セキュアコーディングに関して大きな誤解がある資料があったのでこのブログを書いています。
一つ前のブログは二つ以上の議論を理解しながら読まなければならないので解りづらい、とご意見を頂いたので”「セキュアコーディング方法論再構築の試み」を再構築してみる”として書き直してみました。
注意: CERTの文書ではサニタイズ(sanitize)は”危険な要素を取り除く”というブラックリスト型の対策ではなく、様々な方法(エスケープ/API/バリデーションなど)を利用してデータを無害化するという意味で使用されています。
「セキュアコーディング方法論再構築の試み」のどこが間違っているのか?
参考:セキュアコーディング方法論再構築の試み (Slideshare)
CERT Top 10 Secure Coding Practices(トップ10セキュアコーディング原則)はセキュアコーディングの本家と言えるCERTが作ったベストプラクティス原則です。知っている人には「セキュアコーディング=CERT」というくらい良く知られています。最も重要な第1の原則は入力バリデーションです。このページの通りです。

しかし、信頼境界線を議論するには入力と出力の両方を議論しなければなりません。第7位の”Sanitize data sent to other systems”(他のシステムに送信するデータを無害化する)が出力のセキュリティ対策ですが、スライドでは詳しく紹介されていません。
正しく理解するためには第1位の入力バリデーションと第7位の他のシステム送信するデータの無害化の中身を知る必要があります。CERT Top 10 Secure Coding Practicesの1位(入力対策)と7位(出力対策)の内容は以下の通りです。
1. 入力をバリデーションする(入力対策)
全ての信頼できないデータソースからの入力をバリデーションする。適切な入力バリデーションは非常に多くのソフトウェア脆弱性を排除できる。ほぼ全ての外部データソースに用心が必要である。これらにはコマンドライン引数、ネットワークインターフェース、環境変数やユーザーが制御可能なファイルなどが含まれる。
7. 他のシステムに送信するデータを無害化する(出力対策)
コマンドシェル、リレーショナルデータベースや商用製品コンポーネントなどの複雑なシステムへの渡すデータは全て無害化する。攻撃者はこれらのコンポーネントに対してSQL、コマンドやその他のインジェクション攻撃を用い、本来利用してない機能を実行できることがある。これらは入力バリデーションの問題であるとは限らない。これは複雑なシステム機能の呼び出しがどのコンテクストで呼び出されたか入力バリデーションでは判別できないからである。これらの複雑なシステムを呼び出す側は出力コンテクストを判別できるので、データの無害化はサブシステムを呼び出す前の処理が責任を持つ。
※ 重要な部分は太字にしました。
上のページは項目だけではよく解らない、ということだろうと思われます。CERTセキュアコーディング標準Java版の”入力値検査とデータの無害化”が該当するだろう、いうことで以下のページで紹介しているようです。

”入力値検査とデータの無害化”を下線付きで記載しました。これはセキュアコーディング標準Java版の”入力検査とデータの無害化“は入力と出力の両方を取り扱っているセキュアコーディング標準であることをより明確にするためです。
次のページで紹介されているIDS00-Jは入力と出力の両方を記載しています。(元のスライドに加工)

この文章は前半に入力、後半に出力のセキュリティ対策が記述されています。最初のパラグラフ初めに「情報源からデータを受け取り」とあり、入力対策であることが解ります。1ページ中央の「コマンドインタプリタやパーサに渡される文字列データはすべて」に「渡される」と記載され、出力対策であることが解ります。そして出力対策でも「データの無害化」を行うべし、としています。
信頼境界線を越えるデータには入力と出力の二種類がある点がポイントです。
次のページには信頼境界線のサンプルと思われる図があります。
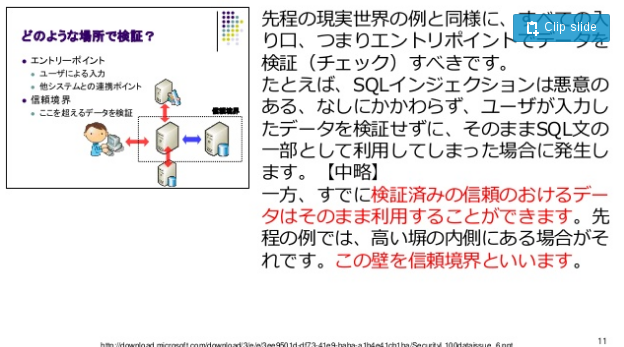
赤字部分の「検証済みの信頼のおけるデータはそのまま利用することができます」は、例外として確実に安全であることが検証され、安全性を100%保証できる場合のみ(開発者が静的に生成した設定ファイルなど)に適用できます。
しかし、ユーザーが登録した任意のデータが入っているデータベースには当てはまらず、無条件に信頼できるデータ(無条件に安全なデータ)として取り扱うことは決してありません。2
この信頼境界線の引き方は基本的な例として明らかに間違っています。データベースは外部システムであり、ソフトウェアセキュリティのコンテクストでは信頼境界線の外にあるシステムとして取り扱います。
ソフトウェアセキュリティに於ける基本となる信頼境界線は
- 特定のマシン内で自分(自分達)が書いたコードとそれ以外の境界線
です。3
上のページはネットワークセキュリティのコンテクストと混同してしまった間違いで、比較的よく見られる間違いです。ネットワークセキュリティの場合、信頼できるネットワーク機器をこの図のようにグルーピングすることがあります。ソフトウェアセキュリティの場合、プロセスやネットワークを跨ぐ信頼境界線は基本的にありません。
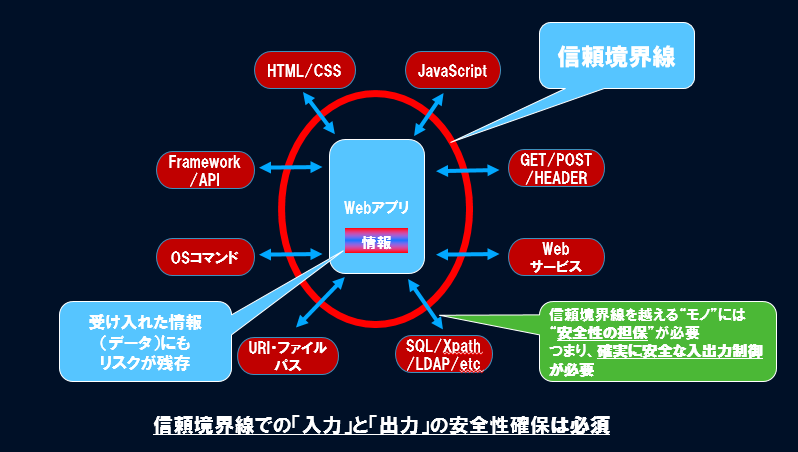
ソフトウェアセキュリティおける正しい信頼境界線の図は以下の図です。この図は話を簡単にする為、アプリ全体すべてを自分(自分達)が書いたコード&単一コンピューター上で動作している単一プロセスのソフトウェアである場合を想定しています。この場合、図で表すとこうなります。
間違った信頼境界線の例(11ページ)に続くページでは「こうですか、わかりません」と記載されています。
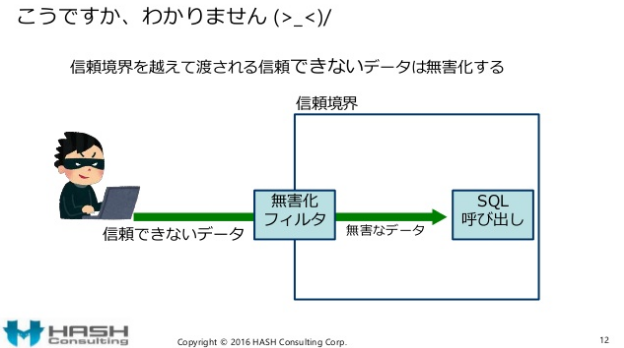
セキュアコーディングの考え方はこの図ではありません。
間違った信頼境界線の書き方である上、ソフトウェアの部分を入力→処理→出力と分割して考えるべきところを一緒にしているので、訳けが分からなくても当然です。
セキュアプログラミングの図としてこの図を見ると、何が言いたいのか全くわかりません。
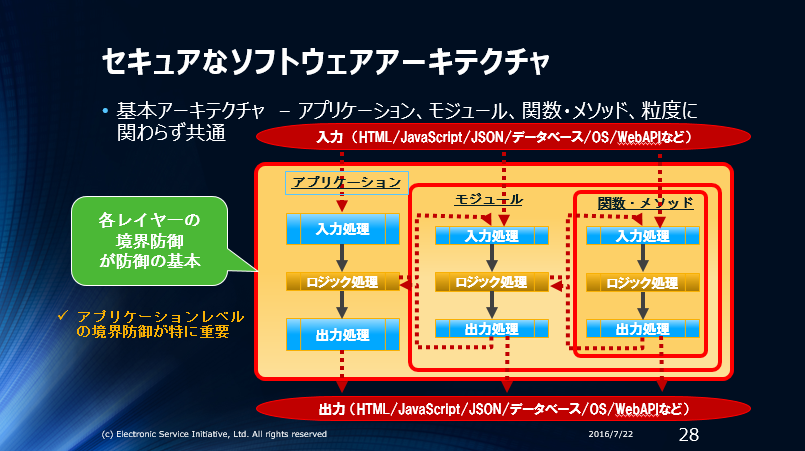
セキュアコーディング本来の信頼境界線(赤枠)とデータの無害化を行う箇所は以下の図になり入力と出力の2箇所で行います。
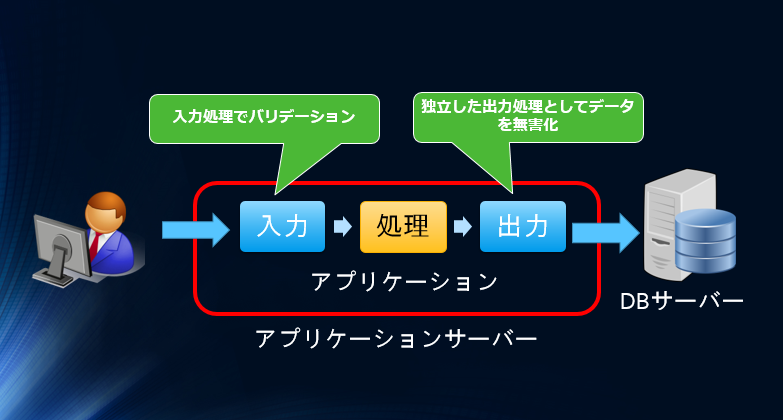
”IDS00-J 信頼境界線を越えて渡される信頼できないデータは無害化する”の解説をよく読めば、上の図のように入力バリデーションを行い入力を無害化し、出力時にエスケープ/安全なAPI利用/バリデーションを行い出力を無害化しなさい、と書かれていると解ります。
セキュアコーディングの基本的な考え方は以下のようなイメージになります。
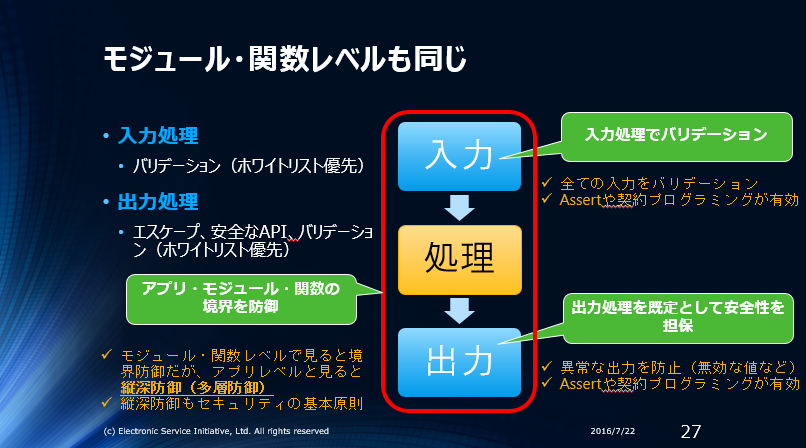
プログラムの構造はソフトウェアの粒度(アプリ/モジュール/関数・メソッド)を問わず、入力、処理、出力の構造に分割できます。アプリケーション/モジュール/関数メソッドまで含めると、セキュアコーディングの信頼境界線(赤枠)は以下のようになります。
ソフトウェア内でも重要な部品や関数は”多層防御”を行います。
スライドの19ページでは「こうだった」、とセキュアプログラミングとしてはよく解らない図で結論づけています。しかし、間違った信頼境界線の書き方、間違ったソフトウェア構造の書き方で「こうだった」とはなりません。
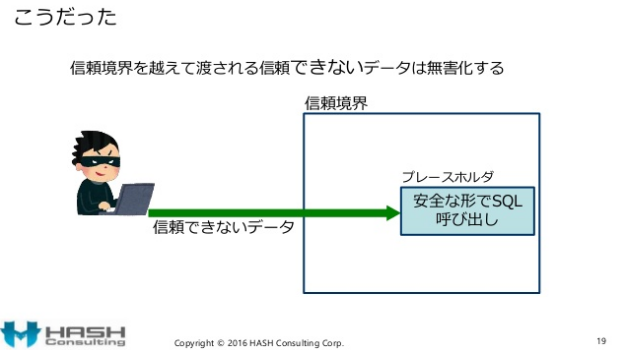
セキュアコーディングの説明図としてみると、上記の図は凡そ意図は解るが、何が言いたいのかよく解らない図ですが
「セキュアコーディングには、入力対策など無く、SQLのプレースホルダなどを使った安全な出力を行うことである。つまり出力対策のみを確実に行うのがセキュアコーディングである」
と言いたいのだろうと理解しました。セキュアコーディング習慣第1位である入力バリデーションはどこに行ったのでしょうか??
本来のセキュアコーディングの場合は、既に紹介した図と同じ、以下の画像のようなイメージになります。入力処理で本来ソフトウェアが受け取るべきデータをホワイトリストで受け取り無害化し、出力処理で必要なエスケープ/安全なAPI/バリデーションを行い無害化したデータを出力するのがセキュアコーディングの考え方です。
参考: ここではソースコード検査に耐えるコードとは?を多少修正して利用しています。
なぜ入力バリデーションが第1位のセキュアコーディング原則なのか?
解りづらい場合、ネットワークのセキュリティ対策と比較してみてください。ソフトウェアの最も外となる信頼境界線での入力対策を行わないことを、ネットワークセキュリティで例えると
- ”入り口対策無し”のファイアーウォールでネットワークを守る
ことと同じです。入り口対策がファイアーウォールがネットワークの安全性を保つには、ネットワーク上のデバイス全ての既知/未知の脆弱性を修正しなければなりません。ある程度の規模になると、トンデモないリソースが必要であるとともに、現実性もありません。
- ”入力バリデーション無し”(=入り口対策無し)でソフトウェアを守る
これも現実性がありません。ソフトウェアの最も外の信頼境界線で入力対策を行わない場合、自分が作っているソフトウェアの脆弱性のみでなく、フレームワーク/ライブラリ/インフラまで含めた全ての既知/未知の脆弱性を修正しなければなりません。他人が書いたコードを含め「知らなかった」「ついうっかり」を全て無くすことは不可能です。ネットワークと同じく規模が大きくなると破綻します。
- ”入り口対策無し”のファイアーウォールでネットワークを守る
- ”入力バリデーション無し”(=入り口対策無し)でソフトウェアを守る
どちらも、ある程度の規模を越えると、達成することは不可能と言っても構わないほど困難です。
ネットワークの信頼境界線であるインターネットと内部ネットワークにファイアーウォールを置かなくても十分なセキュリティを維持できる、入力の境界防御など要らない、というネットワークセキュリティ専門家が居たら是非会ってみたいです。ソフトウェアの最も外となる信頼境界線での入力対策を行わないで満足するセキュリティを維持するのは困難です。必要な信頼境界線の境界防御をせずに得をするのは、攻撃者かセキュリティ業者だけです。セキュアコーディングが要求する厳格な入力バリデーションにはコストが必要ですが、その他のコストやリスクを考えると安いモノです。
アプリの入力は数も多いし、変化するので入力バリデーションは現実的でない!と主張される方も居るかも知れませんが、オブジェクト指向言語にインターフェース機能があるようにインターフェースは比較的安定しています。入力バリデーションは未知の脆弱性にも対応できます。ソフトウェアに潜む未知の脆弱性を全て洗い出すコストは膨大で、実施は不可能です。仮に実現したとしても、アプリが利用するフレームワーク/ライブラリ/インフラは常に変化し続ける(つまり常にセキュリティ脆弱性混入のリスクがある)ので継続的に維持するコストは膨大です。
一方、入力バリデーションは確実に実現でき、廃除/緩和できる脆弱性が幅広いため未知の問題にも対処できます。例えば、ヌル文字インジェクション脆弱性を廃除しようとした場合、自分のコード、ライブラリ、インフラに脆弱性が確実にないこと保証するのは困難です。入力バリデーションのコストは全ての脆弱性を廃除しようとするよりも遥かに少く済みます。
ソフトウェアを護ろうとする側は1つでも攻撃可能なセキュリティ脆弱性があった場合、負けになります。この不平等なルールで勝つ為にはリスク管理の考え方が欠かせません。入力バリデーションは多くの種類の脆弱性リスクを廃除/緩和できる優れたリスク対応策です。
論理的に考えると、セキュアコーディングで最も重要な対策は入力バリデーションである、と結論できます。CERT/SANS/CWE(MITRE)/OWASPがセキュアコーディング/セキュリティ対策として入力バリデーションを最も重要な対策としているのは論理的・実証論な帰結です。
OWASPのセキュアコーディングとは?
スライドはセキュアコーディングが主題です。OWASPのセキュアコーディングといえばOWASP Secure Coding – Quick Reference Guideです。しかし、スライドにはこれの紹介がなく代わりに、開発時のルールづくり4を念頭に置いたOWASP Top 10 Proactive Controlsが紹介されています。
OWASP Secure Coding – Quick Reference Guideを紹介しない点もおかしい部分です。目次だけ紹介します。詳しくはリンク先を参照してください。
- イントロダクション
- ソフトウェアセキュリティとリスク原則の概要
- セキュアコーディング実践チェックリスト
- 入力バリデーション
- 出力エンコーディング
- 認証とパスワード管理
- セッション管理
- アクセス制御
- 暗号の取り扱い
- エラー処理とログ
- データ保護
- 通信セキュリティ
- システム設定
- データベース管理
- ファイル管理
- メモリ管理
- 一般的コーディング実践
- 付録A
- 外部リファレンス
- 付録B – 用語集
まとめ
セキュリティ専門家の仕事はソフトウェア開発者が間違えやすいケースを挙げて、間違えないようにするのも仕事の1つですがこのスライドは達成していません。それどころか、よくある信頼境界線の引き間違いがあったり、信頼できるデータの定義が間違っていたり、セキュアコーディング習慣のTop10を引用しているにも関わらず、信頼境界線の説明に必要な出力対策の解説(入力対策と出力対策は独立)を省略しています。間違いや不適切な引用/資料の出典の結果、おかしな結論になっています。
OWASPのガイドも紹介しているのですが、何故かセキュアコーディングを対象としたガイドを紹介していません。
文字通りに理解すると、信頼境界線にあまり意味がなく、入力バリデーションもあまり意味がない、と本来セキュアコーディングが意図することとは正反対の意味になるよう読めます。本来のセキュアコーディングが意図&推奨する信頼境界線やセキュリティ対策の考え方とは異るモノとしてしか読めません。
従来から入力バリデーションはセキュリティ対策ではない、と主張されているので他のソフトウェアセキュリティの専門家とは異る我が道を行く、ということだと思います。

OWASPからの引用ですが、これは
- 入力バリデーションが出力処理時のセキュリティ対策ではないこと
- 入力チェック時に出力が安全に行われるよう”変換”する必要はないこと
- 出力処理時のセキュリティ対策は出力処理のコードが責任を持つこと
を入力バリデーションを誤解しないように解説した補足です。上の3つは良く誤解されていることが見られる注意点(英語版ではCautionと記載)です。この補足で「入力チェック(入力バリデーション)を行う必要はない」と解説しているのではありません。もしこの文章をもって”入力バリデーションを行う必要はない”と解説したのであれば、酷い誤解/曲解です。
セキュアコーディングの考え方は、繰り返しになりますが、こうです。
- 入力処理時のバリデーションでは「ソフトウェアが受け入れ可能な無害なデータである事を保証」する。(大幅なリスク軽減を入力処理で行う)
- 出力処理時は「出力先のシステムに無害なデータである事を保証」する。安全な出力は出力処理コードの責任である。(出力時に確実にリスクを廃除する)
セキュアコーディングにおける入力バリデーションの目的は
- ソフトウェアが予期しているデータと合致していること確認し廃除する(合致しない物が危険なデータであり廃除する)
ことです。入力バリデーション後のデータが出力時に危険なデータかどうかはどうでも良いことです。明確にセキュアコーディング習慣/標準に記載されている通り、出力時の無害化は出力処理のコードが責任を持ちます。
誤った概念から誤った結論や考えが生まれるのは当然ですが、第1位のセキュリティ習慣がセキュリティ対策でないかのような書き方のこのスライドは、ISO27000/ISMSなどが想定するセキュアプログラミング(セキュアコーディング)とは異る物です。
セキュアコーディングを正しく実施することはソフトウェアセキュリティにとって非常に重要です。最も重要である、と言っても構わないくらいです。このスライドはセキュアコーディングを誤解し、更に誤解を広めています。私が見た時点で約1万のビューがありました。早急に訂正されることを望みます。
- ”入力データは無害化”と書かれていますが、本来はセキュアコーディング原則1に従い”入力データを検証”と書くべきでしょう。この文章には混乱/誤記があるようです。 ↩
- 応用として、DB文字エンコーディングを信頼したり、DBMSの制約などを用いてデータを信頼する設計も可能です。しかし、これらは基本ではありません。適用できる場合のみの事例です。 ↩
- CERTの文書では自分達が書いたコードがかなり大規模で複数のモジュール/アプリ/プロセスで構成されるケースも考慮し、自分達が書いたコードであっても信頼境界線を設定することを想定しています。 ↩
- 開発ルールを構築する場合、セキュリティの基礎概念がない開発者でもそれなりに安全なコードが書けるようなルールを作ります。セキュアコーディングはそのようなセキュリティの基礎概念がない開発者は対象にしておらず、基礎的概念であるセキュアコーディングの原則などを理解している開発者を対象にしています。自ずと書き方や優先順位は変わってきます。 ↩