バリデーション、と一言で言っても一種類/一箇所だけではありません。バリデーションには3種類のバリデーションがあります。
バリデーションは重要であるにも関わらず誤解が多い機能の筆頭だと思います。日本に限らず世界中でよくある議論に
- バリデーションはモデルで集中的に行うべきだ!
- なのでコントローラー(入力)でバリデーションなんて必要ない!
- モデル集中型バリデーション以外の方法/場所でバリデーションするのは非効率で馬鹿馬鹿しい考えだ!
があります。どこかで見た事があるような議論ですが、世界的にこのような考えの開発者が多いことは、この入力バリデーション用のPHP拡張モジュールを書いた時の議論で分かりました。1PHP開発者MLで議論したのですが、紹介したような議論をした方が少なからず居ました。少し続くとすかさず「そもそもActiveRecordパターンでないモデルも多数あるし、ActiveRecordパターンのモデルだけのバリデーションだと遅すぎ、その間に実行させる機能が悪用されるケースは山程あって、しかもそれが奥深いライブラリのどこで起きるか分らんだろ」的なツッコミがあるところは日本での議論とは異なった点です。
実際、多くのWebアプリケーションフレームワークは入力バリデーション機能をデフォルトでは持たず、アプリケーションレベルでの入力バリデーションを必須化していません。開発者が上記のような考えになっても当然と言えるかも知れません。しかし、必要な物は必要です。何故?と思った方はぜひ読み進めてください。
流石にこの時の議論ではありませんでしたが、以下の様な議論も見かけます(ました)
- 入力データはバリデーションはできない!
- どんな入力でもWebアプリは受け付けて”適切”に処理しなければならない!
- 入力バリデーションにホワイトリスト型は無理、適用できない!
- ブラックリスト型とホワイトリスト型のバリデーションは等しいセキュリティ対策!
- 入力バリデーションはソフトウェアの仕様でセキュリティ対策ではない!
- 脆弱性発生箇所を直接または近い個所で対策するのが本物のセキュリティ対策である!
全てセキュアなソフトウェア構造を作るには問題がある考え方です。最後の「入力バリデーションはソフトウェアの仕様でセキュリティ対策ではない!」とする考え方の問題点は”セキュリティ対策の定義” 2セキュリティ対策=リスク管理、にはリスクを増加させる施策も含め、定期的にレビューしなければならないです。(ISO 27000/ISMSの要求事項)リスクを増加させる施策、例えば認証にパスワードを利用など、は定期的にレビューしその時々の状況に合ったリスク廃除/軽減策をタイムリーに導入しなければならない。リスク増加要因を管理しないセキュリティ対策=リスク管理は”欠陥のある管理方法”です。 を理解していないと問題点は見えないかも知れません。
- セキュリティ対策(=リスク管理)とはリスクを変化させる全ての施策で、多くの場合はリスクを廃除/軽減させる施策だが、それに限らない。
このセキュリティ対策の定義はISO 27000/ISMSの定義をまとめたモノです。
TL;DR;
何事も原理と基本が大切です。基礎的な事ですがプログラムの基本構造と動作原理を正しく理解しておく必要があります。
入力対策と出力対策は両方必要でバリデーションはセキュアなソフトウェア構築には欠かせません。
- 原理1: コンピュータープログラムは「妥当なデータ」以外では正しく動作できない
- 原理2: 何処かでエラーになるから、ではセキュアにならない(遅すぎるエラーはNG)
アプリケーションの入り口で入力バリデーション(入力検証)をしていないアプリはセキュアでない構造です。
入り口以外に入力検証がないアプリもセキュアではない構造です。セキュアなアプリには最低限、入り口でのデータ検証と出口でのデータ無害化(エスケープ/無害化API/バリデーション)が必須です。
- プログラムは妥当なデータでしか正しく動作できない。入力バリデーションは原理的に必須。
- 出力対策は必須の物とフェイルセーフ対策の物がある。フェイルセーフ対策の場合は下層の多層防御です。そもそも”データが妥当でない場合”(=フェイルセーフ対策)のエラーは起きてはならない。当然ですが出鱈目なデータを処理するのもNG。
多層防御 3ソフトウェアに限らずセキュリティは多層で防御します。必ず必要な対策と無くても大丈夫なハズの対策(フェイルセーフ対策)の2種類がある。フェイルセーフ対策は万が一の対策であり、本来フェイルセーフ対策は動作してはならない。動作した場合はプログラムに問題がある。「動作してはならない」は「必要ない」ではない。実用的なプログラムは複雑であり失敗してしまうケースは十分にある。入力バリデーションが甘い/無いプログラムだとフェイルセーフ対策が機能してしまうことは当たり前に起きる。 は重要なのに勘違いされているソフトウェアセキュリティ要素の1つです。
バリデーションには3つの種類があります。
- 入力バリデーション – 正しく動作する為に必須(主に形式検証)
- ロジックバリデーション – 正しく動作する為に必須(主に論理検証)
- 出力バリデーション – 大半が上の2つに失敗した場合のフェイルセーフ対策(追加の対策 – 安全な特定形式のみ許可の場合)
※ 出力時のエスケープ/エスケープが不必要なAPIの利用によるデータの無害化は、必須の対策が半分、フェイルセーフ対策が半分です。
※ “入力ミスの確認”を”バリデーション”と考えたり、言ったりすると混乱の元です。”入力ミス/論理的整合性の確認エラー”は処理の継続、”あり得ないデータによるバリデーションエラー”では処理の中止、が必要なので区別する方が良いです。
※ ソフトウェア基本構造の入力処理では”あり得ないデータによるバリデーションエラー”、ロジック処理では”入力ミス/論理的整合性の確認エラー”、になります。
※ リスク分析の経験があれば自然にセキュアな構造を思い付くことも可能だと思います。
イメージ図:
{kind=link}
参考:データもコードも一文字でも間違い/不正があるのはNG
https://blog.ohgaki.net/programs-cannot-work-correctly-one-char-is-enough
なぜバリデーションがセキュリティ対策として必須なのか?
コンピューターサイエンティストのセキュリティ専門家は90年代初めからバリデーションをセキュリティ対策の最重要項目4コンピューターサイエンティストもセキュリティ問題には気付いていましたが、1988年のモリスワーム事件までほとんど気にしていませんでした。モリスワーム事件以後は対策として防御的プログラミング/セキュアプログラミングを提唱しています。にしています。なぜバリデーションなのでしょうか?
これはプログラムの基本構造、プログラムの動作原理、セキュリティ問題発生の原理から原則として導き出されています。
- プログラムの基本構造: 全てのプログラムは「入力 → 処理 → 出力」の構造を持っている
- プログラムの動作原理: コンピュータープログラムはプログラムが意図した”妥当な入力(=正しい入力&入力ミス)”のデータでしか正しく動作できない
- セキュリティ問題発生の原理: セキュリティ問題となる大半のプログラムの誤作動は、プログラマが意図しない”不正なデータ入力”によって起きる”不正な動作”が原因となっている(他の原因は設計ミスなど)
- 原則: 原理と事実より、コンピュータープログラムを正しく動作させる対策(=セキュリティ対策)として妥当性検証済みデータのみを処理させる
Tip: セキュリティ対策は”プログラムの構造”と”プログラムの機能”、両方に対して実施する必要があります。現在、ほぼ全てのWebアプリで”プログラムの構造”に合わせたセキュリティ対策が無い/不十分な状態です。
コンピューターサイエンティストはコンピューターの黎明期から”正しく動作すること保障できるプログラム”を研究してきました。プログラムを正しく動作させる為には妥当なデータが必要=データのバリデーションが必要です。コンピューターサイエンティストにとって、プログラムには”処理可能な妥当なデータであることを保障”するバリデーションが必要である、は議論する意味さえない原則となっています。
※ コンピューターサイエンティストはバリデーション”だけ”で正しく動作するプログラムであることを保障”できる”とは言っていません。詳しくはセキュアコーディングの原則を参照してください。
ソフトウェアが処理することを想定していない不正なデータを受け入れる事は、わざわざ脆弱性を含めた不具合を作る事と同じです。バリデーションエラー(”仕様の範囲”である入力ミスは別のエラー)は不正な入力なので、エラーを記録し処理を中止しなければなりません。
「バリデーション無し/不十分」=「わざわざ脆弱性を含めた不具合を作る事」である理由は、形式的検証と組み合わせ爆発を理解すれば明らかです。形式的検証と組み合わせ爆発を初耳の方は以下のブログをご覧ください。
バリデーションとは?
構造は?と進める前に用語を定義します。まずバリデーションの定義です。バリデーションの日本語訳は”確認”ですが、IT関連の場合は”検証”と訳されることが多いと思います。
1 はっきり認めること。また、そうであることをはっきりたしかめること。「安全を確認する」「生存者はまだ確認できない」
2 特定の事実や法律関係の存否について争いや疑いのあるとき、これを判断・認定する行為。当選者の決定など。
1 実際に物事に当たって調べ、仮説などを証明すること。「理論の正しさを検証する」
データをバリデーションする、とは”データの安全性/妥当性を確認”したり、”データの論理的安全性/妥当性を検証”することを意味ます。バリデーションには”誤りを検出”したり、”誤っているモノを補正/変換”するといった意味はありません。
確認/検証の結果として、誤り/不正を見つけることができますが、バリデーションの目的は正しさ/妥当性の確認/検証です。稀に”誤り検出/補正”の意味で利用されているケースを見かけますが、正しい用法ではありません。5誤り検出も広い意味では「確認」「検証」ですが、多くの場合はブラックリスト型の確認/検証です。ブラックリスト型の確認/検証は仕組的に漏れが多く確認/検証方法としては最適ではありません。確認/検証は妥当性(正しさ)を保証する為に行います。「誤り検出」も確認/検証になる場合もありますが、「誤り検出」=「確認/検証」は成り立ちません。「誤りの補正」は文字通り確認/検証になりません。
データバリデーションは
- データの”安全性”/”妥当性”を明確に確かめ、証明すること
を意味します。
この定義から、データの”安全性”/”妥当性”を証明(検証)できない方法はデータバリデーション方法としては不十分である、となります。データの”安全性”/”妥当性”を証明(検証)する方法は、データのドメイン/領域によって異なります。
データのドメイン/領域例
- 年齢 ー 0以上で普通は130以下
- 名前 ー 1文字以上で普通は100文字以下のUTF-8の印刷可能な文字で’以外のスペース/記号は含まない
- ユーザーID – 4文字以上20文字以下の半角英数字
- 注文番号 – 正の64ビット整数
- 価格 – 10円以上、100万円未満(雑貨屋などで100万以上の商品は取り扱わない)
- 電話番号 – 日本の場合、”市外局番-市内局番-番号”の形式を持つ数字と”-”で構成される文字列で最大でも13文字(携帯の最大が11桁+2つのハイフン)
- コメント – 1文字以上1000文字以下のUTF-8の印刷可能文字で改行を含む文字列
アプリケーションではデータが上記のようなドメイン/領域に当てはまるデータであるか、データの定義に従って確かめ正しいことを証明(検証)します。
データの正しさが証明(検証)できない場合、バリデーションエラーになります。不正なデータ/仕様外のデータではアプリケーションが正しく動作できないことは明らかですが、バリデーションエラーとするか?ユーザーの入力ミスとするか?はデータを送信するクライアントの仕様によって決まります。
クライアントによって送信できないデータの場合、バリデーションエラーです。アプリケーションで処理できません。処理は即時中止します。
クライアントによって送信できるデータの場合、入力ミスによるエラーです。アプリケーションロジックとして入力ミスであることを通知するために、処理を継続します。
少し脱線しますが、セキュアなプログラミング/コーディングでは入力処理と出力処理は独立した処理/対策です。独立した処理/対策とは、ゼロトラストで(何も信用しない。自分のコードでさえ信用しないで)で必要な出力対策を実施することを意味します。
3種類のバリデーション
前置きが長くなりましたが、セキュアなソフトウェア構造には3種類のバリデーションが必要です。
直ぐに3種類のバリデーションの紹介としたいのですが、その前に重要なバリデーションの方法を紹介します。ほぼ全てのWebアプリケーションがセキュリティのベストプラクティスとされるバリデーション方法を採用していないので紹介します。
バリデーションは原則として、ホワイトリスト型、で検証します。ホワイトリスト型の検証とは”正しく仕様を満たしているか?”を検証する方式です。ホワイトリスト型の検証は全てのセキュリティ標準/ガイドラインで推奨される方式です。例えば、OWASP TOP 10の第1番目の脆弱性A1「インジェクション」に対する対策の1つは、入力バリデーション、です。
Use positive or “whitelist” server-side input validation.
(OWASP TOP 10 – 2017 A1 Injectionsより)
ここで1番目のバリデーションである入力バリデーションが登場しています。
セキュリティ対策として必要なバリデーションは入力バリデーションだけではありません。ソフトウェアの粒度に関わらず、3種類のバリデーションがあります。
ざっくりソフトウェアの粒度を分類すると、アプリケーション、モジュール、関数レベルの粒度に分けられます。必要に応じてより細かく分類して考えても構いません。それぞれの粒度に合う以下の3種類のバリデーションが必要になります。
- 入力バリデーション
- ロジックバリデーション
- 出力バリデーション
ロジックバリデーションが2番目のバリデーションです。
OWASP Source Code Review Guide (ver 2. Section 7.6 Input Validation)では、このうちの「”データ”バリデーション」(=入力”データ”バリデーション=入力バリデーション)と「ビジネスバリデーション」(=”ビジネス”ロジックバリデーション=ロジックバリデーション)がソースコードに記述されているかレビューするようにと記載されています。
最後の出力バリデーションは”出力対策の3原則” のバリデーションです。出力を無害化する方法には次の3つの方法があります。
- エスケープ
- API(エスケープ/バリデーションを省略できるAPI)
- バリデーション
全ての出力はこの三原則を適用して無害化6大抵の場合は出力対策3原則の1つを利用すれば十分無害化できます。しかし、完全な無害化には出力対策の3原則を2つ以上適用しなければならない場合もあります。できます。現存するほとんどのアプリケーションは出力にバリデーションを使っていないと思います。しかし、セキュリティベストプラクティスを実践する場合は出力バリデーションが重要です。(後述)
セキュリティベストプラクティスでは入力/ロジック/出力バリデーションは一箇所で行うモノ/行えるモノではありません。十分な安全性を確保する為には多層構造でバリデーションを行います。これもOWASP Source Code Review Guideに記載されています。
具体的にはOWASP TOP 10 – A1: Injectionの対策のチェックリストとして(ver2. p. 50)
Implement multiple layers of validation.
(多層のバリデーションを実装していること)
としています。
要するにOWASP的には「適切に複数レイヤーのバリデーションが無いアプリ」は脆弱なコード/設計を持つアプリとして修正/改善対象になる、ということです。
入力/ロジック/出力バリデーション、それぞれの役割と、入力/ロジック/出力の多層のバリデーションが何故必要なのか見ていきましょう。その後にソフトウェアの粒度によって、どのようなバリデーションが必須なのか?必要なのか?省略できるのか?を見ていきます。”バリデーションエラー”と”入力ミスによるエラー”の違いも見ていきます。最後に”バリデーションエラー”はどう扱うべきなのか?を取り上げます。
その前に、バリデーションを理解する前提条件として「入力値は3種類しかない」ことを知っておく必要があります。まだの方はこちらを参考にしてください。
{kind=link}
簡単に説明すると、論理的には上記の図の3種類しか入力データはありません。この内、プログラムは正しい入力値と入力ミスの入力値”だけ”しか受け入れる必要がありません。
クライアントが送信できない不正な入力値は、そもそもプログラムは正しく動作できない上、任意コード/コマンド実行/DoSなどのセキュリティリスクを増加させるだけ、バグのリスクを増やすだけです。プログラムが正しく動作できない不正な値は全く必要ない無駄リスクなので、出来るだけ早く完全に廃除すべき、がセキュアコーディングの考え方です。
※ ”入力ミス”は不正な値ではなく、”妥当”な値なので受け入れます。バリデーションで廃除するのは上記図の赤い部分、”不正な入力値”です。
※ 一般にデータ検証にブラックリスト型の検証は利用すべきではありません。ブラックリスト型の検証はホワイトリスト型の検証に比べ脆弱で劣る方法だからです。
入力バリデーション
入力バリデーションはMVCモデルならC(コントローラー)で行うバリデーションです。プログラムで正しく処理できない、失敗する入力データがある場合、Fail Fast原則に従い入り口であるコントローラーで全ての入力データをバリデーションし検証に失敗するデータの受け入れを拒否します。7入り口でバリデーションする理由はFail Fast原則、失敗する物は早く失敗させる、もありますが、全ての入力データがバリデーションされているか?検証しやすい事も理由です
入力データには3種類しかありません。不正な入力データはプログラムで受け入れできません。プログラムは不正なデータを正しく処理できない(参考1、参考2、参考3)からです。
1234 + ‘abc’ や 1234 / 0
これらは、何をしても整数演算としては”正しくない結果”になります。唯一正しい処理と言えるのはエラーにすることです。このような不正なデータによる無効な処理がプログラムロジック中で行われないようにするのが、入力バリデーション(入力データバリデーション)です。
入力バリデーション(入力データバリデーション)はプログラムのロジックとは無関係に、データ形式として妥当な形式であることを保障する処理です。例えば、銀行口座の取引なら口座残高に関係なく、まず引き落とし額が数値であるか?検証します。8過去に銀行システムの開発に関わった時に「英字Oを数字0に変換するプログラムがあって、データの中にOがある物もあるみたいなんだよね」と聞いた事があります。流石に今のシステムにはOはないと思いますが。
よくあるアンチプラクティスはデータ形式=データ型として検証する方法です。
データ形式 ≠ データ型
です。データ型のバリデーションも重要ですが、これだけでは全く不十分です。
セキュアなコードには、パラメーターの過不足、数値なら範囲、文字列なら長さ、利用する文字、形式のバリデーションが必要です。
具体的には以下のような変換はバリデーションではありません。
(int)入力値 ー 整数型にキャストはバリデーションではない。無効な入力まで許可している。
次の検証は不適切なバリデーションです。
is_string(入力値)ー 文字列データ型であるかの確認では、入力データ検証としてほぼ意味がない。リスクを全く廃除せず、無効な入力を許可している。
Webアプリの場合、入力データはPOSTやGETで送られてくるデータだけではありません。HTTPヘッダー(クッキーもHTTPヘッダー)も入力データです。入力バリデーションでは全ての外部入力をバリデーションします。
※ 攻撃可能面管理(Attack Surface Manegement)はセキュリティ専門家には当たり前の常識ですが、今のアプリケーション設計では常識とは言えない状況です。
CWE-20は「標準入力バリデーション」を定義しています。全てのアプリケーションはCWE-20対策を実施する必要があります。
ロジックバリデーション
ロジックバリデーション(ビジネスロジックバリデーション)は名前の通り、ビジネスロジック、つまりプログラム処理の本体で行うバリデーションです。
入力バリデーションはMVCモデルならM(モデル)で行うバリデーションです。
プログラム処理の本体(ロジック)では”ロジックバリデーション”以外に、”入力ミスによるエラー処理”も行います。”ロジックバリデーション”と”入力ミスによるエラー処理”は別の処理と考えた方が解りやすいです。入力のミスのデータはプログラムにとって”妥当なデータ”だからです。
ロジックでは”状態”のバリデーションが主なバリデーションになります。”状態”は「予約日が未来の日付であること」「オプション商品が選択可能な組み合わせであること」などです。
アプリケーションレベルでの入力バリデーションが甘い/無い脆弱な構造のソフトウェア場合、本来は入力処理ですべきバリデーションをロジックですることになります。この場合、入力データには3種類しかない事を思い出してください。プログラムは不正なデータを正しく処理できない事も思い出してください
ロジックバリデーションと入力エラー処理の違い
”ロジックバリデーション”は”妥当なデータであること”(不正なデータではないこと)を保障します。
例えば、サーバー側がクライアントに送信したデータでユーザーが改変することが許されないデータ(hidden入力のデータなど)がある場合、改ざんされてはならないデータが改ざんされていないこと(無効/不正なデータでないこと)を保障9この保障にはHMACなどのハッシュ関数が利用できます。しなければなりません。
”入力ミスによるエラー処理”も妥当なデータであることを検証しますが、入力エラー処理は”アプリケーションにとっては入力として妥当なデータ(受け入れ可能なデータ)”に対して行います。
ユーザーの入力ミスで”年齢”が大きすぎる、”ふりがな”に英字が入っている等のチェックがロジックでの入力エラー処理の役割です。
同じ入力データ、例えば異常な”年齢”は、”入力ミスによるエラー処理”としてロジックで処理すべき場合、入力バリデーションで処理すべき場合、の2通りがあります。
- クライアントで”年齢”が妥当であることをバリデーションしている
↓
入力バリデーションで数値形式であること、妥当な範囲であることをチェック
※ ロジックで処理するデータではない。エラーの場合は異常なデータです。
- クライアントは”年齢”が妥当であることをバリデーションしていない
↓
ロジックで入力ミスによるエラー処理で数値形式であること、範囲をチェック
※ エラー発生時には再入力。これは通常の動作であり正常なデータです。
バリデーションすべきこと/できること、はクライアントプログラムによって変わります。
ロジックバリデーションで行う処理
ロジックバリデーションではデータの論理的整合性をチェックします。クライアントがデータの論理的整合性をチェックした上でサーバーに送信している場合、チェックする事が多くなります。
例:
- 都道府県名と郵便番号の整合性がある
- 買い物リストの商品金額、合計金額に整合性がある
- 選択した商品の依存関係に整合性がある(選べないオプションが選択されていない)
- 有効なアクセストークンがある(CSRFなど)
- 送られたメッセージとメッセージ認証コードの整合性がる(HMAC、HKDFなど)
- データベースのソート/抽出カラム名にビジネスロジックとの整合性がある
最後の「ソート/抽出カラム名にビジネスロジックとの整合性」はSQLインジェクション対策には重要です。今時は大半のSQLインジェクション脆弱性は「カラム名」(識別子)によって作られています。
繰り返しになりますが、ロジックバリデーションでは妥当なデータ(論理的に不整合がないこと、論理的検証の結果として不正なデータではないこと)をバリデーションします。クライアントが送ってこれない/送ってくるはずがないデータのバリデーション、データとハッシュ値のバリデーション、本来あるべき状態のバリデーション、などを行います。
出力バリデーション
出力バリデーションはMVCモデルならV(ビュー)レベルで行うバリデーションです。この段階でのバリデーションは遅すぎるバリデーションであり、フェイルセーフ対策です。出力バリデーションでエラーになるコードには問題があると言えます。
MVCモデルならビューとは言っても、ビューに利用するテンプレート/テンプレート変数に対する出力だけが出力バリデーションの対象ではありません。出力先が正規表現関数や自分で作った関数である場合にも、出力バリデーションが必要になります。外部システムへの出力を行わない関数/モジュールでも、リスクがある/複雑なモノ(正規表現など)に出力する前にバリデーションします。これはセキュアコーディングの原則です。
出力バリデーションは出力の無害化対策の1つとして行います。エスケープやAPIの利用により出力は無害化できますが、”正しい出力”であることは、エスケープとAPIの利用では保障できません。更にエスケープ/APIでは複数コンテクストが存在する出力先の無害化には役立たない場合もあります。
正しい出力であることを保障する必要がある場合、何らかのプログラム中の不具合など(入力/ロジックバリデーション漏れなど)によって”不正なデータ”が混入するリスクを廃除したい場合、高リスクな機能(コマンド実行/複雑は処理系への出力など)を使う場合、にはエスケープ/APIではなく出力バリデーションを行います。(組み合わせる場合も勿論あります)
出力バリデーションは正しいデータであること(少なくとも形式的には、不正なデータ形式ではないこと)をバリデーションします。
エスケープやAPIは”正しいデータ”であることを保障できませんが、利用せざるを得ない場合も多いです。これは出力時点では手遅れで、与えられたデータが”正しいデータ”であることを前提、としてエスケープやAPIを使って無害化する以外にないからです。10例えば、汎用ORMの場合、通常SQLパラメーターがどんなパラメーターであっても処理する必要があります。”年齢”に’abc’や9999999999が設定されていても、処理する必要があります。クエリエラーになるようなデータであっても、汎用ORMには”正しいデータ”であるかどうか?検証する責任が無いからです。10
出力時のバリデーションは手遅れの対策、万が一の対策、フェイルセーフ対策、です。出力時のバリデーションでエラーになるようなデータが出力処理時点であるプログラムには、入力処理またはロジック処理にバグがある事になります。
ソフトウェア粒度とバリデーション
バリデーションは全てのソフトウェアに必須ではありません。
アプリケーション、モジュール、関数 – ソフトウェアの粒度や役割によってバリデーションが必須かどうか決まります。
最近はマイクロサービスが流行っていますが、”マイクロサービス化”や”SPA化”が原因で脆弱になっているシステムが多数あります。同じバリデーションでも、アプリケーションレベルとモジュール/関数レベルでは必要性が異なることが、”マイクロサービス化”や”SPA化”で脆弱になる原因です。
※ 一般にアプリケーション内部にある関数やモジュールはアプリケーションレベルや他のソフトウェアの信頼境界でのデータバリデーションにより”保護”されいます。これらの”保護”がない状態で外部に晒すと問題起きるのは当然です。しかし、このようなケースが数えきれないので2017年版OWASP TOP 10ではA10として問題を指摘しています。
アプリケーションレベルのバリデーション
一般にアプリケーションレベルとなるソフトウェアでは3種類のバリデーション全てが必要になります。アプリケーションレベルのソフトウェアにはインターネットに公開しているマイクロサービスやRESTful APIも含まれます。
入力バリデーション
信頼できないシステムとデータをやり取りするアプリケーションには入力バリデーションは必須です。ここでもう一度、プログラムは妥当なデータでしか正しく動作できない、ことを思い出してください。
信頼できないシステム11信頼できないシステムは”クライアントソフトウェア”だけではありません。ネットワークやデバイス(OS/ハードウェアなど)が信頼できない”も”、信頼できないシステムです。から送られてくるデータは”正しく処理できる妥当なデータだけ”が送られてくるとは限りません。攻撃者が、プログラムが正しく処理できない不正なデータを送ってくるかも知れません。プログラムが受け付けるデータには3種類しかなく、受け入れ可能な正しく処理できる妥当なデータと入力ミスのデータのみ受け入れなければなりません。
再掲:入力値の種類は三種類しかない
ロジックバリデーション
ロジックレベルでのバリデーションもアプリケーションには必須です。入力処理で妥当なデータであるとバリデーションされていても、論理的には正しいデータではないケースは数えきれないくらいあります。
例えば、予約システムで施設の予約日付がクライアント側でアプリケーション仕様を満す未来であることをチェックしている場合、サーバー側には攻撃者が改ざんした過去の日付の送信してくるかも知れません。一般に入力バリデーションでは”形式的なチェックのみ”を行い、”論理的なチェック”は行いません。無効な過去の日付を廃除する処理はロジックバリデーションで行います。12入力バリデーションで過去の日付でないことをバリデーションすることも可能ですが、一般に単一責任の原則に従い、”データ形式チェックの責任”を持つ入力バリデーションでは”データ形式のチェック”のみを行います。原則なので例外として入力バリデーションで過去の日付のチェックを行う設計もあり得ます。この設計も妥当な設計です。入力バリデーションは”高いレベルのデータ型”と考えられます。クライアントで日付をチェックしている場合、”予約日”を”現在の日付けより1以上未来の日付”であるデータ型として定義しバリデーションしても構いません。
アプリケーションレベルでのロジックバリデーションを何処で、どのモジュールやクラス、関数で、実施するのか?はアプリケーション/セキュリティ設計の問題です。アプリケーション開発者の腕の見せ所です。この後の「モジュール/関数レベルのバリデーション」でもう少し詳しく解説します。
出力バリデーション
セキュアコーディング原則のアーキテクチャーで作られたアプリケーションである場合、出力バリデーションが必要となる場合は少ないです。既に入力処理でバリデーション済みであるからです。
しかし、エスケープもAPIも使えない場合には出力バリデーションが必要になります。リスクが高いevalによるスクリプト実行、読み取り/書き込みファイルパスの生成などではエスケープ/APIよりバリデーションがお薦めです。アプリケーションの場合、SQLクエリ中の識別子が変数である場合もバリデーションがお薦めです。13汎用クエリライブラリの場合、SQL識別子のバリデーションは設計としてあり得ない場合もあります。例えば、SQLの予約語や日本語文字列が識別子の場合はエスケープが必要です。バリデーションしてしまうとライブラリを利用するプログラムの拡張性を損ねてしまいます。仕様が決まっているアプリケーションならバリデーションの方が良いです。
セキュアコーディングでは原則として、入力は全てバリデーションすること、出力は全て無害化することを求めています。そして出力対策は入力対策とは”独立した対策”としています。原則に従う場合、エスケープもAPIも使えない時には、たとえ入力バリデーション済みであって出力対策としてバリデーションを行います。
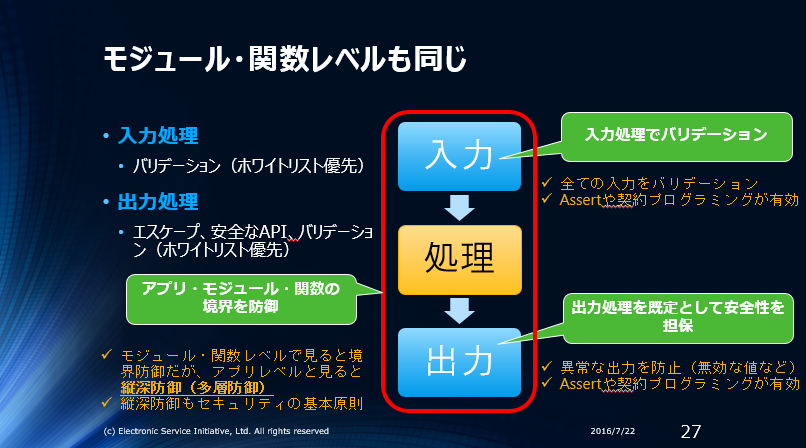
モジュール/関数レベルのバリデーション
モジュールや関数レベルでのバリデーションは、アプリケーションレベルでのバリデーションとは前提条件が全く異なります。
どのように前提条件が異なるのか?は契約プログラミング(契約による設計)を理解すると解ります。
※ 契約プログラミングでは開発時には全ての入出力と状態をバリデーションします。運用時には少数の必要な入出力と状態のバリデーションは残るように設計し、他のバリデーションは無効化されます。
入力バリデーション
モジュール/関数レベルでの変数は、アプリケーションレベルで全ての入力がバリデーション済みである、ことを前提条件にできます。この場合、モジュール/関数では入力バリデーションは必須ではありません。必須ではない、というよりも寧ろ積極的に入力バリデーションを省略することが推奨されています。
適切な契約プログラミングとユニットテストを使えば、検証済みのデータが渡されていることを保障できることが理由です。
※ 契約プログラミングでは開発時に全てのモジュール/関数で入力バリデーションを行います。運用時には逆にほどんどの入力バリデーションを無効化します。
モジュール/関数レベルではバリデーションが省略される構造を理解していないと、マイクロサービス化やRESTful APIを利用したSPA化で致命的な脆弱性を作ってしまいます。
Microservices written in node.js and Spring Boot are replacing traditional monolithic applications. Microservices come with their own security challenges including establishing trust between microservices, containers, secret management, etc. Old code never expected to be accessible from the Internet is now sitting behind an API or RESTful web service to be consumed by Single Page Applications (SPAs) and mobile applications. Architectural assumptions by the code, such as trusted callers, are no longer valid.
(太字のみ意訳:決してインターネットからアクセスされることが想定されていない、APIやシングルページアプリケーション(SAP)によって利用されるRESTful Webサービスやモバイルアプリらは、呼び出し側が信頼可能なアーキテクチャー(構造)とすること不可能です。)
2017年版 OWASP TOP 10 Release Notesより
”マイクロサービス化”や”SPA化”が原因で脆弱になる理由は”ソフトウェアの粒度”と、意識はしていないくても、”セキュリティ構造”の関係を見落していることが原因です。ほとんどのアプリケーションはバリデーションが不十分でも、薄氷の上を歩くイメージでインジェクション攻撃を防止しています。マイクロサービスやRESTful APIを安全にインターネットに公開するには、信頼できない相手からの送信されたデータであることを考慮しないと安全性を維持できません。
モノリシックなアプリケーションをマイクロサービス化/SPA化する場合、信頼できないデータを信頼できるデータにする為にバリデーションが欠かせません。アプリケーションをマイクロサービス化、RESTful API化して分割する場合、それぞれのサービス/APIの”入り口”でバリデーションしないと脆弱になります。
ロジックバリデーション
ロジックバリデーションも適切な契約プログラミングとユニットテストを使えばかなり部分を省略することも可能です。ただし、ロジックバリデーションは”ビジネスロジック”として行う物です。不用意に契約プログラミングの”省略可能なバリデーション”にしてしまわないように注意して設計する必要があります。
※ 契約プログラミングでは、入力バリデーションと同様に全ての”状態”をバリデーションします。例えば、ユーザー情報更新後に年齢がオカシナ値になっていないか?などをチェックします。運用時には大半のバリデーションは無効化されます。他の場所で”状態”はチェックされ、”正しい状態”であることが保障されているからです。
出力バリデーション
出力バリデーションも適切な契約プログラミングとユニットテストを使えばかなり部分を省略することも可能です。ただし、実際に出力を行う箇所では、エスケープやAPIだけでなく、必要な箇所ではバリデーションを行うことが必要です。
既に書きましたが、複雑なシステム/コード(正規表現など)、外部のシステムにデータを出力する場合は出力の無害化が必要です。(セキュアコーディング原則の7番目、IPA版は2番目)エスケープもAPIも使えない場合、バリデーションは必須です。
※ これも他の2つと同様に全ての出力をバリデーションしますが、ほとんどのバリデーションは運用時には無効化されます。
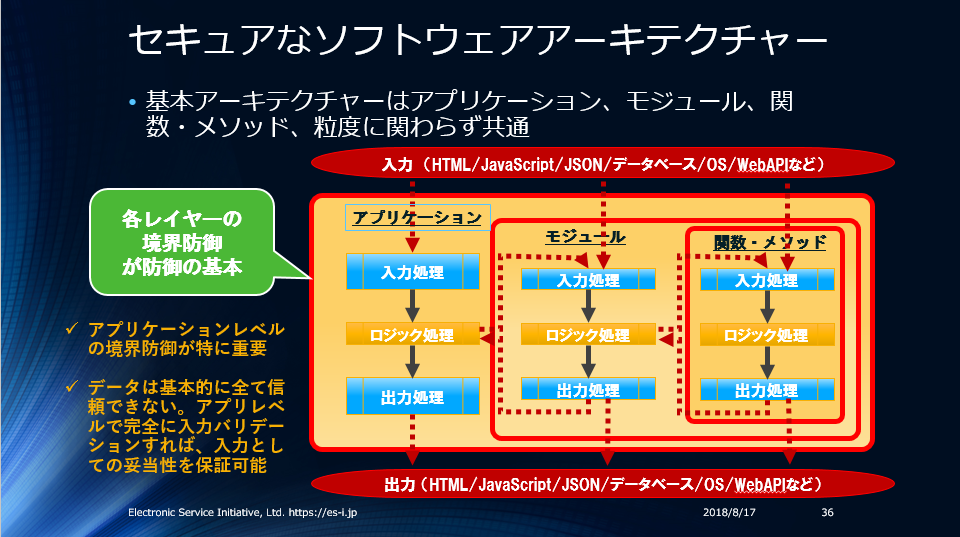
アプリケーション/モジュール/関数構造のイメージ
アプリケーション/モジュール/関数、それぞれの構造は以下のようになります。
{kind=link}
紹介してきた考え方をアプリケーションアーキテクチャーとして図にすると以下のような図になります。
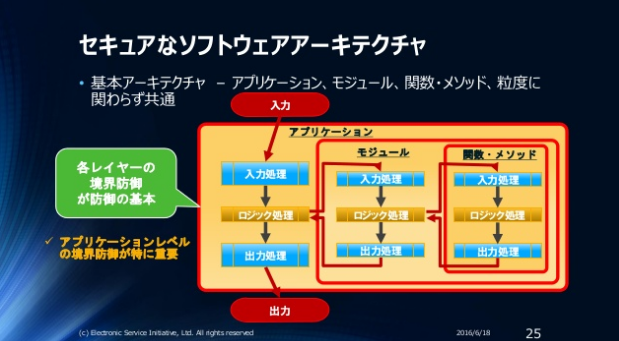{kind=link}
バリデーションエラーの扱い方
セキュアコーディング原則に則って構築されたアプリケーションの場合、バリデーションエラーには”ユーザーからの入力ミス”は含めません。入力ミスはセキュアコーディングでいうバリデーションとは別の取り扱いをします。3種類の入力のうち、バリデーションエラーになるデータはアプリケーションが受け入れ不可能な不正なデータだけです。
セキュアコーディング原則のアーキテクチャーなら、不正なデータが検出された場合は2種類の可能性しかありません。
- プログラムのバグ(クライアントプログラムのバグも含む)
- 攻撃者による攻撃
どちらも”対応”が必要な問題です。
2017年版OWASP TOP 10からA10「不十分なログとモニタリング」が追加されました。攻撃者による攻撃をログしない、モニタリングしない、対応しないアプリケーションは脆弱なアプリケーションであるとしています。
バリデーションエラーが発生した場合、以下の対応が必要です。
- ログを取る(無視しない!)
- エラーを監視する
- 可能な対応を行う
バリデーションではサニタイジング14汚れた/壊れたデータを綺麗にして使える形にすること。14は行いません。検証だけ行い、データの書き変えは行いません。アプリケーションはバリデーションエラーを無視せず、エラーとして記録し、”処理を中止した上で”可能な対応を行います。
プログラムは不正なデータでは正しく動作できないことを、ここでもう一度思い出してください。
バリデーションエラーが発生した場合、通常の処理は行いません。行わないというより、行なえません。このためログを取った後に必ず処理を停止させます。その上で可能な対応を行います。
可能な対応の例:
- 警告レスポンスを返す
- セッションを破棄する
- ユーザーを凍結する
- IPアドレスをブロックする
- システムの一部/全部を停止する
- 管理者に警告を送信する
まとめ
ここではあるべき入力バリデーションの仕様/方法は紹介しませんでした。具体的なバリデーション方法も重要です。世の中にあるバリデーションコードのほとんどがISO 27000で要求している安全性の高い方法に従っていません。
冒頭に挙げた議論です。
- バリデーションはモデルで集中的に行うべきだ!
- なのでコントローラー(入力)でバリデーションなんて必要ない!
- モデル集中型バリデーション以外の方法/場所でバリデーションするのは非効率で馬鹿馬鹿しい考えだ!
- ブラックリスト型とホワイトリスト型のバリデーションは等しいセキュリティ対策!
- 入力バリデーションはソフトウェアの仕様でセキュリティ対策ではない!
データのバリデーションは”ホワイトリスト型”かつ多層構造で実施しなければならないです。ホワイトリストに適合しないデータはFail Fastの原則に従い出来る限り早く廃除しなければならないです。契約プログラミングを理解すると集中型バリデーションが非効果的かつ非効率であることも解ります。15Railsや類似のアプリケーションフレームワークのモデルの場合、データのバリデーションはデータ保存時に行われます。データ保存時にバリデーションするのはDBサーバーのCHECK制約やトリガーで検証することと同じで検証が遅すぎます。データ保存の前に様々な処理が行われるのがある程度の規模のアプリケーションの当たり前です。またDOAアーキテクチャー”だけ”で良いならまだマシですが、データベースを利用しない処理にはActiveRecordのバリデーションはありません。これはRaildアプリに於て二番目に多い脆弱性です。(一番目はHTMLヘルパー。単純に必要なエスケープをしないで.html_safeを付ける開発者が多い)「常にエスケープを考える」を意識していない事がこの状況の原因でしょう。15ブラックリスト型のセキュリティは構造的に脆弱な構造です。入力バリデーションはソフトウェア構造上、最も重要なセキュリティ対策(リスク廃除策/緩和策)です。
ごく単純なプログラムでない限り、普通の人間にはフェイルファーストによる入力バリデーションなしでマトモな管理(≒マトモなプログラム作り)は不可能です。
入力バリデーション”だけ”ではセキュアなアプリケーションは作れませんが、入力バリデーション”なし”ではセキュアなアプリケーションは作れません。「セキュアなアプリケーション」とは「インジェクション攻撃できないアプリケーション」ではなく、「正しく動作するアプリケーション」です。
バリデーションをどこで、どのように行うか?はソフトウェアのセキュリティ設計そのものと言って良いくらい重要なセキュリティ設計要素です。16契約プログラミング(契約による設計)はValidation Everywhere!と言えるくらい、バリデーションだらけ、のプログラムを作ります。バリデーションによってプログラムの正しい実行と安全性を保障しています。契約プログラミング(契約による設計)を行った場合、運用時に、どこに、どのようなバリデーションを残すのか?はセキュリティ設計その物です。(+出力の無害化が必要)
アプリケーション設計者にバリデーション設計が任されているとはいえ、必須のバリデーションもあります。
- アプリケーションレベル[^microservice-and-web-api]の入力バリデーションは、論理的に効果的/効率的なアプリケーション構築には必須(原理:妥当な入力以外では、プログラムは正しく動作しない)
- 出力バリデーションが必要なケース、つまりエスケープもAPIも使えないケース、ではバリデーションが必要(原則:出力対策は入力対策とは独立。出力は無害化してから行う)
1番目はプログラム処理の原理から導き出せる必要条件です。2番目はセキュアコーディングの原則から導き出せる必要条件です。
ここで紹介した考え方はコンピューターサイエンスを研究するセキュリティ専門家が90年代初めから提唱している、セキュアなコードを書く技術です。まだの方でも大丈夫、これから実践しましょう!
このエントリではセキュアなソフトウェアのアーキテクチャーの全貌は解説していません。これはセキュアコーディング原則から読み取ることができます。今のソフトウェアの入力処理はセキュアコーディングの第一原則、CWE/SANS TOP 25の第一の対策である入力バリデーションが非常に弱い/ほぼ無い状態で、2017年版OWASP TOP 10のA10「不十分なログとモニタリング」対策もほぼ無いのが現状です。バリデーションはアドホックに追加できます。ソフトウェア全体の構造/アーキテクチャーの変更が必要ないことは幸いですが、多くのソフトウェアでセキュリティ構造/アーキテクチャーから見直しが必要となっています。
参考:
ITシステムのバリデーション構造を適切に定義するには4種類の信頼境界があることを理解するのが早道です。
CWE-20はMITRE(米国のIPAのような組織)が「恐ろしく/怪物的に効果的な対策」とするNo 1です。
7PK(7つの悪質な領域)とは業界標準のソフトウェアセキュリティ分類です。1番目の悪質な領域は「入力バリデーションと表現」です。
バリデーションはセキュアコーディング/セキュアプログラミングで最も重要とされるセキュリティ機能です。その歴史は短くありません。
セキュアコーディングを実施する際の原則をCERTは公開しています。セキュアコーディング/セキュアプログラミングでは欠かせない基本原則です。
攻撃者がどうやって「アプリケーション奥深くの内部の脆弱性」まで攻撃できるのか?してくるのか?その仕組みを知れば対策も解ります。
ソフトウェア以外でも、どのようなバリデーションを行なえば良いのか?すべきなのか?基本となる考え方は同じです。「ゼロトラスト」(何も信頼しない)と「フェイルファースト」(失敗するモノはできる限り早く失敗させる)を基本とします。
適切なバリデーション構造を作るには「リスク分析」が欠かせません。「リスク分析」なしで問題が起こった箇所を場当たりに対策しても、セキュアなソフトウェアを作ることは難しいです。
おまけ
数年前に「SQLインジェクション対策にエスケープは欠かせない」と当たり前のことを書いたところ、「エスケープは要らない」と誤解していた方が多くいました。エスケープはバリデーションと同じくらい、重要なセキュリティ対策です。しかし、エスケープもバリデーションと同じくらい誤解されているケースが多いようです。
SQLインジェクション対策にエスケープが欠かせない、は好みや方法論の話ではなく、現在のAPIや仕組みから導き出せる”原理”です。原理は原則と異り、例外はありません。17原理はルールが変わらない限り例外はありません。例えば、ニュートン力学は”通常の状態”の物理法則の原理として例外なく適用されます。”ルールが変わる状態/状況”では相対性理論や量子力学といった別の原理が適用されます。コンピュータープログラムが正しく動作する為には正しい/妥当なデータが必須である、というルールが変わるような状態/状況がない限り、この原則は変わりません。 原理的に不正な入力データでプログラムは正しく動作できない、と同じく”原理”は曲げられません。
原理と原則は似ていますが根本的な部分で異なります。「SQLにエスケープは要らない」という誤った結論を導き出した方達は、恐らく原理的に必要なモノなのか、原則として必要なモノなのか、区別ができていなかったのではないか?と今になって思います。
何度かソフトウェアセキュリティの基礎・基本を誤解している外国人とも議論したことがあります。これは最近あった議論の1つです。
- 1PHP開発者MLで議論したのですが、紹介したような議論をした方が少なからず居ました。少し続くとすかさず「そもそもActiveRecordパターンでないモデルも多数あるし、ActiveRecordパターンのモデルだけのバリデーションだと遅すぎ、その間に実行させる機能が悪用されるケースは山程あって、しかもそれが奥深いライブラリのどこで起きるか分らんだろ」的なツッコミがあるところは日本での議論とは異なった点です。
- 2セキュリティ対策=リスク管理、にはリスクを増加させる施策も含め、定期的にレビューしなければならないです。(ISO 27000/ISMSの要求事項)リスクを増加させる施策、例えば認証にパスワードを利用など、は定期的にレビューしその時々の状況に合ったリスク廃除/軽減策をタイムリーに導入しなければならない。リスク増加要因を管理しないセキュリティ対策=リスク管理は”欠陥のある管理方法”です。
- 3ソフトウェアに限らずセキュリティは多層で防御します。必ず必要な対策と無くても大丈夫なハズの対策(フェイルセーフ対策)の2種類がある。フェイルセーフ対策は万が一の対策であり、本来フェイルセーフ対策は動作してはならない。動作した場合はプログラムに問題がある。「動作してはならない」は「必要ない」ではない。実用的なプログラムは複雑であり失敗してしまうケースは十分にある。入力バリデーションが甘い/無いプログラムだとフェイルセーフ対策が機能してしまうことは当たり前に起きる。
- 4コンピューターサイエンティストもセキュリティ問題には気付いていましたが、1988年のモリスワーム事件までほとんど気にしていませんでした。モリスワーム事件以後は対策として防御的プログラミング/セキュアプログラミングを提唱しています。
- 5誤り検出も広い意味では「確認」「検証」ですが、多くの場合はブラックリスト型の確認/検証です。ブラックリスト型の確認/検証は仕組的に漏れが多く確認/検証方法としては最適ではありません。確認/検証は妥当性(正しさ)を保証する為に行います。「誤り検出」も確認/検証になる場合もありますが、「誤り検出」=「確認/検証」は成り立ちません。「誤りの補正」は文字通り確認/検証になりません。
- 6大抵の場合は出力対策3原則の1つを利用すれば十分無害化できます。しかし、完全な無害化には出力対策の3原則を2つ以上適用しなければならない場合もあります。
- 7入り口でバリデーションする理由はFail Fast原則、失敗する物は早く失敗させる、もありますが、全ての入力データがバリデーションされているか?検証しやすい事も理由です
- 8過去に銀行システムの開発に関わった時に「英字Oを数字0に変換するプログラムがあって、データの中にOがある物もあるみたいなんだよね」と聞いた事があります。流石に今のシステムにはOはないと思いますが。
- 9この保障にはHMACなどのハッシュ関数が利用できます。
- 10例えば、汎用ORMの場合、通常SQLパラメーターがどんなパラメーターであっても処理する必要があります。”年齢”に’abc’や9999999999が設定されていても、処理する必要があります。クエリエラーになるようなデータであっても、汎用ORMには”正しいデータ”であるかどうか?検証する責任が無いからです。
- 11信頼できないシステムは”クライアントソフトウェア”だけではありません。ネットワークやデバイス(OS/ハードウェアなど)が信頼できない”も”、信頼できないシステムです。
- 12入力バリデーションで過去の日付でないことをバリデーションすることも可能ですが、一般に単一責任の原則に従い、”データ形式チェックの責任”を持つ入力バリデーションでは”データ形式のチェック”のみを行います。原則なので例外として入力バリデーションで過去の日付のチェックを行う設計もあり得ます。この設計も妥当な設計です。入力バリデーションは”高いレベルのデータ型”と考えられます。クライアントで日付をチェックしている場合、”予約日”を”現在の日付けより1以上未来の日付”であるデータ型として定義しバリデーションしても構いません。
- 13汎用クエリライブラリの場合、SQL識別子のバリデーションは設計としてあり得ない場合もあります。例えば、SQLの予約語や日本語文字列が識別子の場合はエスケープが必要です。バリデーションしてしまうとライブラリを利用するプログラムの拡張性を損ねてしまいます。仕様が決まっているアプリケーションならバリデーションの方が良いです。
- 14汚れた/壊れたデータを綺麗にして使える形にすること。
- 15Railsや類似のアプリケーションフレームワークのモデルの場合、データのバリデーションはデータ保存時に行われます。データ保存時にバリデーションするのはDBサーバーのCHECK制約やトリガーで検証することと同じで検証が遅すぎます。データ保存の前に様々な処理が行われるのがある程度の規模のアプリケーションの当たり前です。またDOAアーキテクチャー”だけ”で良いならまだマシですが、データベースを利用しない処理にはActiveRecordのバリデーションはありません。これはRaildアプリに於て二番目に多い脆弱性です。(一番目はHTMLヘルパー。単純に必要なエスケープをしないで.html_safeを付ける開発者が多い)「常にエスケープを考える」を意識していない事がこの状況の原因でしょう。
- 16契約プログラミング(契約による設計)はValidation Everywhere!と言えるくらい、バリデーションだらけ、のプログラムを作ります。バリデーションによってプログラムの正しい実行と安全性を保障しています。契約プログラミング(契約による設計)を行った場合、運用時に、どこに、どのようなバリデーションを残すのか?はセキュリティ設計その物です。(+出力の無害化が必要)
- 17原理はルールが変わらない限り例外はありません。例えば、ニュートン力学は”通常の状態”の物理法則の原理として例外なく適用されます。”ルールが変わる状態/状況”では相対性理論や量子力学といった別の原理が適用されます。コンピュータープログラムが正しく動作する為には正しい/妥当なデータが必須である、というルールが変わるような状態/状況がない限り、この原則は変わりません。
Leave a Comment