、
- 「こんなの不可能だ!不毛だ!無駄だ!やってられない!」
と思うハズです。こう思うのは当然でしょう。コンピューターサイエンティストは何十年も前から無理&無謀&無駄だと言っています。既に紹介したブログですが、こちらで簡単に紹介しています。
リスク分析を可能にするには前提条件を整る必要があります。
リスク分析の前提条件を整る
リスク分析を不可能にする程の不確実性を生じさせる最大の原因は未検証入力です。前提条件がないリスク分析を一度実施すれば否が応でも、未検証入力があると録でもない事になる、と実感できます。
プログラムのリスク分析に絶対必要な必要な前提条件は入力検証です。入力データが厳格にバリデーション済みであること、を前提条件にできるとリスク分析が比べ物にならないくらい簡素化できます。(リスク分析を簡素化可能=対応すべきリスクを削減=よりセキュアなプログラム、になります)
リスク分析には入力データの検証が必要と解ったので、その種類を分類して整理しておきます。
3種類の入力バリデーション
入力バリデーションには大別して3つの種類があります。既にブログにしているのでこちらをご覧ください。
入力バリデーションにもリスクがあります。このリスクも把握する必要があります。
入力バリデーションのリスク分析
入力バリデーションのリスク分析の参考になるブログも既に書いています。次のブログはリスク分析を直接のテーマとしていませんが、十分参考になると思います。
入力データのリスクを正確に把握するには、マシン語のインジェクション攻撃リスクも把握しなければなりません。これもブログがあります。
現実の業務に利用可能なリスク分析
リスク分析の前提条件である「厳格に入力バリデーション済みの入力データ」があれば実際に業務で使えるリスク分析が可能になります。
先に紹介した「利用者が間違った入力を送信する」のリスク分析は以下でした。
- 保存/処理できてしまう入力データ
- 機密性/完全性/可用性/信頼性/否認防止を失う
- 保存できる場合、間接攻撃状態に陥る
- 保存データを利用する際に攻撃と同じ状態に陥る
- インジェクション攻撃状態になる
- DoS状態になる
- システム内部情報の暴露が可能になる
- 不完全なデータが保存される
- 保存データが利用される場合にエラーとなる
- DoS状態になる
- システム内部情報の暴露が可能になる
- 不完全なデータが保存される
- 不完全なデータが保存される
- この項目の上位項目の「利用者が間違った入力を送信する」に戻る。
- 保存データを利用する際に攻撃と同じ状態に陥る
- 処理できてしまう場合、攻撃と同じ状態に陥る
- インジェクション攻撃状態となる
- 不完全なデータが保存される
- DoS状態となる
- システム内部情報の暴露が可能になる
- 処理のログが記録されない(インジェクション攻撃状態と同じ)
- 文字エンコーディングが壊れていて記録できない
(コピー&ペーストで発生する可能性がある) - 特殊文字が原因で記録できない
- 文字エンコーディングが壊れていて記録できない
- 不完全なデータが保存される
- 大きすぎるデータで攻撃された時と同じ状態になる
- DoS状態になる
- ログが記録できない
- 保存できる場合、間接攻撃状態に陥る
- 機密性/完全性/可用性/信頼性/否認防止を失う
- エラーとなる入力データ
- 機密性/完全性/可用性/信頼性/否認防止を失う
- 内部情報の暴露が可能となる
- 不完全なデータが保存される
(エラーで処理が停止する以前にデータが保存される) - DoS状態となる
- ログが記録されない
- 機密性/完全性/可用性/信頼性/否認防止を失う
「利用者が間違った入力を送信する」リスク対策の前提条件として、厳格に入力バリデーション済みのデータである(=アプリの処理ロジックに対して妥当)とすると識別すべきリスクは以下のようになります。
- 入力バリデーションが不十分
これだけで十分です。
前提条件が「厳格に入力バリデーション済みのデータである」であり、アプリケーションコードに対して妥当である(=正しく動作する)ことが保証済みだからです。「入力バリデーションが不十分」であるリスク(残存リスク)は別途識別し、リストアップすればOKです。既に紹介した以下のブログが参考になります。
