 ビルドを繰り返して時間があったので、ついついとても長いデータの話を書いてしまいました。今さら聞けない「コード(機能)」と「データ」の話として、もっと単純化してみます。
ビルドを繰り返して時間があったので、ついついとても長いデータの話を書いてしまいました。今さら聞けない「コード(機能)」と「データ」の話として、もっと単純化してみます。
当然の話なのですが、現実には当たり前ではなかったりします。
「データ」のセキュリティを考慮しないセキュリティ対策はあり得ないのですが、多くのプログラムは「コード(機能)」のセキュリティに偏重した構造と対策になっています。
安全なプログラムの作成には「コード(機能)」と「データ」のセキュリティを分けて考える必要があります。
コンピュータープログラムが正しく動作する必須条件
プログラムが正しく動作する為には
- 正しいコードが絶対に必要
何を今さら当たり前のことを!と思ったでしょう。当然必要ですね。しかし、もう一つ絶対に欠かせない必須条件があります。
プログラムが正しく動作する為には
- 正しい(妥当な)入力データが絶対に必要
これも当然でしょう!と思ったかも知れません。コンピューターは数値でさえ正確に取り扱えません。コードが正しくても、整数のはずが数字以外の文字列だったりすると絶対に正しく動作しません。
不正なデータで動作し、不正なデータを保存/出力するようなアプリケーションは壊れている、とされても仕方ありません。しかし、このようなアプリケーションがとても多いです。
コードにとって正しい入力データとは?
プログラムにとって正しい(妥当な)入力データとは、以下の全ての条件を満す入力データです。
- データ型が一致する
- 数値なら妥当なデータ範囲である
- 文字列なら以下が妥当である
- 長さ
- 文字エンコーディング
- 利用する文字
- 文字列形式(日付、電話番号など)
- 構造を持つデータ(JSONやXML)なら以下が妥当である
- 構造の正しさ
- 構造内に含まれるデータの正しさ(上記の数値/文字列チェック)
- 引数の数が妥当である
- 引数の過不足がない
- 論理的整合性がある
静的データ型を持つコンパイラ型言語で記述したプログラムは最低限必要なデータ型チェックを自動的に行うので信頼性が高くなります。しかし、データ型の一致だけではコードは正しく動作しません。コンピューターは数値でさえ正しく処理することが原理的に不可能だからです。当然、文字列型の内容検証も必須です。
データに着目したアーキテクチャー
多くの場合、プログラムのアーキテクチャーは「機能」に着目して作られています。正しく動作するプログラムには、正しく実装されたコードが必要なので当たり前と言えます。
しかし、同時にデータに着目したアーキテクチャーも必要です。コードが正しく動作するには正しい(妥当な)入力データ必要です。言い換えると、不正な入力データでは絶対にプログラムは正しく動作できません。これはプログラムの動作原理です。
絶対に正しく動作しないと判っている入力データをプログラムに受け入れて処理するのは馬鹿馬鹿しいです。これらはできる限り早く廃除します。(Fail Fast原則)
上記の原理と原則からプログラムのアーキテクチャーを考えると、自然とこうなります。
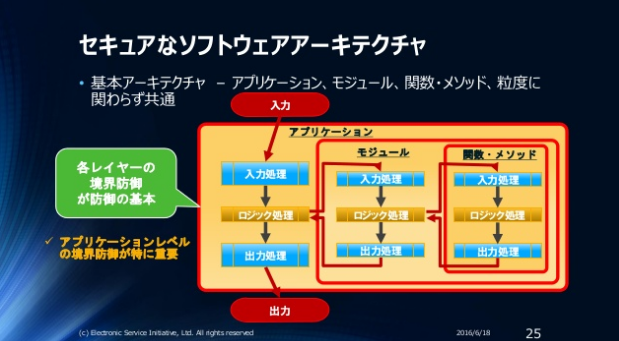
