データフロー分析とはコールフローグラフ(CFG)を使ってプログラムを分析する手法です。ソフトウェアのセキュリティ対策にもデータフロー分析は広く利用されています。例えば、静的ソースコード検査ツールは静的(=プログラムを動作させず)にプログラム実行時のデータフローを分析し、問題を発見する手法です。
コールフローグラフ

データフロー分析の基礎知識はハーバード大学コンピューターサイエンス学科の講義資料(PDF)が参考になります。こちらを参考にしてください。英語の資料ですが容易な内容です。
データフロー分析とセキュリティ
紹介した講義資料にも記載されている通り、データフロー分析の利点はその単純さにあります。実際のプログラムは抽象構文木(AST)で表現できます。しかし、ASTを利用したコード分析の場合、多数の入力と状態が変数となり現実的に分析ができない状態になります。
参考: 単純なコードでも組み合わせ爆発により形式的検証は不可能になる
”形式的検証”と”組み合わせ爆発”から学ぶ入力バリデーション
CFGを用いるデータフロー分析の場合、入力やプログラム状態を定数か定数に近い形で分析します。形式的検証の総当たり方式で検証する場合の”組み合わせ爆発”も起きません。ASTを直接分析するより遥かに単純で、分析可能になります。データフロー分析はプログラムが開発者の意図通りに正しく動作すること検証する為に利用します。セキュリティ対策目的には不正な動作か可能な箇所を見つける為に利用します。
セキュリティ検査にコールフロー分析を利用する
コールフロー分析を利用するとプログラムが持つセキュリティリスクを分析できます。組み合わせ爆発により、全ての無効な(=危険な/有害な)入力データパターン/アプリケーション状態パターンを分析することは現実的ではありませんが、脆弱なコードからデータフローとは逆方向に分析することにより脆弱なコードのリスク分析が行えます。
深刻なセキュリティ問題の多くは外部システム/外部コードへの出力コードで発現します。例えば、SQL文/OSコマンドを出力する脆弱なコードがSQLインジェクションやOSコマンドインジェクションが発生する箇所になります。SQLインジェクションもOSコマンドインジェクションも命令と引数さえ分離していれば大丈夫、ではありません。
完全なSQLインジェクション対策
コマンド実行時、コマンドと引数を分離すれば完璧?
SQLインジェクションに脆弱な出力コードが存在しても、必ずしも致命的な脆弱性とは限りません。例えば、PHPのpgsqlモジュールのプリペアードクエリ関数で
pg_query_params($db, ‘SELECT * FROM mytable
WHERE ‘. $_GET[‘search_column’] .’ = $1′, [$_GET[‘search’]]);
のように検索カラム名がパラメーターとなってるプリペアードクエリも安全である場合があります。
このクエリのリスク分析は、このクエリを呼ぶコールフローを逆から辿って危険な$_GET[‘search_column’]変数の埋め込みが安全であるか確認します。コールフローの何処かでSQL識別子として妥当であるか正しく検証されていれば安全です。例えば、
if (!preg_match(‘\A[a-z]\z’, $_GET[‘search_colum’]))
throw new Exception(‘Invalid SQL identifier’);
のようなコードが何処かに在れば安全です。
ほぼ全てのセキュリティ対策は何処か一箇所で行なえば十分、というものはありません。プログラムの基本構造(プログラムの機能ではない点が重要)に合わせた対策が必要になります。プログラムは妥当なデータしか正しく動作しないので、ソフトウェアセキュリティ対策の基本は”構造に則したバリデーション”(後述)になります。
現実のコードではコールフロー分析はあまり簡単ではない
先ほどのSQLクエリの例のように、SQL APIのプリペアードクエリ機能をほとんど直接利用している形であれば、リスクが発生している箇所は一目瞭然です。しかし、現実のアプリケーションではORMなどの抽象化ライブラリが利用されていることも多くあります。こういったSQLアクセス抽象化ライブラリではパラメーターはエスケープしたり、APIを使ったりして安全に処理しています。しかし、識別子はセキュリティ処理をしているとは限りません。OWASP TOP 10のA1では
注意:テーブル名やカラム名などのSQLストラクチャに対してはエスケープができない。
と、エスケープできない、とまで書いています。エスケープする抽象化ライブラリもありますが、実際に安全であるかどうかは抽象化ライブラリの仕様/コードを確認しなければなりません。
このように「リスクがあるコード」(≒ リスクがあるデータを処理してしまうコード)が在った場合には自分が書いたコード以外のコードの実装/コードまで検証しないと安全性を確認できません。
セキュリティ検査とデータフロー分析
Webアプリケーションのセキュリティ検査にはアプリケーション外部から動作を検査するブラックボックス型のWeb脆弱性診断とアプリケーション内部のソースコードを検査するホワイトボックス型のソースコード検査の2つに大別できます。
両方ともデータフロー分析を行いますが、基本的な仕組みが異なります。その違いがそれぞれのメリット/デメリットになります。
Web脆弱性診断
Web脆弱性診断の場合、攻撃用/診断用データをWebアプリケーションに送信し、その動作から脆弱性の有無を診断します。データフローを分析する、というより実際にデータを流してみて試してみる検査方法になります。
アプリケーションやアプリケーションが利用するライブラリ/フレームワークを知らなくても、実際にデータを送信&処理させるので、データフローを知らなくても(アプリ/ライブラリ/フレームワークの中身を知らなくても)検査できることがメリットです。
デメリットは全てのデータフローパターンを網羅することが非常に困難であることです。困難であることは組み合わせ爆発が起きることにより容易に確認できます。コードを見れば直ぐに判る問題でも検査から漏れてしまいます。
ソースコード検査
ソーコード検査を行う場合はデータフロー分析が欠かせません。一般的に使われるライブラリやフレームワークなどの仕様は予め調査して知っておくことが可能ですが、アプリケーションの仕様/ロジックはアプリケーション固有であるため、それぞれ異なります。少なくともアプリケーションコードのデータフロー(とデータバリデーション)を理解してコードの安全性を確認する必要があります。
ソースコードからデータフロー分析を行うと、アプリケーションのリスク管理状態が明白に解ります。データバリデーションが甘いこと、リスクが高くなっていること、セキュリティ標準/ガイドラインに準じていないこと、などがコードから直ぐに判ります。コードから不必要なリスクを生む構造/処理になっていないか確認できるため、的確かつ正確にリスクを減らすことがメリットです。
デメリットはデータフロー分析は簡略化した分析であるため、全てのデータフローパターンを網羅することができません。ライブラリ/フレームワークなどのAPIに仕様外のデータが渡されてしまうアプリケーション設計/構造の場合、検査工数が大幅に増えることがデメリットです。
集中型と分散型のデータバリデーションアーキテクチャー
Web脆弱性診断でもソースコード検査でも、完全な安全性を保証することは不可能です。しかし、どちらの検査方法でも厳格なデータバリデーションを行うことにより明らかに脆弱なコードから隠れた脆弱なコードまで、セキュリティリスクを大幅に削減できます。
プログラミングの基礎原則、プログラムの基本構造、攻撃可能面の管理、などを考慮すると、MVCモデルならコントローラーでバリデーションを行う集中型のデータバリデーションの方がセキュリティ対策としてより効果的です。しかし、多くのWebアプリケーションは主にモデルでデータバリデーションを行う分散型のデータバリデーションになっています。
参考:データバリデーションには3つの種類があり、何れにせよ分散したデータバリデーション必要です。しかし、入力に最も近いコントローラーレベルのバリデーションがない分散型のデータバリデーションアーキテクチャーでは、全ての入力を確実にバリデーションしていることを保証することが困難です。
バリデーションには3種類のバリデーションがある 〜 セキュアなアプリケーションの構造 〜
私はアプリケーション信頼境界(下の図の最も外側の境界=アプリケーション境界、MVCのコントローラーが処理する入力データ)で入力データバリデーションを行うアーキテクチャーを集中型、アプリケーション信頼境界で入力データバリデーションを行わないアーキテクチャーを分散型、と定義しています。
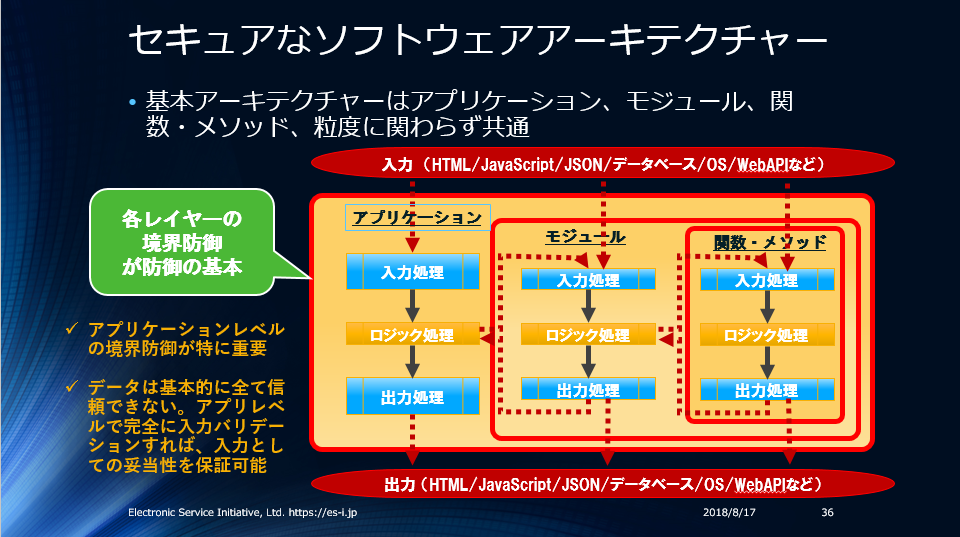
人によっては異なる定義だと思います。MVCのモデルでバリデーションする構造を集中型と定義している場合もあります。