残存リスクとその考え方:
直接は見えづらい残存リスク:
外部からの入力データは”全て”バリデーションする物
Webアプリケーションで最も数が多い脆弱性は未検証入力でしょう。圧倒的に多いです。
ここまで読んで理解頂いたのであれば「なぜ未検証入力が脆弱性なのか?」と疑問に思わないはずですが、もう一度簡単に説明します。
ISO 27000(情報セキュリティ管理標準)/ISO 31000(リスク管理標準)の定義では、不確実性は全て管理対象で、不確実性を増加させるモノは”全て”脆弱性です。不確実性の大きさは個々の不確実性とその発生頻度
- 全体の不確実性の大きさ = (不確実性1 * 発生頻度1)+(不確実性2 *発生頻度2)+ …
※ Σ(不確実性n * 発生頻度n)
で評価します。
未入力検証が生む/増加させる不確実性はある程度の規模のソフトウェアでは「無限にある」と言っても構わないほど多いことは、ここで紹介したリスク分析で明らかでしょう。入力箇所が多く、未検証入力が多く、入力を検証していても不十分、といったソフトウェアでは論理的に未検証入力のリスク(未検証入力の全体の不確実性)は、組み合わせ爆発により、無限大に近いと評価できます。
不確実性は末端で対応、とする考え方の欠陥
不確実性にできる限り上流で対応するのではなく、できる限り下流で対応するとする考え方もあり得ます。できる限り下流で対応しても、不確実性を減少させることが可能ですが、これだけでは欠陥があります。
アプリケーションの「未検証入力の不確実性をできる限り下流で対応する」(ライブラリやフレームワークにリスク対応を任せる)場合のリスク分析を行なえば欠陥が解ります。粗いリスク分析でも十分です。
「未検証入力の不確実性をできる限り下流で対応する」
- 未検証入力が残る
- アプリケーションのコード
- ライブラリ/フレームワークの入力検証機能の利用前のデータ利用
- あらゆるインジェクション攻撃に脆弱になる
- ライブラリ/フレームワークの入力検証機能の利用前のデータ利用
- ライブラリ/フレームワークのコード
- 入力検証が遅すぎる
- ライブラリ/フレームワークの入力検証機能が利用されない
- あらゆるインジェクション攻撃に脆弱になる
- 遅すぎる時点でエラーになる
- DoS状態に陥る
- ログが記録されない
- 不完全なデータが保存される
- ライブラリ/フレームワークの入力検証機能が利用されない
- 入力検証機能がない
- 組み合わせて使った場合に動作不良
- 十分な入力検証がない
- 仕様として不十分
- 組み合わせて使った場合に動作不良
- 入力検証機能に不備がある
- 仕様に問題
- ライブラリ/フレームワークが内部で未検証入力を利用
- 組み合わせて使った場合に動作不良
- 仕様に問題
- 入力検証コードの変更
- ライブラリ/フレームワークのバージョンアップ
- 入力検証コードの仕様変更見落し
- 検証コードの追加
- 検証条件の緩和/厳格化
- 検証コードの削除
- 検証タイミングの変更
- 入力検証コードの仕様変更見落し
- ライブラリ/フレームワークの変更
- 入力検証コードの仕様変更見落し
- 検証コードの追加
- 検証条件の緩和/厳格化
- 検証コードの削除
- 検証タイミングの変更
- 入力検証コードの仕様変更見落し
- ライブラリ/フレームワークのバージョンアップ
- 入力検証が遅すぎる
- アプリケーションのコード
これらを厳密に管理し、不確実性を十分に抑えなければならない、となると頭が痛くなります。
ライブラリやフレームワークは”汎用ソフトウェア”です。入力検証機能があっても”汎用的”な機能にならざるを得ません。そもそも仕様として入力検証機能がないモノも少なくないです。ライブラリやフレームワークに”専用ソフトウェア”であるアプリケーションの入力データ仕様に合った入力検証機能を求めることは不可能です。
仮にライブラリ/フレームワークが十分な入力検証機能があった、としてもライブラリ/フレームワークのバージョンアップや変更は頻繁に発生します。直接使っているライブラリなどが10程度だったとしても、それぞれライブラリが使用するライブラリが多数存在します。システムの基本ライブラリのバージョンアップ/変更まで含まれます。
