Attack Surface (攻撃可能面=攻撃可能な箇所)の管理はセキュリティ対策の基本中の基本です。あまりに基本すぎてあまり語られていないように思います。
攻撃可能面を管理するには先ず攻撃可能な箇所がどこにあるのか分析(=リスク分析)します。その上でできる限り攻撃可能な箇所を削減(=リスク削減)します。攻撃可能面の分析と管理とはリスク分析と管理です。セキュリティ対策そのものと言える、基本的な管理です。
Attack Surface (攻撃可能面)
The attack surface of a software environment is the sum of the different points (the “attack vectors“) where an unauthorized user (the “attacker”) can try to enter data to or extract data from an environment.[1][2] Keeping the attack surface as small as possible is a basic security measure.
出典:Wikipedia
日本語訳すると以下のようになります。
ソフトウェア環境における攻撃可能面は不正なユーザー(攻撃者)がデータを攻撃対象に入力または取り出し可能な様々箇所(アタックベクター)の集合である。攻撃可能面を可能な限り小さくするのは基本的なセキュリティ対策である。
Attack Surface Analysis (攻撃可能面分析)
境界防御がない/不十分なソフトウェアの攻撃可能な箇所は膨大です。何も対策しないでいきなり分析するのは無駄すぎます。これから作るアプリケーションの場合、基本的な対策を行ってから分析する方が良いです。このブログでは基本的なデータ処理分析について記載します。実践で分析する場合はデータと機能の両方を考慮して分析します。
攻撃可能面を分析する場合、データの流れに沿って分析します。
- 入力処理でどの程度攻撃データを防止しているか?(形式的データバリデーション精度分析)
- ロジック処理でどの程度攻撃データを防止しているか?(論理的データバリデーション精度分析)
- 出力処理でどの程度攻撃データを防止しているか?(データ無害化処理分析)
入力、ロジック、出力はそれぞれ役割(責任)を持っています。単一責任原則(Single Responsibility Principle)で対処します。(= それぞれ独立した機能として扱う。結果的に多層防御となる)
- 入力処理: 主に入力データの形式的バリデーション。全ての外部入力をデータ形式をバリデーションする責任を持つ。ユーザーとのインタラクションはない(=入力ミスは妥当な入力データ)
- ロジック処理: 主に入力データの論理的バリデーション。ロジック処理に対する全ての入力が論理的に妥当であることを保証するバリデーションをする責任を持つ。入力ミスの処理責任を持つ。
- 出力処理: 出力データが出力先に対して完全に無害であることを保証する責任を持つ。出力無害化は入力/ロジックのバリデーションとは独立した処理とする。出力時点/出力後のエラーは発生してはならない。無効なデータによるSQLクエリエラーなどは入力またはロジック処理でのデータバリデーションに欠陥がある。(フェイルセーフ対策の多層防御)
アプリケーション仕様的にあり得ない入力データは、Fail Fast原則(失敗するものはできる限り早く失敗させる)で処理されていなければなりません。入力データは出力前に完全にアプリケーション仕様的に妥当であることが保証されていなければなりません。つまり、出力処理でエラーになってはなりません。セキュリティ問題となる誤作動は”命令のインジェクション攻撃”に限りません。
入力の境界防御がない/不十分なアプリケーションの場合、アプリケーションのコード、フレームワークのコード、ライブラリのコード、全てのコードが攻撃可能になります。PHP / Ruby / Pythonなどでアプリケーションを作っても、これらの言語で書いたフレームワークやライブラリどころか、その下層のC言語で書かれたライブラリのコードも含めて攻撃可能になります。
そもそも膨大な量の不確定要素がソフトウェアには存在しますが、出鱈目なデータの受け入れにより”組み合わせ爆発”が更に指数的に増加し必要以上に不確定要素(≒セキュリティリスク)が膨大になります。
攻撃可能面を防御する
攻撃可能面をの防御を簡略化した図にする以下のようなイメージになります。
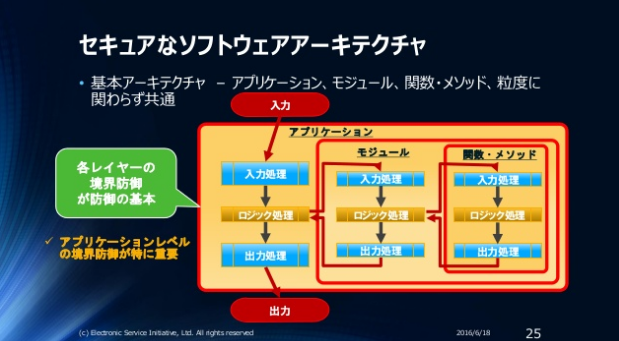
実際には、アプリケーションレベルの攻撃可能面は”全て”防御し、モジュール/関数・メソッドレベルの攻撃可能面の防御は”選択的”(=一部だけ)に行います。
モジュール/関数・メソッドレベルの攻撃可能面の防御は”選択的”(=一部だけ)に行う理由は、アプリケーション内部の機能の攻撃可能面の防御は上位のアプリケーションレベルの防御に任せることが可能であり、その方が実行効率的に有利だからです。
よく呼び出される低レベルな機能に防御を任せるとどうしても実行効率が悪くなります。その典型的な例はPCREの文字エンコーディングバリデーションです。PCREにはUTF-8文字エンコーディングのバリデーションを無効化する機能があり、無効化すると数百倍の実行速度を実現できることもあります。
文字エンコーディングバリデーションのように上位の攻撃可能面防御に任せられる防御を低レベルな関数・メソッドに任せるとPCREの様に極端なパフォーマンスペナルティが課せられます。効率的かつ論理的なセキュリティ対策では、文字エンコーディングのようにアプリケーションレベルの攻撃可能面防御(=境界防御)で防御可能なモノはFail Fast原則に従い、可能な限り上流で対策します。
先ずできるだけ攻撃可能面を削減する
どんなセキュリティ対策でも同じですが、先ずできる限り攻撃可能な箇所を削減します。
アプリケーションでは全ての外部入力データを厳格にバリデーションします。厳格な入力バリデーションは、未知のセキュリティ問題を含め数えきれないくらいの攻撃を不可能にします。 本当に文字通りに「数えきれないくらいの攻撃を不可能」にします。詳しくは直前に紹介した”形式的検証”と”組み合わせ爆発”から学ぶ入力バリデーションで説明しています。
入力対策だけでセキュリティは維持できません。出力対策も必要です。入力対策と同じく、できる限りの対策を行います。具体的には全ての出力データが出力先に対して無害であることを保証します。
入力も出力も全てのデータをデフォルトで検証/無害化する仕組みを導入する方が攻撃可能面を削減できます。
例えば、入力データは検証済みでないと使えない仕組み(ホワイトリスト型の対策)を導入する。出力にはデフォルトで無害化されるような仕組み(これもホワイトリスト型の対策)、デフォルトHTMLエスケープのHTMLテンプレートシステムやデフォルトで全てのデータを無害化するORMなど、を利用するなどです。
出来るだけ攻撃可能面を削減した後、残った攻撃可能箇所のリスクを分析する
既に完成しているアプリケーションの場合、仕方ないので今あるアプリケーションの現状で攻撃可能面を分析します。よくあるWebアプリケーションの攻撃可能面を普通に分析すると膨大な数の攻撃可能な箇所(リスクがある箇所)が見つかります。
今の一般的なWebアプリケーションは入力データバリデーションが甘いか全くないので、厳格なバリデーションであれば無視できるCのライブラリ関数レベルの脆弱性まで攻撃可能になります。特にバリデーションが甘い/無いアプリケーションでは、こういった隠れたリスクを見逃さないよう注意します。
妥当でないデータをアプリケーションの中に入れると、絶対に正しい動作結果にならない上、何が起きてもおかしくない状態になります。程度の差こそあれ、不正なデータを受け付けて処理してしまう仕様の場合、ほとんどが何らかのセキュリティ問題(無用なリスクの受け入れから不正な命令の実行)と分類される問題になります。
現在のWebアプリセキュリティ対策は出力対策に偏重しています。しかし、偏重している出力対策も”極めて不十分な対策”が”十分な対策である”、と勘違いされています。
「プリペアードクエリだけで十分」、「コマンド実行時にコマンドと引数を分離するAPIだけで十分」とするのは誤りです。攻撃可能面分析を適切に行った場合、このような勘違いは起きません。
攻撃可能面分析を行う
Wikipediaに記載されている手順を紹介します。
- 可視化 – アーキテクチャーやコンポーネントを可視化する
- 暴露している指標を見つける ー 攻撃可能になっている箇所であることを示す構造などを見つける
- 攻撃可能箇所である指標を見つける – 実際に攻撃可能になってしまっている箇所を特定する
可視化する場合、本来あるべき信頼境界線を書くと解りやすいです。ソフトウェアも多層防御で守ります。信頼境界線の中に更に信頼境界がある構造図になるはずです。
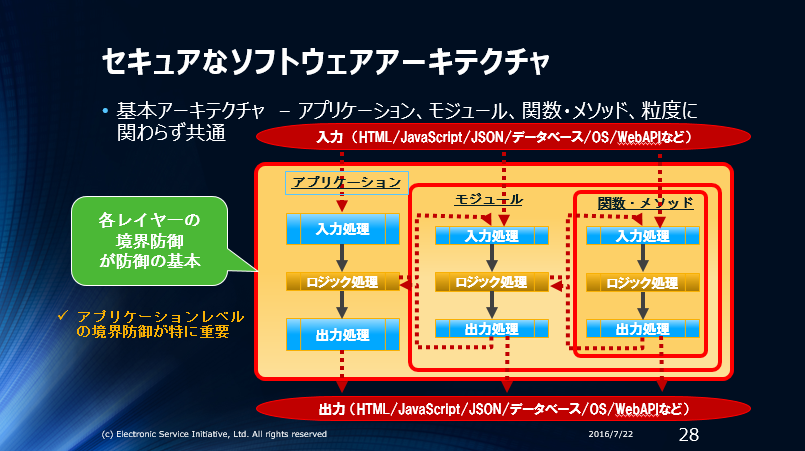
ソフトウェアの攻撃可能な箇所を特定するには、データがどのような経路で渡され、どのようなバリデーションが行われているか?データとバリデーションを中心に考えた分析が必要になります。
データは最終的には出力されるモノです。出力時に完全に無害化されたデータであることを保証できているのか?無害化の完全性を分析します。
攻撃可能面分析をセキュリティ対策に活かす
コンピュータープログラムは妥当なデータしか正しく動作できず、不正なデータを処理・保存すること、不正なデータで遅すぎる段階でエラーになること、はセキュリティ問題になります。
データの妥当性検証は主に入力処理とロジック処理で行います。データの妥当性が正しく検証されていない箇所に対策を導入します。
アプリケーションへの入力データは最終的に何らかの形で出力/利用されます。その際には無害な形で出力されているか、出力先で正しくバリデーションされていることを検証/保証します。外部への出力(複雑な処理を行うライブラリへの出力を含む)で無害化対策が足りない箇所に対策を追加します。
この際、遅すぎるフェイルセーフ対策”だけ”に頼るのはNGです。例えば、出鱈目なデータの場合はSQLクエリエラーになるからOK、ではありません。このような構造のソフトウェアは構造的な問題を持っていることになります。
まとめ
このブログでは攻撃可能面分析における「データの扱い」のみを紹介しました。これはデータの取り扱いを厳格にするだけで大半のインジェクション攻撃に対策できるからです。
しかし、データの取り扱い”だけ”ではアプリケーションは十分安全にはなりません。機能面を含め、セキュリティ要素全てに対して十分な対策が行われる必要があります。
これらで全てではありませんが、CERT Top 10 Secure Coding PracticesやOWASP Secure Coding – Quick Reference Guideが参考になります。
上記の2つだけでは全く不十分で、本格的に分析する場合はISO 27000が参考になります。ISO 27000ではITシステムが保持すべきセキュリティ要素として
- 機密性
- 完全性
- 可用性
- 信頼性
- 真正性
- 否認防止(責任追跡性)
が備わっていることを求めています。
自分で行う時間がないなどの場合、ソースコード検査サービスであれば、多かれ少なかれ、この種の分析レポートが付いてくるはずです。
おまけ
ネットワークや物理的なセキュリティ対策では「戸締りから始める」が当たり前です。しかし、ソフトウェアでは何故か”盗まれる”という事象に偏重し「金庫の設置から始める」が当たり前になっています。しかも、SQLインジェクションやコマンドインジェクションに脆弱な「穴開き金庫」を使って。
これではマトモなソフトウェアセキュリティは何時まで経っても実現しません。泥棒と金庫業者を喜ばせるだけです。
一度で良いので、本物のリスク分析、を自分のアプリケーションで行ってみてください。あまり沢山の方から呼ばれると困りますが、対応可能な範囲でお手伝いします。
参考: