入力処理と出力処理はプログラムの基本処理です。当たり前の処理ですが、Webアプリケーションでは基本的な事が知られているようで知られてないと思います。
入力処理と出力処理の両方ともがデータに対する責任を持っています。データに対する責任といっても、その責任は異なります。このエントリはプログラムの基本機能、入力処理/ロジック処理/出力処理が持っている責任を紹介します。
脆弱性がないプログラムを作るには、コードからの視点、データからの視点、両方が必要です。ソフトウェアセキュリティの専門家は両方の視点からのセキュリティ対策を啓蒙しているのですが、上手く伝わっていないです。
このエントリはデータからの視点で見たデータセキュリティの話です。
入力処理の責任
入力処理の責任は
- 入力データが正しい(妥当な)値であることを保証
することです。入力データが”形式的”に正しいデータであることを保証する責任を持っています。
当たり前の話じゃないか、と思うでしょう。それは当然でプログラムが正しく動作する為には、正しい(妥当な)データが”絶対に必要“だからです。
プログラムロジックで処理可能(=仕様に合ったデータ)
- データ型
- 範囲(数値の場合)
- 長さ
- 文字
- 形式
のデータでなければロジックで処理できず、正しい結果を得られません。
今はWebアプリの時代で入力(HTTPヘッダー、GET、POST、メール、ファイル、ネットワーク通信など)全てを十分にチェックする必要があります。攻撃者は使える入力全てを使って攻撃してきます。
子供の頃(40年くらい前)からプログラミングをしているので分るのですが、昔から入力処理で全ての入力データをできる限り早くチェックするのが当たり前でした。何故か今は「全ての入力データ」をチェックせず、「できる限り早くチェックする」もしなくなっています。
入力処理によくある勘違い・間違い
よくある勘違い・間違いに
- 入力処理時点での検証では出力処理時点での安全性を保証できないからセキュリティ対策ではない/セキュリティ対策として劣っている
があります。
入力処理が責任を持つのは
- 「入力データの妥当性検証」(=入力データの形式的な安全性保証)
です。入力処理はデータがSQLに使われるのか、コマンド実行に使われるのか、などの出力コンテクストに責任を持ちません。入力データがどこで使われるのか知らないのですから責任の持ちようがありません。
入力データが使われる時(=出力)の安全性を保証する責任は出力処理にあります。
残念ながらほとんどのWebアプリケーションで、最も重要なアプリケーションレベルの入力処理で入力データバリデーションを行なっていません。
参考:データ設計と機能設計は別のモノ
ロジック処理の責任
このブログの主題ではありませんが、プログラムの本体であるロジック処理も欠かせません。データに着目したロジック処理の責任は
- データが論理的整合性を維持していることを保証
することです。
通常の入力処理ではデータの形式的妥当性のみ検証します。しかし、これだけでは正しいデータとは言えません。ビジネスルールに合わないデータ、選択できないデータの組み合わせなど、これらの論理的妥当性も検証して初めてプログラムで取り扱って良いデータにであることが保証されます。
ロジック処理で入力データの形式的妥当性検証は行うべきではありません。これは後ほどSoC原則と一緒に理由を紹介します。
出力処理の責任
出力を考える場合、2つの出力を考慮する必要があります。
- 自分のプログラムへの戻り値(関数/メソッドの戻り値)
- 他のプログラムへの出力(SQLやコマンドなの実行、ファイルやネットワークへの出力など)
どちらの出力データも「正しい(妥当な)データ」であることが要求されます。ここでは「他のプログラムへの出力」だけを考慮します。
他のプログラムへのデータや命令の出力処理の責任は
- 出力データが出力先にプログラムに対して無害であることを保証
することです。
「正しく動作するプログラム」ならデータが出力処理に渡された時点では、入力処理およびロジック処理で「正しい(妥当な)データ」であることが保証されています。
出力処理でデータの正しさを検証する必要性はありません。出力処理時点で「正しい(妥当な)データ」であることが保証できないプログラムは「バグがあるプログラム」です。出力処理では「データの無害化」の責任だけを負います。
出力データが無害であることの保証は3つの方法で行えます。
見過ごされている出鱈目なデータ出力
「データを無害化して出力さえすればセキュリティ的にはOK」は飛んだ勘違いとなってしまう場合があります。
「出力時点のデータバリデーション」や「出力先の入力バリデーション」でエラーが起きるプログラムは構造的に不良品です。攻撃者の攻撃用データを含む出鱈目なデータを出力するプログラムは壊れている、と言えます。
理想的には入力処理とロジック処理で「不正なデータ」(=妥当でないデータ)は完全に排除されているべきです。しかし、現代のプログラムは非常に複雑かつ変更も頻繁です。出力時点で完全にデータバリデーションが完了してることを保証することが困難です。実際、多くのソフトウェアで「このデータはそのまま出力/使用しても大丈夫なはずのデータ」に攻撃用データが入ってしまい攻撃可能になっています。(しかも、入力データの検証が不十分もしくは全くないことが当たり前にあります)
そこで、データを出力する場合は「多層防御」を取り入れ「全ての出力データを完全に無害化」します。これで最悪の場合でも攻撃者に不正な命令を実行されることを防止できます。
つまり、通常は出力処理でエラー・例外などが発生することはあり得ないが「フェイルセーフ対策」として出力時にセキュリティ処理「全ての出力データの完全な無害化」を行います。
全てのデータに対して完全な無害化対策をしない出力対策
SQLインジェクション対策とコマンドインジェクション対策がその代表例です。
SQLデータベースに対するインジェクション攻撃を完全に防止するには、SQLデータベースが持つ機能に対するインジェクション攻撃を全て防止する必要があります。しかし、「プリペアードクエリ/プレイスホルダだけ使っていればSQLデータベースに対するインジェクション対策は完璧」とする間違った認識が広く見受けられます。
プリペアードクエリ/プレイスホルダだけでは”識別子”を使ったSQLインジェクション攻撃や過大なデータ処理をさせるDoS攻撃にさえ対応できません。全てのコンテクスト(≒ 機能)に対して出力を無害化しないと完全な対策になりません。
コマンドインジェクション攻撃を完全に防止する場合も、全てのコンテクストに対して出力データを無害化しないと完全な対策になりません。
最初にコマンドを実行する命令(execやevalなどのコマンド実行命令)のコンテクストに対して”だけ”に対策しても完全な無害化対策になりません。実行したコマンドが処理する引数のコンテクストに合わせた無害化を行わないとコマンド実行の脆弱性を残すことになります。
出力対策では「全てのデータの全てのコンテクストで無害であることを保証」する責任があります。
セキュアな構造のデータバリデーション
データバリデーションには3種類あり、それぞれ役割(=責任)が異なります。セキュアな構造のソフトウェアを作るには、構造化されたセキュアなデータバリデーションが必要です。適切な箇所で必要なセキュリティ処理(データバリデーション)を行わないと安全なアプリケーションは構築が困難になるだけです。
「出鱈目なデータを渡してもAPIが適当に処理してくれるから大丈夫!」とする考え方で作られたアプリケーションが安全になることはありません。
プログラムが正しく動作するには「正しい(妥当な)データ」が必須であり、「遅すぎるエラー/例外はバグ」だからです。データを安全に扱うには、後述するFail Fast原則の考え方が必要です。
原理と原則に反したセキュリティ対策
正反対で問題だらけの考え方が「正しいセキュリティ対策」として啓蒙されているケースを見受けますが、これらは根本的に間違っています。
以下はPHPカンファレンスでセキュリティ対策の講演として使用されたスライドの画像です。
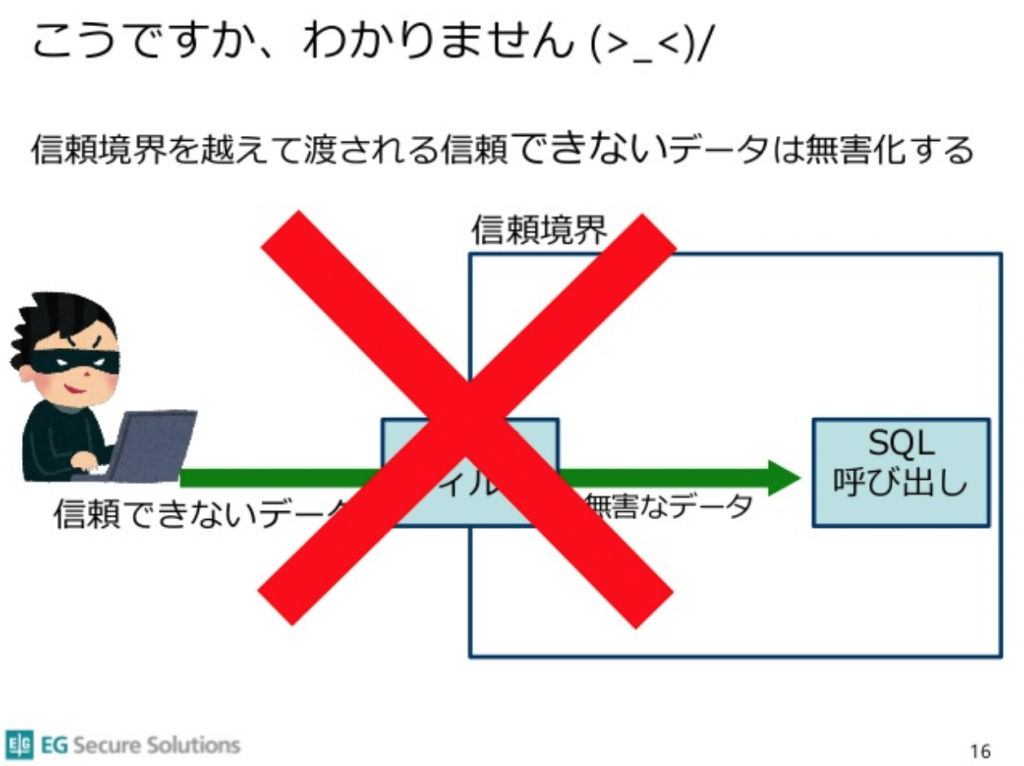
SQLデータベースに対するインジェクション攻撃に解説で、セキュアコーディングでもっとも重要な原則である信頼境界での入力バリデーションは無し。
備考) セキュアコーディングでは、入力データは「無害化」するのではなく「検証」するものです。
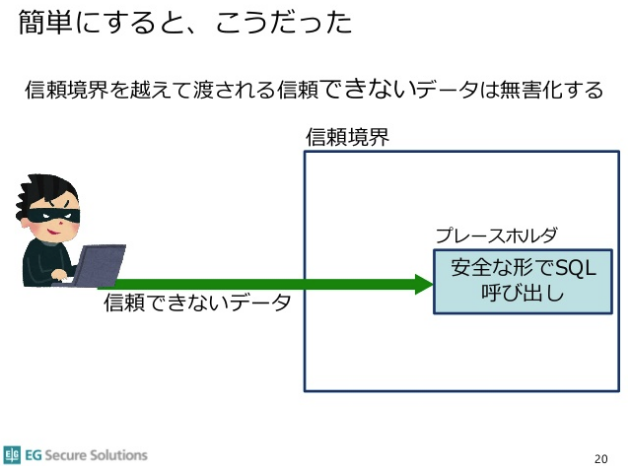
プレースホルダ出力対策だけ行えば良い、としています。
しかし、これでは攻撃者やセキュリティ業者を喜ばすだけで、開発者や利用者にメリットはありません。このプレースホルダに頼ったSQLインジェクション対策がダメである詳しい理由は、上で紹介した「完全なSQLインジェクション対策」を参照してください。
2017年の講演では入力バリデーションにも触れられるようになりましたが、「信頼境界」で入力データの形式的妥当性を完全に検証するのではなく、ロジック処理で検証するモノだとしています。そしてWebアプリの全ての入力データ(HTTP ヘッダー、GET、POST)を検証するモノとしていません。これも、攻撃者やセキュリティ業者を喜ばす対策になります。
データセキュリティはできる限りデータの入り口に近いところから安全性(妥当性)を確保できるように設計します。プログラムが正しく動作する(=脆弱性なく動作する)には絶対に正しい(妥当な)データが必要だからです。
データセキュリティを入り口から遠いところ(出力やロジック)で維持しようとしても、完全なデータセキュリティ(データ妥当性)を確保することは無理であるか困難です。
入力データの安全性はできるだけ遠いところから、Webアプリの場合はWebサーバー側アプリの信頼境界の外にある、ブラウザのJavaScriptプログラムから、可能な限りのデータの正しさ(妥当性)を保証するように設計します。
注意) ブラウザ側のプログラムはサーバー側のプログラムの信頼境界の外にあります。ソフトウェアの信頼境界は同一プロセス/スレッド上のコードまでが限界です。それ以外のプログラム(OSやDBも含む)からのデータは全て検証/保証無しに信頼できません。ブラウザ側プログラムでバリデーションした入力データもサーバー側で再度バリデーションします。ブラウザ側で厳格なバリデーションをすればするほど、サーバー側でも厳格なバリデーションが可能になるので、セキュリティ維持が容易になります。このような設計はセキュアコーディング原則で推奨されています。
原理に基づいた入力処理と出力処理の原則
正しく動作するプログラムの動作原理はシンプルです。
- コンピュータープログラムは”正しいコード”と”正しい(妥当な)データ”の両方が揃って初めて正しく動作する
APIやフレームワークはこの原理が適用できるよう、ある程度の補助は行います。しかし、正しいコードと正しい(妥当な)データであることを保証する責任はアプリケーション開発者にあります。
- 第1原則 – 入力をバリデーションする
- 第7原則 – 出力を無害化する
今のインジェクション攻撃は基本的に「形式が決まっているデータ」に対して「無効な形式のデータ」を送って攻撃します。数値にプログラムコード、文字列に不正文字、大きすぎるデータなどが攻撃用データです。こういった不正形式のデータを排除するだけで多くのセキュリティ問題に対応できます。
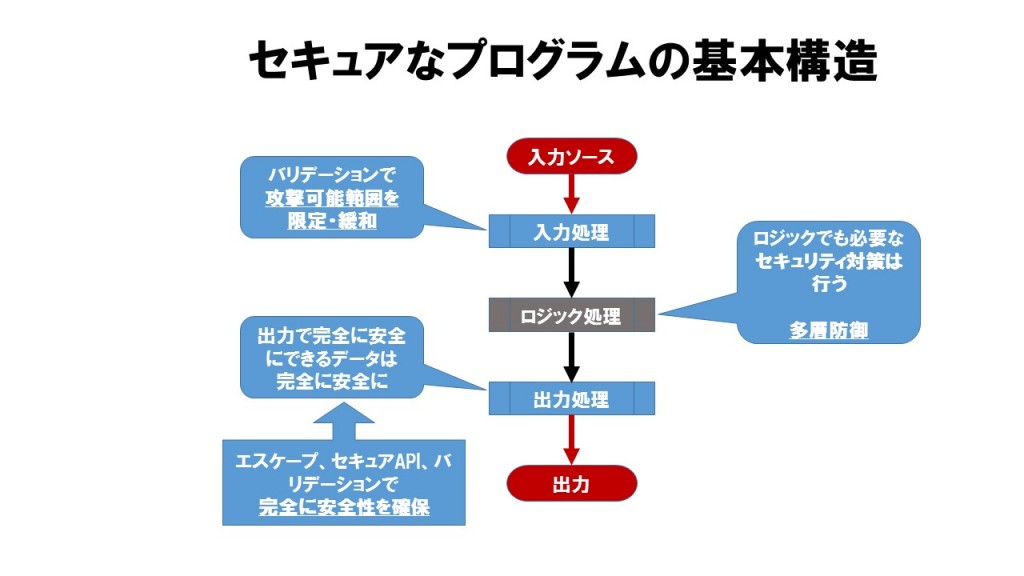
自由に入力可能なデータは出力時の無害化処理が絶対に欠かせないセキュリティ対策です。しかし、アプリケーションが処理するデータの大半は一定の形式を持ち、入力データが入力処理とロジック処理でバリデーションされていれば無害化が無くても大丈夫なデータになります。
セキュアコーディングでは「本来は無害であるハズの出力データも含めて、全て完全に無害化」します。「無害であるハズのデータ」に対する無害化は「フェイルセーフ対策」です。
安全性の高いシステムでは「フェイルセーフ対策」が機能(攻撃を防止)して安全性が保証できる、ようには作りません。1「フェイルセーフ対策」はあくまで万が一の対策であり、「フェイルセーフ対策」以外に「別のセキュリティ対策」を必ず行います。
データセキュリティ対策を行う箇所は大別して3箇所
- 入力処理
- ロジック処理
- 出力処理
があり、「入力処理とロジック処理でのデータバリデーション」が「データのセキュリティを保証する責任」を持っています。
もう一つ忘れてはならないのはFail Fast原則です。
- Fail Fast原則 – 失敗するモノはできる限り早く失敗させる原則
ロジック処理でデータバリデーションをしているから、といってアプリケーションの入力境界でのデータバリデーションを省略し、統合するのはお勧めできる構造ではありません。
効率よく管理可能なプログラムを作るには、SoC原則が必要です。
SoC原則 – Separation of Concerns 主題となる役割に応じてプログラムの処理を分割する原則
既に解説した通り、入力処理では「入力データが形式的に正しい」ことを保証します。これ以外の入力データは全て拒否します。
セキュアコーディング原則では、全てのソフトウェアが入力バリデーションを行うように要求しています。 Webアプリケーションの場合、クライアント側のJavaScriptアプリケーションで入力をバリデーションするようにします。
クライアントでデータ形式をバリデーションしていれば、ユーザーが入力したデータであってもバリデーション仕様に合わせてサーバー側でも厳しく入力データバリデーションを行えるようになります。
まとめ
入力処理/ロジック処理/出力処理はそれぞれ以下の責任を持ちます。
- 入力処理 – 全ての入力データが正しい(妥当な)形式であることを保証する責任
- ロジック処理 – データが論理的に妥当であることを保証する責任
- 出力処理 – 全ての出力データが無害であることを保証する責任
ほとんどのWebアプリケーションで重要な入力処理と出力処理の責任が忘れられています。
入力処理では、全ての入力データの妥当性検証、が忘れられています。出力処理では、全ての出力データの完全に無害化、が忘れられています。この2つをきっちり実施するだけで現在よくあるセキュリティ問題の大半に対応できる、にも関わらずです。
「出鱈目なデータであってもAPIやフレームワークが適当に処理してくれる」と考えるのは危険です。
例:何をやってもダメなので、壊れた文字エンコーディングは受け入れてはならない。
出鱈目なデータはずっと出鱈目なデータです。
出鱈目なデータをサニタイズして何もなかったように処理してしまうのもセキュリティ問題です。2017年版のOWASP TOP 10からこのような処理をするアプリケーションは脆弱なアプリケーションである、として指摘しています。
現在のWebアプリケーションはセキュアなアプリケーション構築に必要な原理・原則に反した方法で構築されたものが大半を占めています。この状況の考察は別のブログで書きたいと思います。
- 自由に入力できるデータにプログラムのコードが書かれていた、としてもこれは攻撃ではありません。単に「データ」としてコードが書かれているだけです。これらのデータを出力する際に無害化対策するのは当然です。 ↩