- ライブラリ/フレームワークの入力検証機能の利用前のデータ利用
- 組み合わせて使った場合に動作不良
これらは”汎用ソフトウェア”部品であるライブラリ/フレームワークでは対応不可能です。
参考:文字エンコーディング検証は上流で実施する必要がある
不確実性の大きさは個々の不確実性とその発生頻度
- 全体の不確実性の大きさ = (不確実性1 * 発生頻度1)+(不確実性2 *発生頻度2)+ …
※ Σ(不確実性n * 発生頻度n)
なので、不確実性の数が管理不可能な程に多くなると言えます。「不確実性を末端で対応」するのは無理があり無駄で、入力検証が無い状態と同じ程度、致命的な欠陥がある状態と言えます。
※ ライブラリ/フレームワークにデータ検証機能/データサニタイズ機能がある場合でもそれに頼っていては、不確実性を十分に管理できないということです。一般にライブラリ/フレームワークのデータ検証機能に頼りきるのはアンチプラクティスです。しかし、フェイルセーフ機能として実装/利用し、多層防御を行うのはセキュリティ対策のベストプラクティスです。
リスク分析のポイント/コツ
究極のセキュリティ要求事項
- 情報システムが正しく動作することを確実にする
究極のセキュリティ要求事項は究極のセキュリティ対策の目的でもあります。正しい目的をしっかり定めてブレないようにしないと、目的から逸れてしまいがちです。リスク分析は手段であり目的ではありません。情報システムが正しく動作することを確実にできればOKです。
フェイルファーストとゼロトラスト
- フェイルファースト – 失敗するモノはできる限り早く失敗させる
- ゼロトラスト – 検証なしに何も信頼しない。信頼は検証の範囲内
セキュアなコードを書く際の基本的な心構え(原則)と同じです。
ホワイトリスト思考
- ホワイトリスト型の思考/セキュリティ
「セキュリティ対策」を考える際には、どうしてもダメなモノを定義するブラックリスト型の思考/セキュリティになりがちです。ダメなモノを定義すると容易に漏れ発生します。SQLインジェクション対策にはプリペアードクエリ/プレイスホルダだけ使えば良い、とする間違いもブラックリスト思考のセキュリティから生まれます。一つ一つ、全ての要素のリスクをホワイトリスト思考で識別します。
ホワイトリスト型セキュリティの最大のメリットは、もしリスク分析に漏れがあっても、他のリスク分析で既に対応できている、といった状態になることです。これは
- 識別していない(未知)のリスクにも対応できる
ことを意味しています。ブラックリスト型の場合、本当に全部のリスクを識別しないと漏れが発生し脆弱になります。
このブログでリスク列挙型の簡易なリスク分析を紹介したのは、複雑/詳細な分析方法だと容易にブラックリスト型のリスク分析になりがちだからです。
分割と統治
大抵のリスク管理標準/ガイドラインでは「リスク識別 → リスク対応」の順序で実施すると記載されています。しかし、全てのリスクを識別(分析)してから、リスク対応(セキュリティ対策)を考える必要はありません。上流から分割して「リスク識別 → リスク対応」を順番に行って構いません。
- 分割と統治(Divide and Conquer)
はコンピューターサイエンスの基本技法です。これを適用します。ソフトウェアの場合は以下のようにできます。
- 入力データのリスクを識別、リスク対応を決める(ロジック処理の前提条件)
- 上流のロジック処理のリスクを識別、リスク対応を決める(下流のロジック処理の前提条件)
- 下流のロジック処理のリスクを識別、リスク対応を決める(更に下流のロジック処理の前提条件) – 3を必要な回数、繰り返す
- 出力データのリスクを識別、リスク対応を決める(入力データとロジック処理のリスク対応が前提条件)
適切に分割しリスク分析を行うと、十分に分析可能な範囲に収まると思います。十分なリスクが分析(識別)可能となる、ということは十分なリスク対応(セキュリティ対策)が可能になることを意味します。
