ISO 31000(リスクマネジメント標準規格)はa)からk)まで、11のリスク管理の原則を定めています。
ITエンジニアであればISO 27000(情報セキュリティマネジメント標準規格)を一度は読んだことがあると思います。少なくとも名前くらいは知っていると思います。リスク管理の基礎/基本を理解していればISO 27000だけでも十分ですが、ちょっと自信がない、体系的には学んだ事がない方はISO 31000も参考にすると良いです。
情報セキュリティマネジメントはリスクマネジメントの一分野です。一般論としてのリスク管理の基礎知識は役立ちます。
リスク対策の原則が知られていない?ことも、間違ったセキュアコーディング理解の原因かもしれません。間違いだらけのセキュアコーディング解説も紹介します。
ISO 31000:2009 (JIS Q 31000:2010)のリスク管理の原則
ISO 31000のリスク管理原則をそのまま紹介します。
a) 価値を創造する
b) 組織のすべてのプロセスにおいて不可欠な部分
c) 意思決定の一部
d) 不確かさに明確に対処する
e) 体系的かつ組織的で、時宜を得ている
f) 利用可能な最善の情報に基づく
g) 組織に合わせ作られている
h) 人的及び文化的要因を考慮に入れる
i) 透明性があり、かつ、包含的である
j) 動的で、繰り返し行われ、変化に対応する
k) 組織の継続的改善及び強化を促進する
現在のソフトウェアに足りていない物
ソフトウェア開発において不足しているリスク管理原則の代表例は「不確かさに明確に対処する」でしょう。その理由はほとんどのアプリケーションの入力バリデーションが不十分、出力の無害化も不十分だからです。
プログラムの基本構造は「入力」→「処理」→「出力」(以下、関数とします)で非常に単純です。プログラムの基本構造は単純ですが現在のITシステムは非常に複雑で、一見単純に見える処理でも膨大な数の関数を実行します。例えば、以下のような感じです。コンピュータで何が起こっているのか?かなり単純化した関数のコールグラフでも以下のような物になります。
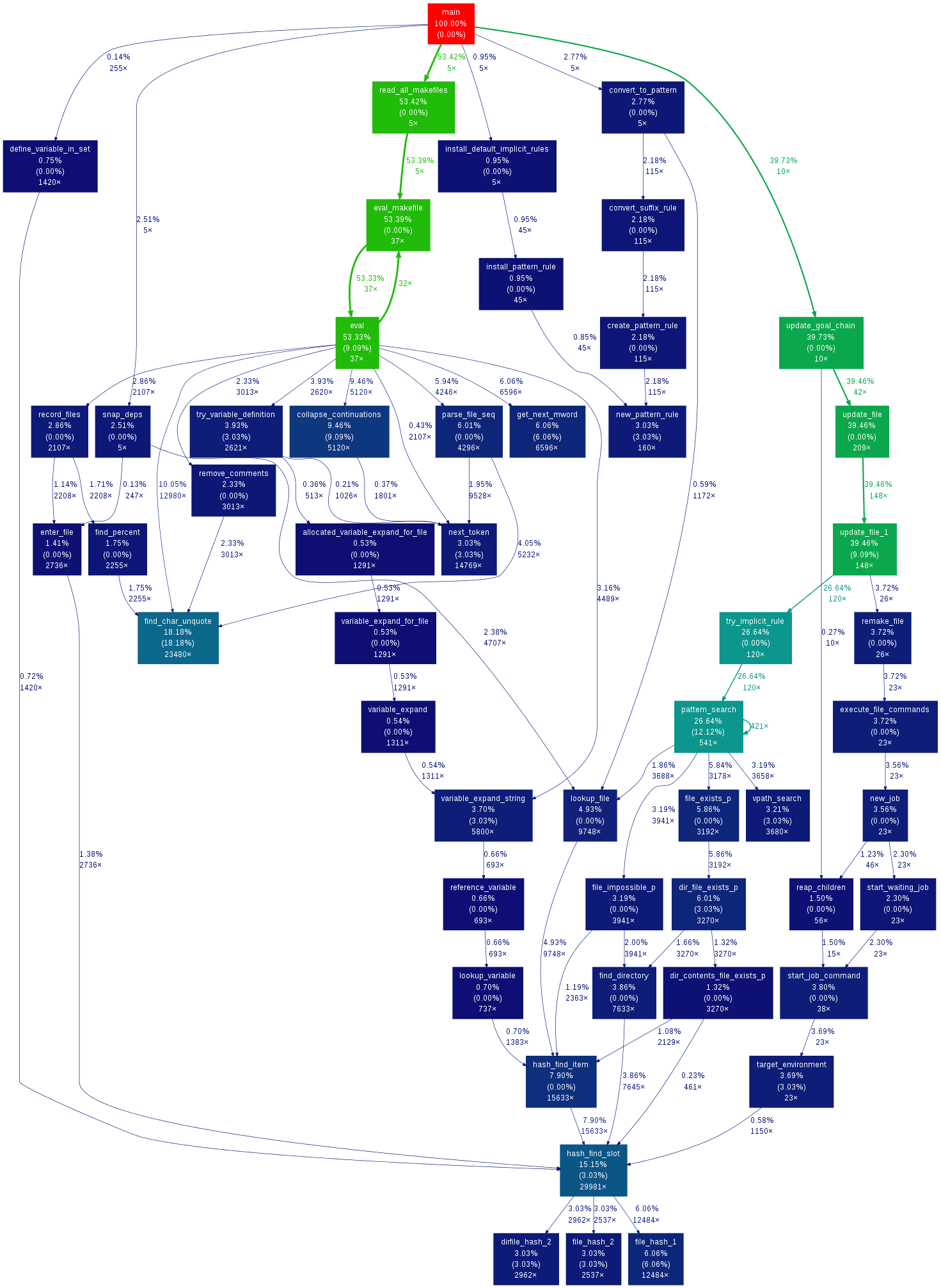
https://github.com/jrfonseca/gprof2dot
(Pythonプログラムのコールグラフなので、実際にはさらに多くのC関数やシステムコールが呼ばれている)
ソフトウェア単体でも非常に複雑ですが、アプリケーションの多くはさらに複数のソフトウェア・アプリケーションと連携して動作します。
