ホワイトリストの考え方/作り方は難しくありません。しかし、間違えていることが少なくないようです。
GoogleがCSP(Content Security Policy – ホワイトリスト型のJavaScriptインジェクション対策)の利用状況を調べたところ以下のような結果が得られました。
we take a closer look at the practical benefits of adopting CSP and identify significant flaws in real-world deployments that result in bypasses in 94.72% of all distinct policies.
なんと、約95%のCSP利用サイトがCSPの保護が無効になるような設定になっていた、としています。
ホワイトリストの作り方
ホワイトリストの作り方はとても簡単です。
- デフォルトで拒否する
- 許可するモノだけ許可する(最小限のモノだけ許可)
これだけです。どういったモノを許可するか?最小限のモノとは何か?はケースバイケースです。コンテクストに合わせて判断します。
以下の図の水色部分であることを保証するのがホワイトリスト型のバリデーションです。
CSPはホワイトリストで保護することが前提になっています。CSPの定義で多くみられた根本的な間違いに「全て許可している」「不要な物まで許可している」といった設定があります。
ホワイトリストの作り方は簡単ですが、全て拒否した上で、必要最小限のモノだけ許可しないとホワイトリストになりません。
- 基本に忠実であること
- 意図せず許可しているモノがないようにすること(CSPの場合、仕様を正しく把握する)
これらに注意する必要があります。
MITRE/CWEが提唱する標準バリデーション
CWEを管理しているMITREは脆弱性対策ガイドラインとしてCWE/SANS TOP 25を2011年から公開しています。その中で「恐ろしく効果的(怪物的な)セキュリティ対策」(Monster Mitigations – Mitigation(緩和策)はISO 27000の定義でセキュリティ対策(リスク管理策)の一つとして定義されている)として次のようなバリデーションが「標準入力バリデーション」としています。
全ての入力に対して標準入力バリデーション機構を利用する:
* 長さ
* 入力種別
* 文法(※ 形式)
* 少すぎる/多すぎる入力
* 関連するデータの整合性
* ビジネスルール
参考:
通常バリデーションは多層構造で行います。
Webアプリのパラメーターバリデーション
Webアプリの場合、HTTPヘッダー(Cookie含む)、URLのクエリ文字列、POSTパラメーターをホワイトリストでバリデーションします。この際、
- データ型が一致する
- 数値なら妥当なデータ範囲である
- 文字列なら以下が妥当である
- 長さ
- 文字エンコーディング
- 利用する文字
- 文字列形式(日付、電話番号など)
- 構造を持つデータ(JSONやXML)なら以下が妥当である
- 構造の正しさ
- 構造内に含まれるデータの正しさ(上記の数値/文字列チェック)
- 引数の数が妥当である
- 引数の過不足がない
をチェックします。
Webアプリでは、プロプライエタリなプロトコルとは異り、パラメーターの種類や数は定義されていません。攻撃者は全てのパラメーターに対して攻撃してくるので、全てのパラメーターをチェックする必要があります。
参考:
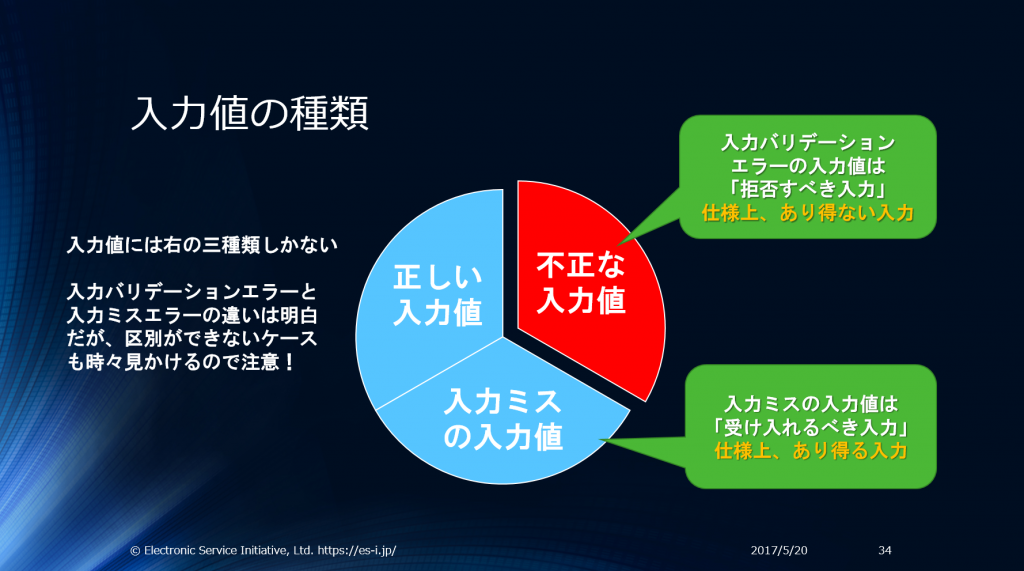
入力値は大別すると三種類になります。”入力ミス”は妥当なデータであることに留意してください。
通常、バリデーションは形式的バリデーションと論理的バリデーションは別に行います。
ブラックリストの作り方
セキュリティ対策ではホワイトリストを使うのが基本です。ホワイトリストの反対がブラックリストです。参考までにブラックリストの作り方も紹介します。ホワイトリストの作り方の反対をするだけです。
- デフォルトで許可する
- 許可できないモノだけ拒否する
ブラックリストが十分有効に機能するには”許可できないモノを漏れ無く全て把握”する必要があります。一部の許可できないモノを把握するのは簡単です。例えば、HTML出力の場合は<, >, &, ‘, ” が許可できない文字です。
しかし、HTML出力の文字列としては<, >, &, ‘, ” 以外に、制御コードや壊れた文字コードも許可できないモノに入ります。これらを忘れていると誤作動、つまり脆弱性の原因になります。
ブラックリストの方が問題のある定義を作りやすいです。このためセキュリティ標準やガイドラインではホワイトリストを優先するとしています。
参考:
例えば、Railsセキュリティガイドでは以下のように解説されています。
ブラックリストではなくホワイトリストに基づいた入力フィルタを実施することが絶対重要です。ホワイトリストフィルタでは特定の値のみが許可され、それ以外の値はすべて拒否されます。ブラックリストを元にしている限り、必ず将来漏れが生じます。
特定の項目だけを許可するホワイトリストアプローチは、特定の項目だけを禁止するブラックリストアプローチに比べて、ブラックリストへの禁止項目の追加忘れが原理的に発生しないので、望ましい方法であると言えます。
まとめ
ホワイトリストでは対応できない場合もあるのでブラックリストは同じように重要/有効、とする考え方もあるようですが、この考え方はピント外れです。
ブラックリストは思考手法として脆弱です。ブラックリスト対策でホワイトリスト対策並みの効果を得るには”全てのNGケースを正確に把握する必要”があります。例えば「ユーザー名に改行文字があると不正メールが送られたり、Webページの改ざんができる事がある」と認識している初心者は皆無でしょう。間違いを起こしやすいのでホワイトリストを優先すべきとされています。セキュリティが重要な場合は常にホワイトリスト型の制限の適用を考えるべきです。
ソフトウェア開発者にとってホワイトリスト優先は特に重要です。システム管理者のように出来合いのシステムを使わざるを得ない場合、ブラックリスト型のセキュリティ対策が”効果的”である場合1もあります。しかし、ソフトウェア開発者のように自分が自由に作れるソフトウェアにおいてブラックリストの方が”効果的”であるケースはあまりありません。
セキュリティ対策を考える場合、どのようなコンテクストでのセキュリティ対策なのか?が重要です。ソフトウェア開発におけるセキュリティではホワイトリスト優先は原則である、と考えると間違いの可能性が少なくなります。
GoogleのCSP Eavaluatorで見てみると、CSPを「ブラックリスト対策と勘違いしているのでは?」と思えるような定義もありました。
- ソフトウェア開発におけるセキュリティではホワイトリスト優先は原則である
この考え方であれば少なくとも現状(95%のCSPサイトが不適切)のようにはならなかったのではないでしょうか?
- 例えば、ブラックリスト型で保護するWAF(Web Application Firewall)は”ソフトウェアを改修できない”システム管理者にとっては”効果的”な対策です。 ↩