ソフトウェアの不具合/脆弱性を無くすためには、出力先に対して無害であることを保障する出力対策が重要です。どんな出力でも3つの方法で無害化できます。
このブログでは基本として、セキュアコーディングの概念に基き説明しています。先ずはよくある入力対策と出力対策の区別がついていない誤りから紹介します。
参考:IPAは基礎的誤りを明示し、正しい原則を開発者に啓蒙すべき
TL;DR;
データを出力する際に以下の3つの方法を使うと、出力を無害化できます。
- エスケープ
- エスケープをせずに出力できるAPI
- バリデーション(1も2も使えない場合に利用)
これが3原則です。出力時に少なくとも何れか1つを利用し無害化する必要があります。
意味のある文字などは全て無害化しなければなりません。エスケープ方法があってもエスケープAPIが用意されていない場合もあります。エスケープをせずに出力できるAPIもない場合が多いです。
単純にAPIを探すのではなく、
- 意味のある文字があるか?
- ある場合はエスケープ方法が定義されているのか?
- 無害化に利用できるAPIはあるか?
- どうバリデーションすれば無害なのか?
といった順番で調べます。単純にAPIを探すと、APIがないのでそのまま出力、といった見落しが発生します。
出力対策(出力無害化)の
- 半分は正しく動作する為に必須の対策
- 半分はフェイルセーフ対策
です。フェイルセーフ対策としての出力対策は本来機能してはなりません。これを防ぐには+1原則である
- 入力データのバリデーション
を行います。
出鱈目なデータは、出力しても、エラーになっても、どちらも不正な動作です。データはFail Fast原則に則り早くバリデーションします。従って、出力前に必ずバリデーションされていなければなりません。データは入力処理/プログラムロジックでバリデーションします。出力時のバリデーションはフェイルセーフ対策です。
セキュリティ対策でよく見る根本的な間違い
よくある間違いは、
- 出力対策”だけ”で十分な対策となる
- 入力対策はセキュリティ対策としてあまり役立たない
とする勘違いです。出力対策のエントリですが、安全な出力に欠かせない入力対策、に対する出鱈目な解説もあるので少しだけ入力対策を紹介します。
例えば、このスライドの内容はセキュアコーディングの解説のようですが「入力対策で”無害化”がわからない」とし、
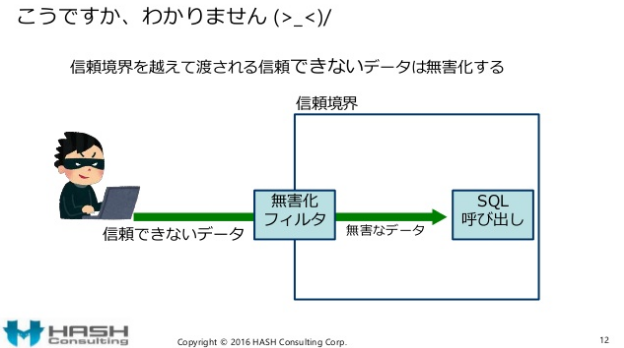{kind=link}
入力対策はダメな対策だとしています。
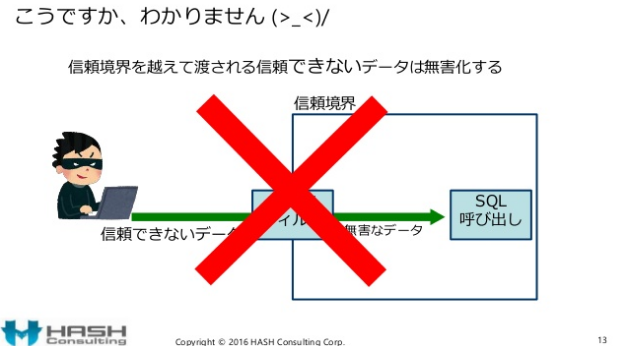{kind=link}
本物のセキュアコーディングの入力対策では「入力の妥当性検証」(入力バリデーション – 第一原則)を行います。「出力時の無害化」を主たる目的にしていません。「入力妥当性検証」の結果として多くのパラメーターが無害化(=保護)されます。
しかし、セキュアコーディングで無害化の責任を持っているのは出力対策です。「入力妥当性検証」で無害化されたパラメーターであっても”独立した対策”として出力対策が必要です。「出力の無害化 – 第七原則」は独立した対策として常に行います。従って、このスライドはセキュアコーディング概念の説明として根本的な部分で誤っています。
参考:CERTトップ10のセキュアコーディング原則
コンピュータープログラムの構造上、入力対策が欠かせません。これがセキュアコーディングにおいて「入力をバリデーションする」が第1原則である理由です。これは以下を参考にしてください。
セキュアな構造のアプリケーション/ソフトウェアは、
- 入力データ妥当性検証
- 正しいロジック
- 出力データ無害化
この3つを揃えて十分なセキュリティ対策の構造を持っていることになります。
※ 「セキュアコーディング」/「セキュアプログラミング」は確立した用語と概念で、ISMS/ISO 27000やPCI DSSといったセキュリティ認証規格で要求される概念と技術です。これとは根本的に異なる概念を同じ用語を用いて「これこそが”セキュアコーディング”である」と解説し、開発者を誤解させるのはセキュリティ専門家のモラルとして如何がなものでしょうか?本物のセキュアコーディングの第一原則は「信頼境界で入力をバリデーションする」です。
出力のコンテクストを正しく識別しないと、出力無害化ができない
十分な出力対策には”出力コンテクストの識別”が欠かせません。コンテクストに注意していても、初心者による間違い/勘違いは後を絶ちません。毎年、新しい開発者が生まれるので当然と言えば当然です。
一見、単一のコンテクストに見えも複数のコンテクストを持つケースもあります。このため、エスケープする際には出来る限りコンテクストに依存しないようなエスケープ方式(エンコードと言われる場合もある)を採用する方が良いです。このブログでも、まだ改善の余地がありますが、JSONとJavaScript文字列でそのような方式になるような使い方/処理方法を紹介しています。
JSONはJSON/HTML/JavaScriptのコンテクストで利用される可能性があります。
JavaScript文字列もJSON/HTML/JavaScriptのコンテクストで利用される可能があります。
出力先のコンテクスト
コンテクスト(英: Context)あるいはコンテキストとは、文脈や背景となる分野によってさまざまな用例がある言葉であるが、一般的に文脈(ぶんみゃく)と訳されることが多い。文脈により「脈絡」、「状況」、「前後関係」、「背景」などとも訳される。
(Wikipediaより)
Webアプリの場合、ほとんどの出力先がテキストインターフェースです。出力先のコンテクストを理解するには、テキストインターフェースを理解する必要があります。 Webアプリが利用するテキストインターフェースのほとんどは可変長ですが、固定長と可変長の2種類があります。それぞれのインターフェース/コンテクストに合った出力を行わないと、問題が発生します。
出力が出力先に対して無害であることを保障する為には、既に記載の通り、出力先のコンテクストを正しく識別する必要があります。
例えば、SQL識別子の無害化が必要なケースで、SQL識別子がソート順の基準となる変数になっている場合に、SQLパラメーター用のエスケープやAPIを使っても意味がありません。意味がないどころか正しく動作せず、場合によってはインジェクション攻撃が可能になります。極端な話、HTML出力を行うコンテクストで、SQLパラメーターの出力対策を行っても意味がない、事と同じです。
原理的に入力対策なし、出力対策だけでセキュアなソフトウェアが作れません。その理由は論理的に説明できます。
- 出力対策の3原則で出力を無害化できても、出力が正しいことを保障できない
”データが出力先に対して無害である”とは”出力先で誤作動を起こし不正な命令が実行されない”こと意味します。例えば、HTML出力コンテクストで整数形式の商品IDに
<script>alert(‘xss’)</script>
が保存されていた場合に、これをHTML出力に対して無害化し
<script>alert('xss')</script>
と出力すれば無害化できます。しかし、これは正しい商品IDデータではありません。出力は3原則で無害化出来ても、正しさの保障を普通はできません。データの正しさの保障は、基本的には、入力処理とロジック処理で行います。
この他にもコンピュータプログラムの構造上、サービス不能状態になることも出力対策だけでは防げません。
出力対策の3原則
誤解やセキュアコーディングではない誤った解説に誤解を解く為に前置きが長くなりました。やっと本題の出力対策の3原則です。
セキュアコーディングでは全ての出力を、出力先に対して、無害であることを保障することを求めています。
出力先にはWebブラウザ、SQLデータベースなどの外部システム以外にも、複雑な処理を行う正規表現ライブラリといった、アプリケーションに内包されるライブラリも含まれます。
出力を行う場合、原則的に次の3つの無害化方法の1つ以上を適用すれば無害化できます。
1. エスケープ
XPath 1.0のように仕様として壊れている仕様以外は、出力時に無害化するエスケープ方法を定義しています。コンテクストに合った合ったエスケープを行なえば無害化できます。
よるある間違いを紹介します。
- ソート用のSQL識別子(カラム名)変数をエスケープしない。
⇒ SQL識別子は識別子用のエスケープを利用しなければならない。プリペアードクエリはこの場合は役立たずです。 - URIコンテクスト(<img src=”URI”、など)にHTMLエスケープを使う。
⇒ HTMLエスケープを使っても、インジェクション攻撃は防止できますが、正しい出力ではありません。URIコンテクスト用のエスケープが必要です。 - LDAPクエリにエスケープがない。
⇒ ”SQLではAPIを使えば大丈夫!”とする誤った教育が行われている為か、LDAPクエリAPIを使えばOKと勘違いし、LDAPクエリに必要な2種類のコンテクスト用エスケープが全くない。
PHPに於ける各種コンテクストのエスケープ方法は次のブログを参考にしてください。
2. API(エスケープを省略できるAPI)
APIを使っていれば安全!という物ではありません。LDAPクエリでよくある初歩的な間違いは、LDAPクエリAPIを使っていれば安全である、とする勘違いです。
例えば、PHPのLDAPクエリのAPIは出力の無害化を一切行いません。LDAPクエリを安全に実行するには、最低限2種類のコンテクスト用(DNとFILTER)のエスケープと後述するバリデーションを利用しなければなりません。
RubyのNetLDAPのAPIは内部的にエスケープしています。このAPIのエスケープで十分かどうか?はLDAPのエスケープ仕様とAPI実装の両方を理解している必要があります。
参考:LDAP Injection Prevention Cheat Sheet
信頼できるエスケープやパラメーター分離をAPI内部で行うAPIがある場合に、コーディング標準を作る場合はAPIを優先して使う、とするのが良いでしょう。しかし、出力の無害化を教える場合はエスケープを優先して教える必要があります。エスケープを知る≒コンテクストを知る、だからです。コンテクスト/エスケープを知らない/意識しない開発者は簡単&初歩的なミスをします。
3. バリデーション
エスケープもエスケープを省略できるAPIも使えない場合は、バリデーションするしかありません。バリデーション方法とセキュアなアプリケーション構造については次のブログを参考にしてください。
エスケープ/APIを使う前にバリデーションが必要となる場合もあります。
例えば、文字エンコーディングが妥当でないと、エスケープしても不十分だったり、何処かに保存/処理されて不具合が起きる場合があります。
コンテクストの中に別のサブコンテクストがある場合にもバリデーション(や別サブコンテクスト用のエスケープ/API)が必要になる場合があります。
OSコマンド実行のように”コマンド”と”コマンド引数”の2つのコンテクストがある場合、”コマンド”にもエスケープが利用できます。しかし、”コマンド”をエスケープしても無害化1できません。
出力時のバリデーションでも「値の正しさを保障できるのでは?」と思うかも知れません。可能ではありますが「値の論理的な正しさ」はロジックで保障する物です。出力コードにロジックバリデーションを持って来るのは理想的な設計であるとは言い難いです。
+1の出力対策の原則
既に記載の通り「出力対策だけ」では安全になりません。「出力とロジックだけ」でも不十分です。+1の対策とはセキュアコーディング第1原則の「入力バリデーション」です。入力の妥当性を保証する入力バリデーションは安全な出力にも絶対に欠かせない対策2です。
まとめ
よくある間違いに「SQLクエリを無害化するにはプリペアードクエリ/プレイスホルダを使っていれば十分!」「LDAPクエリAPIを使っているから十分!」といった勘違いがあります。
こういった間違いをしない為には、出力対策の無害化には原則として、その出力先のコンテクストに合った
- エスケープ
- API(エスケープ/バリデーションが必要ないAPI)
- バリデーション
を行わなければならない、と覚えてくと間違えなくなります。特に危険なのはAPIさえ使っていればよいという考え方です。
重要な事なので繰り返して書きます。出力対策だけではソフトウェアを安定動作させる為には不十分(対策が遅過ぎ)です。セキュアなソフトウェア構造を作るにはFail Fast原則に従ったバリデーションが欠かせません。セキュアなソフトウェア構造を作る=堅牢な境界防御を行う、です。セキュアな構造と境界防御は表裏一体です。境界防御には入り口と出口、両方の対策が必要です。よく誤解されているので注意してください。
最後に、ここでは可変長データ出力対策だけ説明しています。固定長データへの出力には以下の3つの対策を行います。
- オフセット(場所/位置)が正しい
- データの長さが正しい
- データの値/形式が妥当
Leave a Comment