現在のアプリケーションは個人が完全に動作を理解・把握し制御するには複雑すぎて「不確かさ」が大量に発生します。
不確かさに明確に対処する、とは?
ソフトウェアにおいて”不確かさ”を発生させる最大の原因は「バリデーション無しの入力」です。その理由は
- バリデーション無しの入力、アプリケーションが予期しない不正な入力、は”どこの”内部処理で”どのような”誤作動を発生させるか予見できない
からです。1OSのシステムコールレベルまで含めたアプリケーションのコールグラフを見て「これら全ての処理に”不都合なデータ”があった場合の動作を完全に保証できる」と主張できる開発者は一人もいません。一人もいないはずですが、もし居たとすれば物凄く勤勉な天才だけです。(ソフトウェアは次々に更新されるので、記憶力と理解力に長けた天才であるだけでは不十分です。すべてのソフトウェアの変更とその影響を完全に把握する必要があります)
プログラムは通常、妥当な入力に対して正常に動作するように作られテストされています。ソフトウェアの異常系のテストを網羅的に実施するには多大な労力が必要で、多くの場合異常系のテストは不十分です。不正な入力データは評価しようがない「不確かさ」を生みます。このため、セキュリティ標準/ガイドラインやCERTセキュアコーディングの原則では第一番目の対策として「入力バリデーション」を挙げています。
「入力バリデーションはセキュリティ対策ではない」とか「セキュリティ対策というよりアプリの仕様である」とするのはリスク管理/セキュリティ管理として意味不明、出鱈目な主張です。まともなリスク/セキュリティ専門家であればこのような主張はしません。入力バリデーションはソフトウェアのリスク排除・低減に欠かすことができないセキュリティ対策です。
CERTセキュアコーディングで七番目に重要とされている原則は「出力対策」です。コールグラフの複雑さを理解すれば「出力の安全性が完全に保証されている」ことの不確かさも理解できると思います。出力コンテクストは入力処理時には分からないこと、複雑なプログラムで処理後のデータの安全性は「不確か」なので「入力のセキュリティ処理とは無関係」に出力時にも完全に無害化します。
これらがセキュアコーディングの考え方です。2
参考:
間違いだらけのセキュアコーディングと信頼境界線の解説
現在のアプリケーション多くは基本的なセキュリティアーキテクチャーがない(適切な境界防御が無い)ので、セキュアコーディングなっていません。CERTのセキュアコーディングになっていない、アンチプラクティスを例に挙げて、「セキュアコーディングだ」とするのは出鱈目にも程があります。IPAが、CERTセキュアコーディングに基づく、まともなセキュアプログラミング講座を公開した2017年になっても、このような事があるのは残念でなりません。
https://www.slideshare.net/ockeghem/php-conference-2017
基礎から誤っているモノの場合、全ての間違いを指摘しきれないです。代表的な部分だけ指摘します。
まず、信頼境界線の書き方が間違っています。
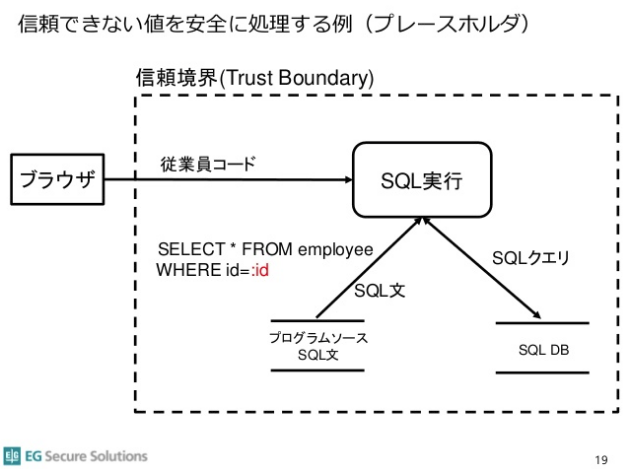
多くの場合、データベースシステムはWebサーバープロセス内のコードではなく、別のサーバープロセスです。仮にSQLite3のような組み込み型データベースであっても、CERTのセキュアコーディングの原則では複雑な処理を行う関数/機能は信頼できないモノとして取り扱います。この為、「ソフトウェアセキュリティの信頼境界線」を考えた場合、上記の信頼境界線はあり得ない引き方になります。
正しいソフトウェアアーキテクチャーレベルの信頼境界線の図は以下のような図になります。
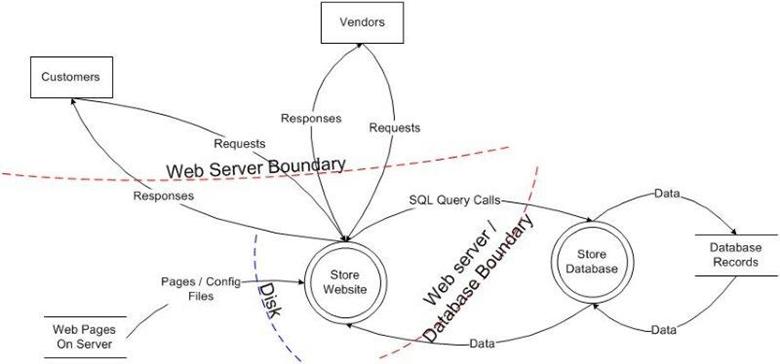
https://websec.io/2013/08/27/Core-Concepts-Trust-Boundaries.html
この図の場合、「Store Website」(Webアプリ)と「Store Database」(データベース)が正しく信頼境界線で分離されています。
間違ったソフトウェアの信頼境界線の図をもって
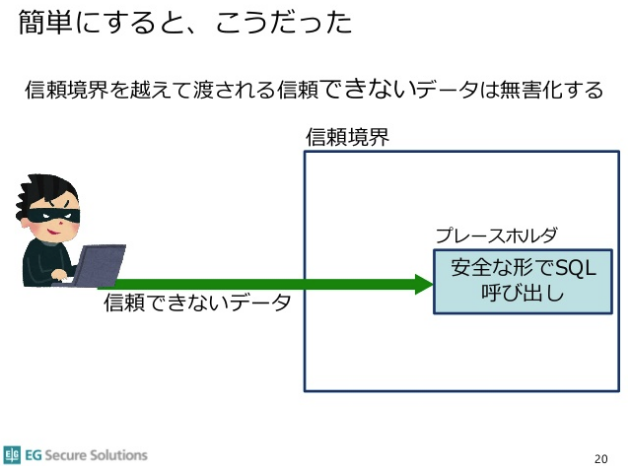

CERTのセキュアコーディングの原則に従うと信頼境界では
- 入ってくるモノを全て検証(原則1)
- 出ていくモノを全て無害化(原則7)
します。「そもそも関係なくね?」としているセキュリティ設計には原則1がありません。一番重要なセキュアコーディング原則が抜けています。従ってセキュアコーディングとしては明らかな間違いです。
- 入ってくるモノを全て検証(原則1)
これは、リスク緩和はもちろん、リスク管理原則の
- d) 不確かさに明確に対処する
為にも必要なリスク対策です。
入力/出力対策は信頼境界で行います。適切な信頼境界がないと、適切なリスク対策が行なえません。3
主な信頼境界線図には「モノ(物理的)」「ネットワーク」「ソフトウェア」、これら3をまとめた「システム」の信頼境界線図の4種類があります。
下の信頼境界線図(再掲)はプレゼンテーションのタイトルからソフトウェアの信頼境界図のつもりのようですが、アプリケーションとデータベースが一緒なのでソフトウェアの信頼境界図ではありません。
「関係なくね?」とする信頼境界線の図が間違っていては話になりません。
この図の場合、信頼境界線が関係ないのではなく、セキュリティ設計(信頼境界線の図)が間違っています。
ソフトウェアセキュリティ設計(ソフトウェアの信頼境界線設計)を行う場合には守るべき原則(論理的に導ける原則)があります。
- ソフトウェアの信頼境界はプロセス/スレッドを越えることはできない
「プロセス/スレッドを越えることはできない」は”最大の信頼境界がプロセス/スレッドまで”という意味です。4普通は”プロセス/スレッド内の一部分”がアプリケーションの信頼境界になります。
正しくソフトウェアの信頼境界線を書いた場合、次のような図になります。信頼境界では既に記載したとおりCERTのセキュアコーディングの原則に従い
- 入ってくるモノを全て検証(原則1)
- 出ていくモノを全て無害化(原則7)
これら両方を行います。
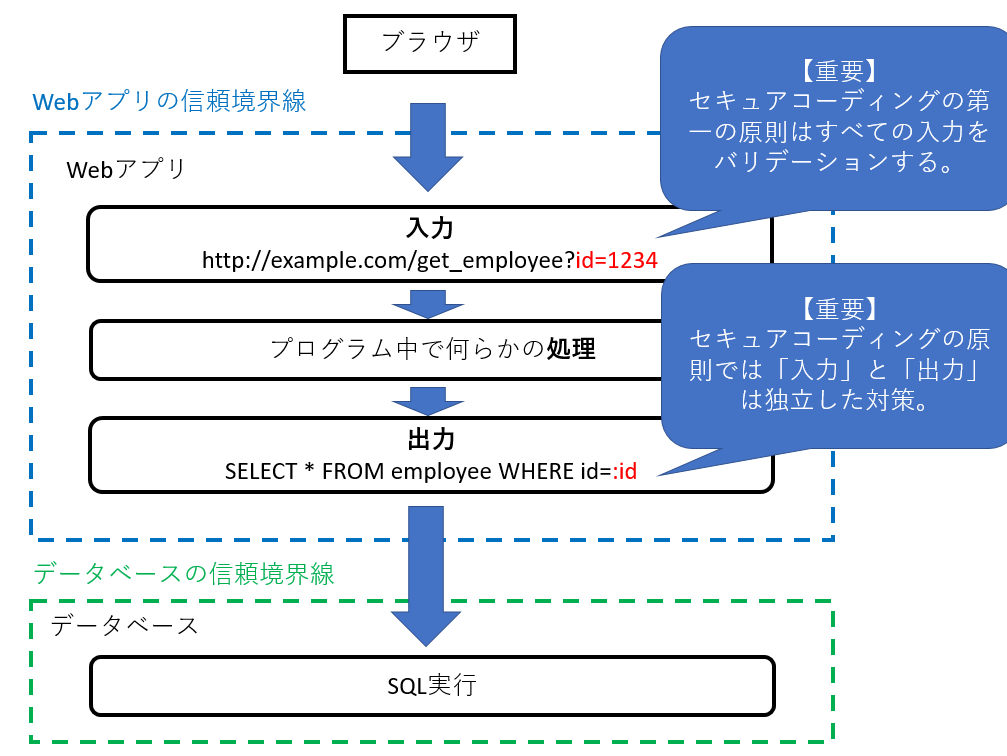
CERTのセキュアコーディングの出力対策の原則では「入力」と「出力」は独立した対策です。どちらか一方をすればよい、というモノではありません。「両方するモノ」です。よく勘違いされるようなので注意してください。
まとめ
IPAのセキュアプログラミング講座が改訂され”まとも”になると同時にCERTのセキュアコーディング習慣を「原則」として紹介しています。それに習ってここでも「原則」としました。
(セキュアコーディング/セキュアプログラミング本家のCERTでは出力対策は7番目の原則ですが、IPAでは2番目にしています)
セキュアプログラミング以前のプログラミング原則に「Fail Fast原則」(失敗するものは出来る限り早く失敗させる原則)があります。この原則に従う為にも入力バリデーションが不可欠です。
入力バリデーションをしていないソフトウェアを食品工場に例えると
- 腐った材料をラインに入れる
- ジャガイモ加工用のラインに魚を入れる
を許す事と同じです。いくら出力時に消毒(無害化)しても、腐った物や本来入っているべきでない物が入った不良品になります。5
基礎の中の基礎(ソフトウェアの境界防御やセキュアコーディング概念/原則、リスク管理の原則、etc)、が間違っているようでは十分に安全なソフトウェアが作れるはずありません。
CERTのJavaセキュアコーディング標準の一部を紹介しているにも関わらず、CERTのセキュアコーディング原則を紹介せず、CERTのセキュアコーディング原則やリスク管理の基本の”基”を無視した「モノ」がセキュアコーディング原則であるかのように紹介するのはとんでもない出鱈目と言わざるを得ません。6
CERTのセキュアコーディング原則は以下です。入力バリデーションが要らないかのような解説は完全に誤りです。
- 1. 入力をバリデーションする
- 2. コンパイラの警告に用心する
- 3. セキュリティポリシーの為に構成/設計する
- 4. 簡易にする
- 5. デフォルトで拒否する
- 6. 最小権限の原則を支持する
- 7. 他のシステムに送信するデータを無害化する
- 8. 縦深防御を実践する
- 9. 効果的な品質保証テクニックを利用する
- 10. セキュアコーディング標準を採用する
ところでプレイスホルダだけ使えばよい、エスケープなど教える必要はない、とするSQLインジェクション対策は大間違いです。まともなセキュリティ専門家ならそのようなことは言いません。詳しくは以下を参照してください。
https://blog.ohgaki.net/how-to-validate-logical-correctness-of-security-measures
-
- ”正しい入力データ”の場合だけでさえ、プログラムのバグを防ぐことは難しいです。”不正な入力データ”を処理してしまった場合も安全にするのは、かなりの手間が必要であり、できたとしても検証が困難です。この為、取り敢えずどんなデータでも受け入れて処理する、構造のソフトウェアは構造として脆弱です。 ↩
-
- セキュアコーディングの基本的な考え方です!とわざわざ説明するまでもなく、物理的なセキュリティ対策では「入るモノ」と「出るモノ」をチェックするのは当然すべき重要なセキュリティ対策です… がソフトウェアにはありません。 ↩
-
- 出力時だけの対策だと出力先に安全に保存できても「不正なデータ」が保存されたり、通常は発生しないエラーが起こったりします。たとえ安全に出力できても「不正なデータ」は不確かさを増やす要因です。 ↩
-
- データベースはストレージにデータを保存します。ストレージはプロセス/スレッドの外にあるモノです。基本的にはソフトウェアの信頼境界の中にはありません。 ↩
-
- 多くの方が既によくご存知の通り、セキュリティ管理は品質管理の一分野です。 ↩
- この説明のセキュアコーディングが「正しい」ISO 27000/ISMSのセキュアプログラミングだ、と思っていたら裁判になった時に契約で制限した以上の損害賠償金を支払う羽目になるリスクがあります。 ↩