最大のソフトウェア信頼境界のアプリケーション境界(同じプロセス/スレッド上で動作するコード)までです。1アプリケーションレベルで入力データが正しい/妥当であることを保証するのが当たり前であることが解ります。
データに着目していないと、この図のように必須条件でさえ見落してしまう場合もあります。
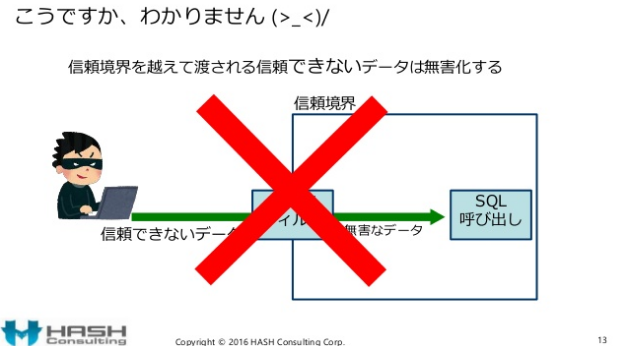
※ 入力データは正しさ/妥当性をバリデーションします。無害化するのは出力データです。(画像クリックで出典のslideshareに移動できます)
入力データの正しさ/妥当性の検証方法
入力データの正しさ/妥当性はホワイトリスト型で検証します。ブラックリストは脆弱な方法なので基本使用しません。入力妥当性検証における入力値の種類は3種類しかありません。

※ バリデーションする場合、「水色」の部分であることを保証し、他を無効として廃除します(処理を中止させる)
データの正しさには形式的妥当性と論理的妥当性があります。形式的妥当性はできる限り早く、論理的妥当性はできる限り早く、適切な場所で検証します。これがソフトウェアセキュリティの基本構造になります。
他人のコードにも正しいデータを送る
自分のコードに正しく妥当なデータが必須であることと同じく、他人のコードにも正しく妥当なデータが必要です。例えば、SQL文をRDBMSに送信する場合、SQLインジェクションできないだけ、では「正しく動作するプログラム」として不十分です。年齢に1万歳、などはあり得ない出鱈目なデータだからです。
参考: 正しいデータを送るには出力対策だけでは不可能=出力対策だけではセキュアなプログラムは書けない。
データのバリデーションは”入力データだけ”ではない
ここまでで正しく動作する為に必要なデータバリデーションが理解ったと思います。データバリデーションには三種類あります。
- 入力
- ロジック
- 出力
不正なデータはできる限り早く入力バリデーションとロジックバリデーションで廃除すべきです。しかし、特に高リスクのOSコマンド実行などではフェイルセーフ対策として「遅すぎるバリデーション」も行うべきです。
※ セキュアコーディング構造のアプリケーションの場合、出力時点では正しい(妥当な)データのみが出力されます。出力データの無害化が必要ない場合でも完全に無害化(エスケープまたはエスケープが必要ないAPIを利用)します。
正しく動作するプログラム(=攻撃できないプログラム)には、正しく妥当なデータが欠かせないので入念にバリデーションします。
攻撃者はデータに着目している
SQLインジェクションやJavaScript、OSコマンドインジェクションが出来てしまう原因の多くがデータにあります。
アルゴリズム自体(=処理手順)は間違ってはいないのに、おかしなデータが送られてきてしまし、それを処理してしまうからインジェクション攻撃が可能なプログラムになってしまっている、という構造はとても多いです。
攻撃者はプログラムにおかしなデータを送り付け、誤作動させることが可能な入力データがないか探してきます。
参考: 攻撃者はコードよりもデータに着目して攻撃してきます。何故なら出鱈目なデータをプログラムに送るのは簡単、適切なデータバリデーションを行っていないプログラムがほとんどだからです。
セキュリティ専門家もデータに着目している
セキュアコーディングの第1原則は
- 全ての信頼できない入力データをバリデーションする
です。第7原則は
- 全ての出力データを無害化する
です。
CERTのセキュアコーディング原則は正しく動作するプログラム(=攻撃できないプログラム)を作るためにCMUのコンピューターサイエンティストが考案した原則です。データの安全性(=正しさ/妥当性)をしっかり考慮した原則を定義しています。
Webアプリケーションの現実
2017年にOWASP TOP 10が改訂され、「不十分なロギングとモニタリング」が追加されました。これの必要要件には
- 攻撃者やセキュリティ業者がWebアプリケーションに送ってくるような不正なリクエストを検出できる
が含まれています。TOP 10プロジェクトとは別に、OWASP自身も長年セキュアコーディングを啓蒙してきたのですが浸透していません。
「入力バリデーションはできない」とか「入力バリデーションはセキュリティ対策ではない/重要ではない」といった、原理と原則を無視した議論があった影響も大きいでしょう。
Webアプリの信頼境界
Webアプリの信頼境界を図にすると以下のような図になります。
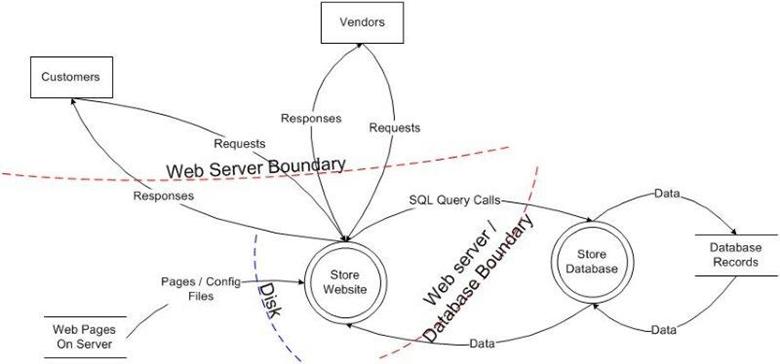
自分のプログラム以外から送られてくる「入力データ」は全て信頼できない入力データ2です。これらには
- HTTPヘッダー(CookieのHTTPヘッダー)
- URLのクエリ文字列
- POSTのパラメーター
- メール
- ファイル
- データベース
が含まれます。
「コード」と「データ」の両方をセキュアに!
コードだけ、では片手落ちで効果的にセキュアなコード(=攻撃できないコード)を書けません。
コードでロジックを作った次に、先ず第1にすべきは、データの正しさ/妥当性の検証である、と理解頂けたと思います。
正しく実行されるプログラム(=攻撃できないプログラム)には
- 正しいコードが絶対に必要
- 正しい(妥当な)入力データが絶対に必要
セキュアなアプリケーションプログラムには正しい「コード」と正しい「データ」の両方が必要不可欠です。
正しい「データ」が蔑ろにされてきた原因は色々考えられますが、そんな事より重要なことは
- 今のWebアプリケーションはセキュリティ対策で無視できない遠回りしている
点でしょう。攻撃できないプログラムの必須条件である、アプリケーションレベルでの入力バリデーションがない状態では大きな遠回り、と言われても仕方ありません。
幸いアプリケーションレベルの入力バリデーションは後付けで追加することが容易です。
参考:
-
- プロセス/スレッドをまたがる信頼鏡となる場合、それはソフトウェアの信頼境界図ではなく、ネットワーク(IPC含む)やファイルシステムを介したシステムの信頼境界図です。同じプロセス/スレッド内のコードでも、そのコードが検証済みでない場合は信頼境界の外にある、と考えます。また出力の場合、複雑なコード(正規表現ライブラリ、XML処理など)は検証済みであっても信頼できないコードとして取り扱います。(=可能な限り、できれば確実に、妥当なデータのみを複雑なライブラリには渡す) ↩
- 信頼できるデータとは「正しさ/妥当性」が保証されたデータです。例えば、通常プログラムファイルは信頼できるデータですが、これはプログラムファイルが第三者によって改竄されない、悪意のあるコードが含まれていない、といったことが保証されているからです。保証されていない場合、あらゆるファイルは検証されるまで信頼できません。 ↩