しかし、モデルで”アプリケーションの入力データ”をバリデーションする場合、非常に単純なアプリを除くと、構造上どうしても1つのモデルで全ての入力をバリデーションできません。アプリへの入力処理に複数モデルが必要な場合も普通にあります。クエリパラメーターやHTTPヘッダーなどのデータをそもそもモデルで扱わないデータも多数あります。モデルでのデータバリデーションは一見すると集中型のアーキテクチャーに見えますが、必ず分散して”アプリケーションの入力データ”をバリデーションする必要があるので”分散型”としています。
分散型のデータバリデーションアーキテクチャーを持つアプリケーションの場合、データフロー分析によるセキュリティリスクの検証が困難になります。アプリケーション(自分が書いたコード)が直接入力データを使っていなくても、利用するライブラリやフレームワークが勝手に内部的に入力データを使ってしまう場合もあるからです。これはコールフローグラフによるデータフロー分析とリスク分析がかなり困難になることを意味します。言い換えるとコードからのリスク分析が困難になります。
攻撃用データを送信して脆弱性を診断するWeb脆弱性診断は中身の実装に関わらず、脆弱性を診断できるので「コードを見てリスクが判る/判らない」に関わらず検査が可能です。分散型のデータバリデーション構造を持つアプリケーションで、一部のコードを見てリスクが判らないコードであればあるほど(=脆弱な構造のコードであればあるほど)、Web脆弱性診断の価値が増します。
Web脆弱性診断はコードを見てもリスクが判らないプログラムの診断に向いている、とは言っても組み合わせ爆発のような現象が発生すること、無効なデータを処理してしまうコードは何をしても正しい処理にならないこと、などから未検証のデータを残してしまう仕様/構造は得策ではありません。
単純なアプリケーションであれば、モデルでデータバリデーションを行う分散型のデータバリデーションアーキテクチャーでも問題は少ないです。しかし、現在一般的な規模のアプリケーションの場合、集中型でないと効果的なデータバリデーションはほぼ不可能 = 効果的なリスク管理がほぼ不可能 = リスクが高い状態、となります。
ISO 27000、PCI DSS、OWASPのセキュリティガイド、MITREのセキュリティガイドでは「全ての(外部入力/信頼できないデータソースの)入力データをバリデーションすること」を要求しています。解りやすく言い換えると、全ての信頼できるセキュリティ標準/ガイドが最重要セキュリティ対策として入力データのバリデーションを要求しています。
アプリケーション開発者はこの要求に応える必要がありますが、既に説明した理由で分散型の場合は不可能です。
データフロー分析を容易にする2つのプログラミング原則
最も基礎的なセキュアプログラミング原則を2つ挙げるとすると以下になります。
- ゼロトラスト – 検証なしに何も信頼しない
- フェイルファースト – 可能な限り早く失敗させる
ゼロトラストとフェイルファースト
この2つを実践すると、コールフローグラフのパターンを大幅に簡略化できます。つまり、よりシンプルかつセキュアな状態を実現できます。
まとめ
「入力バリデーションは脆弱性を隠す対策だから良くない」とする信じ難い意見を聞いた事があります。
コンピューターサイエンスの基礎知識である、データフロー分析(コールフローグラフ分析)、形式的検証と組み合わせ爆発、などを理解していれば「入力バリデーションは脆弱性を隠す対策だから良くない」とする意見は非論理的で非常に危険な考え方であると理解できます。入力バリデーションによるデータ妥当性検証が無いとプログラムは正しく動作できない、という事実を無視する考えでもあります。
日常の一般的な開発業務ではデータフロー分析や形式的検証などを考慮せずに開発しているケースが多いと思います。それでも開発はできますが、効率的かつ効果的にセキュアで信頼性の高いアプリケーションを作るには、コンピューターサイエンスの知識が役立ちます。
コンピューターサイエンスというと小難しい印象があるかも知れません。しかし、データフロー分析や形式的検証のように、基礎部分はとても簡単です。そして基礎概念さえ知っていれば明日からでも実務に活かせます。知らないと損!こういった知識は身につけないと損だと思います。
参考:
ゼロトラストとフェイルファースト
セキュアコーディングの構造/原理/原則
エンジニア必須の概念 – 契約による設計と信頼境界線