分割してリスクを考慮する場合、漏れも発生しやすくなります。上流のリスク対応で残ったリスク(残存リスク)がどのようなリスクなのか、正確に把握しながら分析する必要があります。(これはソースコード検査でも必要となる基礎的なセキュリティチェックの注意事項です)
「既にリスク対応済みだから」と「残存リスク」を無視/見逃してしまうケースはとても多いです。注意が必要です。
情報セキュリティの基本要素を利用する
情報セキュリティの基本要素は「機密性/完全性/可用性/信頼性/真正性/否認防止(責任追跡性)」です。これらに対する不確実性をすべて網羅しているか?確認しながら分析すると、リスクを網羅しやすくなります。
簡単な論理検証を行う
p ⇒ q、q ⇒ pによる簡単な論理検証だけでも、漏れている前提条件や論理的な齟齬を発見/検証できます。個々の不確実性(リスク)の細分化が適切であるか?チェックに利用するだけで、問題を発見しやすくなります。
CERT Top 10 Secure Coding Practices
CERT Top 10 Secure Coding Practicesはセキュアコーディングの基本原則ですが、リスク分析の参考にもなります。特に原則1(入力バリデーション)と原則7(出力の無害化)の考え方は参考になります。
リスク分析を始める前に理解しておくと効果的です。
契約プログラミング/契約による設計
契約プログラミング/契約による設計はプログラミング技法/設計技法ですが、考え方がリスク分析に役立ちます。特にアプリ本体ロジックのリスク分析には役立つと思います。(入力と出力も、ですが)
これもリスク分析をはじめる前に理解しておくととても役立ちます。
契約プログラミング/契約による設計を上手く利用するには、アプリケーションとライブラリの責任の違い、を理解しておくと良いです。
不合理な結論に致るメカニズム
人は容易におかしな結論に致る場合があります。リスク分析でもよくあることです。不合理な結論に致るメカニズムを知っていると、誤ったリスク分析を回避できる可能性が高くなります。
リスクを識別&列挙できないモノはセキュアにできない
情報システムセキュリティ管理の基本は
- 全てのリスクを識別&列挙、全てのリスクに対応&管理する
です。そして情報システムセキュリティ管理の目的は
- 情報システムを許容可能な範囲のリスクに抑えて利用できるようにする
です。「リスクを識別&列挙できない状態」では情報システムのセキュリティを維持できなくなるの当然と言えます。
入力バリデーションはセキュリティ対策ではない、セキュリティ対策として重要ではない、どちらかというとアプリ仕様である、リスク分析は必要ない、単純にバグとして直せば良い、などとする主張はセキュリティ対策/コンピューターサイエンスの基礎の基礎を無視してるか、理解できていません。ここまで読んで理解した方への心配は要らないと思いますが、惑わされないようにしましょう。
リスク分析は面倒/当たり前に感じるかも知れませんが、リスク分析がないことが原因で構造的な問題が修正されていません。リスク分析は難しくないので、何回かは自分自身で分析してみましょう。
勘違いしている開発者がいた場合、一緒にリスク分析をすれば間違いに気づくと思います。先ずは自分が最適であると考える構造でリスク分析を徹底的に行い、無理と無駄であると理解させ、次にセキュリティ標準/コンピューターサイエンスの考え方でリスク分析を行うと、標準/科学に基づく構造の方が比較にできないほど良いことが解るでしょう。
多くのシステムが基本を疎かにしていることが原因でかなりの無理と無駄をしています。この状態から利益を得るのは犯罪者とセキュリティ業者だけです。
おまけ:全ての開発者が今すぐすべきこと
これはリスク分析の話ではなくセキュアコーディング原則の話です。
入力対策(原則1)と出力(原則7)のリスク対応が十分にできていないのが現状です。入出力の堅牢化は開発者がリスク分析/対応の必要性の実感を伴わず、にルールとして実施するだけでも効果があります。
未検証入力を無くすだけでもリスクを大幅に排除/緩和できます。
入力データに合わせてバリデーション関数を作っても、入力バリデーションはフレームワーク/ライブラリ化しても構いません。
出力対策にも対策漏れが多いです。出力対策と入力対策は”独立した対策”として扱います。
関連: